B+树原理以及Java代码实现
最初查找二叉树,由于树的高度会随着有序序列输入而急剧增长,后来出现平衡二叉树,红黑树。B树可以海量数据的快速查询检索,B树主要分为B树(B-树),B+树,B*树等。
B树(B-树)
M路搜索树,参数M定义节点的分支个数;
对于根节点孩子数目为[2,M],对于其余节点孩子数目为[M/2,M];
每个节点含有关键字属性,至少M/2-1 至少M-1;关键字个数=孩子个数-1;
节点有两种类型:
叶子节点 处于同一层
非叶子结点 关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];即关键字时有序的;孩子指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;

关键字集合分布在整颗树中;任何一个关键字出现且只出现在一个结点中;搜索有可能在非叶子结点结束;其搜索性能等价于在关键字全集内做一次二分查找;
B+树
对于B树的改进,每个节点具有关键字以及孩子指针属性:
非叶子结点的子树指针与关键字个数相同;
非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
为所有叶子结点增加一个链指针;
所有关键字都在叶子结点出现;
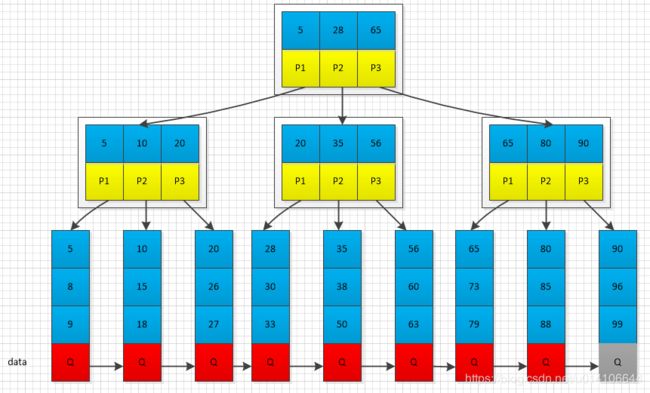
所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;不可能在非叶子结点命中;非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;更适合文件索引系统;
B*树
B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针;
B*树定义非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2);
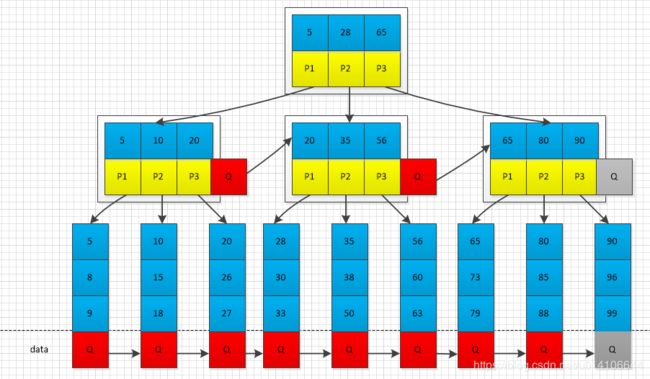
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;B*树分配新结点的概率比B+树要低,空间使用率更高;
B+树Java代码实现
实现B+的构造,插入以及查询方法
定义B+树节点关键字以及孩子指针数据结构
定义B+树参数M
对于每个节点 孩子指针利用Entry[M]来表示,m表示关键字的个数;Entry表示具体的关键字信息 Key Value以及Next指针
public class BTree, Value> {
//参数M 定义每个节点的链接数
private static final int M = 4;
private Node root;
//树的高度 最底层为0 表示外部节点 根具有最大高度
private int height;
//键值对总数
private int n;
//节点数据结构定义
private static final class Node{
//值的数量
private int m;
private Entry[] children = new Entry[M];
private Node(int k){
m = k;
}
}
//节点内部每个数据项定义
