【论文阅读】Landmark Assisted CycleGAN for Cartoon Face Generation
Landmark Assisted CycleGAN for Cartoon Face Generation
- Abstract
- Introduction
- Our Method
- Review of CycleGAN
- Cartoon Face Landmark Assisted CycleGAN
- Landmark Consistency Loss
- Landmark Matched Global Discriminator
- Landmark Guided Local Discriminator
- Network Training
- Two Stage Training
- Training setting
Abstract
在本文中,我们通过使用真实面孔和卡通面孔之间的不成对训练数据来生成人的卡通面孔。此任务的主要挑战在于,真实和卡通面孔的结构位于两个不同的域中,它们的外观彼此差异很大。没有明确的对应关系,就很难生成可以捕捉人的基本面部特征的高质量卡通脸。为了解决这个问题,本文提出了Landmark Assisted CycleGAN,其利用Face Landmark来定义Landmark一致性损失并指导在CycleGAN中训练局部判别器。为了在Landmarks中实现结构一致性,本文利用条件生成器和鉴别器。本文的方法能够生成高质量的卡通面孔,甚至与艺术家绘制的面孔没有区别,并且可以极大地改善现有技术。
Introduction
卡通脸出现在动画,漫画和游戏中。 它们被广泛用作社交媒体平台(如Facebook和Instagram)中的个人资料图片。绘制卡通脸需要大量劳动。 它不仅需要专业技能,而且很难像每个人的独特外表一样。在本文中,我们旨在自动为任何人生成相似的卡通面孔。 我们将此问题视为图像到图像的翻译任务。 但是,我们使用的是卡通和真实面孔之间未配对的训练数据。

如图1所示,在“从人脸到卡通”转换中,我们发现直接应用CycleGAN不能产生令人满意的结果。这是因为两个域的几何结构彼此非常不同,这导致结构不匹配,从而导致严重的失真和视觉伪影。为了解决几何不一致问题,我们建议将更多空间结构信息纳入当前框架。 更具体地,Landmark信息是缓解该问题的有效稀疏空间约束,并且可以采用多种策略来解决几何问题。
因此,我们提出了Landmark Assisted CycleGAN,其中将真实和卡通面部的面部标记(Landmark)与真实和卡通面部的原始图像结合使用。两个域中的显式结构约束确保了语义属性,例如 即使没有成对的训练数据,眼睛,鼻子和嘴巴仍然可以正确匹配。这有效地避免了所生成的卡通图像中面部结构的失真。此外,人脸标志可用于定义局部判别器,这进一步指导了生成器的训练,以使更多的注意力集中在重要的人脸特征上,从而在视觉上产生更合理的结果。
本文的主要贡献如下:
- 我们提出了一个landmark assisted CycleGAN,用不成对的训练数据将真实面孔转换为卡通面孔。与原始的CycleGAN相比,我们的方法产生的卡通人脸的质量明显更高;
- 我们引入了landmark一致性损失,可以有效解决未配对训练数据之间结构不匹配的问题;
- 我们使用全局和局部判别器来显著提高生成的卡通人脸的质量;
- 我们用两种卡通风格建立一个新的数据集。 该数据集分别包含2125个Bitmoji样式的样本和17,920个动漫面孔样式的图像,并且为这两种样式标注了相应的landmarks。
Our Method
Review of CycleGAN


在本文中,根据等式(3),其中X和Y分别表示真实和卡通脸部区域,我们首先介绍新的landmark assisted cycleGAN,该循环由三个主要部分组成,用于加强landmark一致性, 以landmark为条件,并以landmark为导向进行区分。 然后我们描述我们的具体训练策略。 我们的框架概述如下图所示。
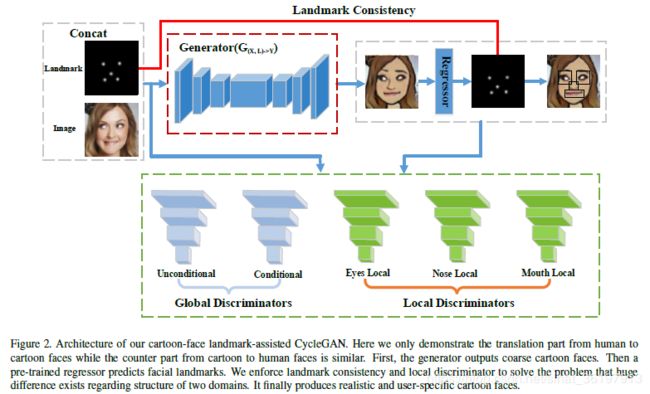
Cartoon Face Landmark Assisted CycleGAN
我们的Landmark assisted部分包括三个组成部分,即landmark一致性损失,landmarkmatched的全局判别器和landmark-guided的局部判别器。
Landmark Consistency Loss

