基于yolo的人脸检测与人脸对齐
前言
YOLO(You Only Look Once)是一种基于深度神经网络的对象识别和定位算法,yolo将对象定位作为回归问题求解,在one-stage中实现对象定位与识别,其最大的特点就是快!快!快!
既然yolo本来就是通过回归的方法对对象定位,并与此同时对对象进行分类。那我们很容易想到yolo在做对象定位的同时可以对对象的特征点进行回归,最常见的用例是人脸检测与人脸对齐同步完成。
将人脸检测和人脸对齐同步完成,mtcnn已经做了类型的事情:
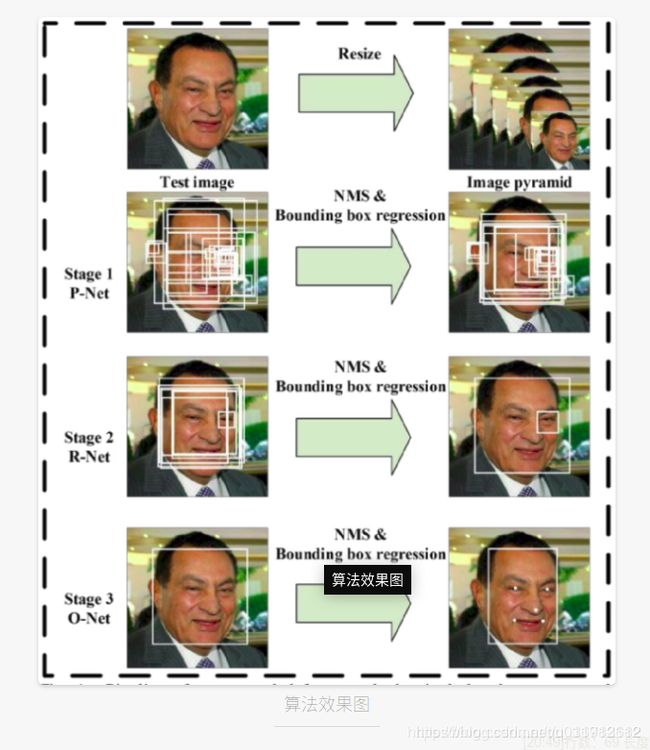
由图可见,mtcnn使用了三个卷积神经网络实现了人脸检测和人脸对齐,而使用yolo,我们将只用一个卷积神经网络同时实现人脸检测和人脸对齐:

我们将去掉yolo的分类逻辑,加入回归特征点的逻辑。
为了更好的回归,我们需要将基于图像左上角的坐标转变为基于矩形框中心的坐标。
tx = (pred_x - centet_x)*2/w
ty = (pred_y - centet_y)*2/h
tx,ty为最后的基于预测框中心的坐标
centet_x,centet_y为预测框的中心坐标
w,h为预测狂的宽和高。
pred_x,pred_y为神经网络输出的预测坐标。
经过如上处理,tx,ty应该在[-1,1]区间才行,所以,我们需要对输出进行限制。只需要让输出通过tanh激活函数即可。
pred_x = tanh(out_x)
pred_y = tanh(out_y)
out_x,out_y为为神经网络输出的未经激活的坐标。
代码如下:
static float delta_face_landmars(box fbox, float *truth, float *pred, float *delta, int index, int w, int h, int stride, float scale)
{
int i;
float diff = 0;
float data[10];
five_point(truth,data);
for(i=0;i<5;++i){
float tx = 2*(data[i*2] - fbox.x)/fbox.w;
float ty = 2*(data[i*2+1] - fbox.y)/fbox.h;
//printf("tx=%f,ty=%f,box: %f,%f,%f,%f,truth: %f,%f\n",tx,ty,fbox.x,fbox.y,fbox.w,fbox.h,truth[i*2],truth[i*2+1]);
delta[index + (i*2)*stride] = scale*(tx - pred[index + (i*2)*stride]);
delta[index + (i*2+1)*stride] = scale*(ty - pred[index + (i*2+1)*stride]);
diff += 0.5*delta[index + (i*2)*stride]*delta[index + (i*2)*stride] + 0.5*delta[index + (i*2+1)*stride]*delta[index + (i*2+1)*stride];
}
return diff;
}有了以上的准备,我们可以开始训练我们的神经网络了。
模型选择
但是yolov2太过于庞大,我的电脑根本跑不了,yolo tiny可以跑,但是我并没有选择,yolo tiny模型,而是选择了vgg16中的13个卷积层做特征提取:
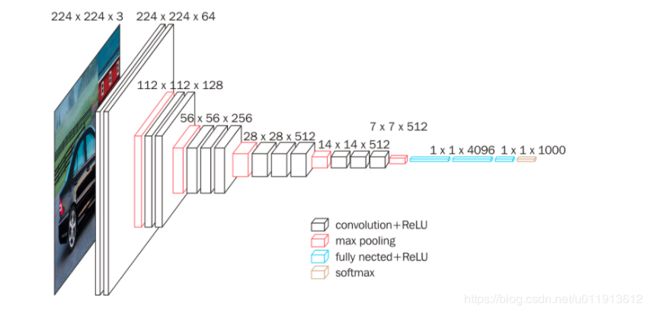
三个全连接层使用1*1的卷继融合为n*(4+1+10)个channel,n为每个cell预测几个矩形框。
最终的模型如下:
layer filters size input output
0 conv 64 3 x 3 / 1 224 x 224 x 3 -> 224 x 224 x 64 0.173 BFLOPs
1 conv 64 3 x 3 / 1 224 x 224 x 64 -> 224 x 224 x 64 3.699 BFLOPs
2 max 2 x 2 / 2 224 x 224 x 64 -> 112 x 112 x 64
3 conv 128 3 x 3 / 1 112 x 112 x 64 -> 112 x 112 x 128 1.850 BFLOPs
4 conv 128 3 x 3 / 1 112 x 112 x 128 -> 112 x 112 x 128 3.699 BFLOPs
5 max 2 x 2 / 2 112 x 112 x 128 -> 56 x 56 x 128
6 conv 256 3 x 3 / 1 56 x 56 x 128 -> 56 x 56 x 256 1.850 BFLOPs
7 conv 256 3 x 3 / 1 56 x 56 x 256 -> 56 x 56 x 256 3.699 BFLOPs
8 conv 256 3 x 3 / 1 56 x 56 x 256 -> 56 x 56 x 256 3.699 BFLOPs
9 max 2 x 2 / 2 56 x 56 x 256 -> 28 x 28 x 256
10 conv 512 3 x 3 / 1 28 x 28 x 256 -> 28 x 28 x 512 1.850 BFLOPs
11 conv 512 3 x 3 / 1 28 x 28 x 512 -> 28 x 28 x 512 3.699 BFLOPs
12 conv 512 3 x 3 / 1 28 x 28 x 512 -> 28 x 28 x 512 3.699 BFLOPs
13 max 2 x 2 / 2 28 x 28 x 512 -> 14 x 14 x 512
14 conv 512 3 x 3 / 1 14 x 14 x 512 -> 14 x 14 x 512 0.925 BFLOPs
15 conv 512 3 x 3 / 1 14 x 14 x 512 -> 14 x 14 x 512 0.925 BFLOPs
16 conv 512 3 x 3 / 1 14 x 14 x 512 -> 14 x 14 x 512 0.925 BFLOPs
17 max 2 x 2 / 2 14 x 14 x 512 -> 7 x 7 x 512
18 conv 15 1 x 1 / 1 7 x 7 x 512 -> 7 x 7 x 15 0.001 BFLOPs
19 face_aliment数据集的选取
我使用的是helen数据集,训练集共有2000副图片,每张图片标注了一个人脸。测试集共有330副图片。
官方实例:

helen数据集中,每个人脸标注了了68个点。一开始我也是壮志雄心,想在检测的同时回归68个特征点,可是结果是非常失败的。loss根本不收敛。为此,我从68个点中挑选了5个特征点,分别是左眼、右眼、鼻尖、左嘴角、右嘴角。
训练
我的笔记本带的显卡参数如下:
1050 max-q显卡,训练了超过8个小时......
可能模型还是训练不是很充分,人脸检测的效果非常好,但是人脸对齐的效果一般。
以下数据都来自helen的test set。



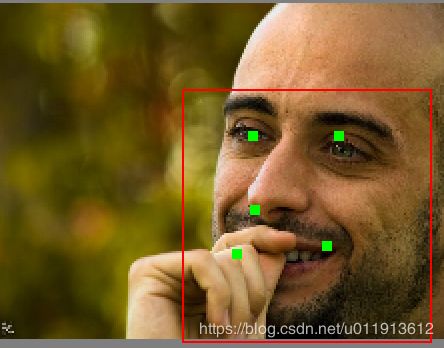
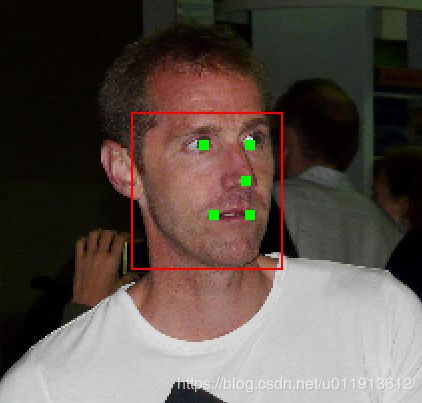



也有一些是非常失败的,比如:



源码解析
我fork了darknet的源码,并通过修改源码实现了以上实验。源码地址:
https://github.com/sunnythree/darknet
训练:
./darknet face_aliment train cfg/face_aliment.cfg
测试:
./darknet face_aliment test cfg/face_aliment.cfg model/face_aliment.weights