private static class Entry{
private Comparable key;
private final Object val;
//下一个节点
private Node next;
public Entry(Comparable key, Object val, Node next){
this.key = key;
this.val = val;
this.next = next;
}
@Override
public String toString() {
StringBuilder builder = new StringBuilder();
builder.append("Entry [key=");
builder.append(key);
builder.append("]");
return builder.toString();
}
} 查询方法
根据B+树定义,非叶子结点存储索引信息,叶子结点存储数据信息,利用height来判断当前是哪一层,如果height=0说明,当前节点为叶子结点,对于叶子结点,则执行顺序查找即可;如果当前节点为非叶子节点,则查找key在当前节点的哪一个孩子指针中,如果key大于当前节点所有关键字即j==m-1 如果key小于某个关键字j+1 则说明key位于j孩子指针中。
public Value get(Key key){
return search(root, key, height);
}
private Value search(Node x, Key key, int ht) {
Entry[] children = x.children;
//外部节点 这里使用顺序查找
//如果M很大 可以改成二分查找
if(ht == 0){
for(int j=0; j插入方法
利用递归思想,insert实现在某个节点中插入数据,如果当前节点为叶子结点,则找到待插入的位置j,将j以后数据后移一位,将当前数据插入,插入之后如果当前节点已满,则将当前节点的后M/2个元素产生一个新节点返回;如果当前节点为非叶子节点,找到待插入数据位于哪一个孩子节点中,递归调用insert方法,如果返回值非空,则说明下一层插入时,出现节点分裂,将新节点指向父节点;
public void put(Key key, Value val){
//插入后的节点 如果节点分裂,则返回分裂后产生的新节点
Node u = insert(root, key, val, height);
n++;
//根节点没有分裂 直接返回
if(u == null) return;
//分裂根节点
Node t = new Node(2);
//旧根节点第一个孩子 新分裂节点
t.children[0] = new Entry(root.children[0].key, null, root);
t.children[1] = new Entry(u.children[0].key, null, u);
root = t;
height++;
}
private Node insert(Node h, Key key, Value val, int ht) {
int j;
//新建待插入数据数据项
Entry t = new Entry(key, val, null);
// 外部节点 找到带插入的节点位置j