注意5-channel的意思是每个channel代表一个landmark点,这样做不会丢失对应点的信息,只要每个channe做损失即可。如果在一张图中会有可能丢失对=对应点的信息。在等式(4)的约束下,我们使不同域中的图像呈现出紧密的面部结构。
Landmark Matched Global Discriminator


简单解释一下,就是往条件判别器中输入的包括:卡通人脸和对应landmark,生成的卡通人脸和真实人脸对应的landmark,croped的卡通人脸和与之不匹配的landmark。分别是real sample,fake sample,fake sample。最后一组输入的作用是:将具有相应的不匹配landmark heat map的卡通人脸添加为额外的假样本,以强制生成器生成更好的匹配卡通人脸,否则辨别器可能会认为landmark不匹配对也是真实样本。
Landmark Guided Local Discriminator
为了给出两个域之间的显式结构约束,我们分别在眼睛,鼻子和嘴巴上引入了三个局部判别器。对抗损失定义如下:
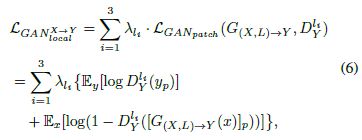
其中, y p y_{p} yp表示卡通人脸的local patch, G [ ∗ ] p G[*]_{p} G[∗]p表示生成的卡通人脸的local patch。生成器输出粗糙的卡通脸。 然后,通过预先训练的卡通人脸回归器获得预测的人脸标志。
借助预测的landmarks提供的坐标,我们可以裁剪局部patch(眼睛,鼻子和嘴巴),以作为局部判别器的输入。特别是,我们将左右眼的patch连接在一起,以便网络可以为其学习相似的大小和颜色。
Network Training
Two Stage Training
Stage I:首先,我们在不使用局部判别器的情况下训练我们的框架,以获得粗略的结果。在这个阶段,我们利用landmark一致性损失训练涉及两个方向的生成器和全局判别器。此阶段需要进行大约10万次迭代,网络会学习生成一个粗略的结果。
Stage II:由于我们已经有了一个粗略但合理的结果,因此我们使用预训练的landmark预测网络来根据粗略结果预测面部landmarks。利用估计的坐标,我们提取局部patch并将其输入到局部判别器中。 最后,我们获得了更好的结果。
Training setting
Cartoon Landmark Regressor Training:在训练landmark assisted CycleGAN之前,我们先对各个领域的两个landmark regressor进行预训练。我们采用U-Net架构,该架构将来自不同域的图像作为输入,并输出5通道热图作为面部标志的预测分数。我们对其进行了80K迭代训练。
Local Patches Extraction:在128×128的图像中,眼睛部分裁剪出32×32,鼻子部分裁剪出28×24,嘴巴部分裁剪出23×40。因此,我们总共裁剪了4个patch(两个眼睛的patch),但是将这两个眼睛的patch合并为一个以进行区分。
Hyper-Parameters Setting:batch size是1,学习率2e-4并且逐渐衰减, λ g \lambda_{g} λg是对抗损失的超参数设为0.5, λ g c \lambda_{gc} λgc是Landmark Consistency Loss的超参数设为0.5, λ l o c a l \lambda_{local} λlocal是局部判别器的超参数设为0.3, λ l m \lambda_{lm} λlm是Landmark Matched Global Discriminator的超参数设为100, λ c y c \lambda_{cyc} λcyc是循环一致性损失的超参数设为10。