if(ht == 0){
for(j=0; jj; i++){
h.children[i] = h.children[i-1];
}
System.out.println(j + t.toString());
h.children[j] = t;
h.m++;
if(h.m < M) return null;
//如果节点已满 则执行分类操作
else return split(h);
}
private Node split(Node h) {
//将已满节点h的后一般M/2节点分裂到新节点并返回
Node t = new Node(M/2);
h.m = M / 2;
for(int j=0; j 节点分裂过程
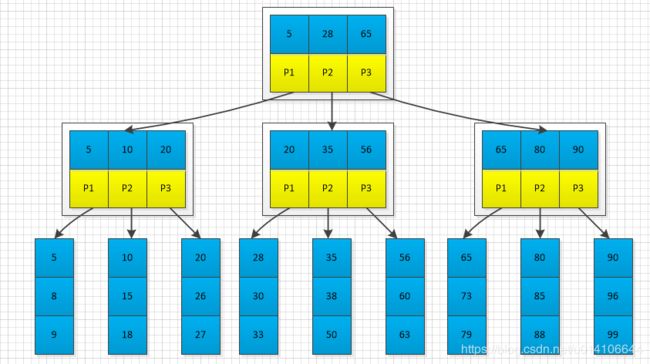
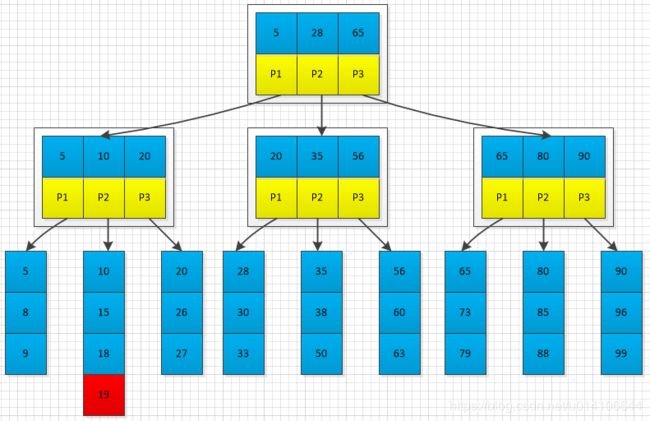
在下图M=3中插入19,首先找到19的插入位置,插入;
插入之后,出现节点已满
将已满节点进行分裂,将已满节点后M/2节点生成一个新节点,将新节点的第一个元素指向父节点;
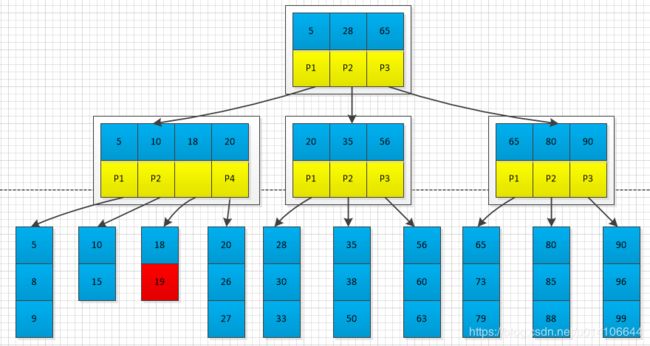
父节点出现已满,将父节点继续分裂
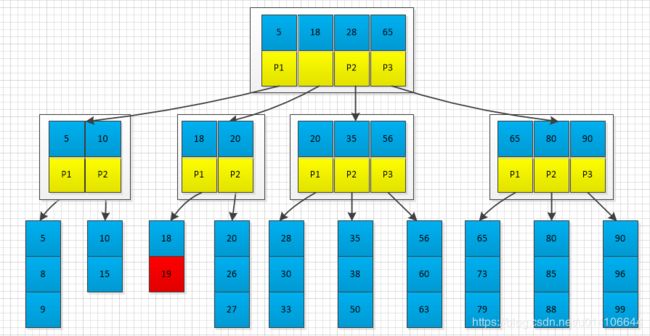
一直分裂,如果根节点已满,则需要分类根节点,此时树的高度增加
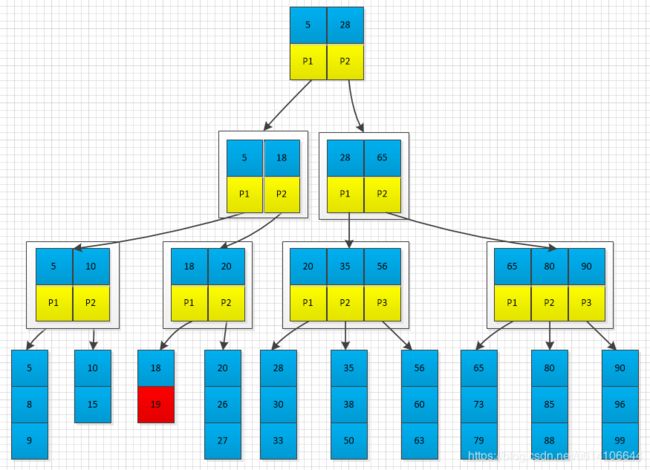
对于根节点分裂,新建一个节点 将旧根节点第一个元素以及分类节点第一个元素组合作为新的根节点。
public void put(Key key, Value val){
//插入后的节点 如果节点分裂,则返回分裂后产生的新节点
Node u = insert(root, key, val, height);
n++;
//根节点没有分裂 直接返回
if(u == null) return;
//分裂根节点
Node t = new Node(2);
//旧根节点第一个孩子 新分裂节点第一个孩子组成新节点作为根
t.children[0] = new Entry(root.children[0].key, null, root);
t.children[1] = new Entry(u.children[0].key, null, u);
root = t;
height++;
}性能:
含有N个元素的M阶B+树,一次查找或者插入的时间复杂度为log(M)N~log(M/2)N,当M较大时,该值基本为常数;
代码位置:https://github.com/ChenWenKaiVN/TreeSWT/blob/master/src/com/tree/bt/BTree.java
参考链接:
https://algs4.cs.princeton.edu/code/edu/princeton/cs/algs4/BTree.java.html
https://www.2cto.com/net/201808/773535.html
https://blog.csdn.net/qq_35008624/article/details/81947773
https://www.cnblogs.com/vincently/p/4526560.html