什么是高并发?
狭义来讲就是你的网站/软件同一时间能承受的用户数量有多少
相关指标有
并发数:对网站/软件同时发起的请求数,一般也可代表实际的用户
每秒响应时间:常指一次请求到系统正确响的时间(以秒为单位)
TPS(每秒事务数):每秒钟可以处理的事务(请求响应),大概的计算公式为:并发数/每秒响应时间=TPS
QPS(每秒查询数):TPS事务有读有写,而QPS指的是读取,一般情况QPS应是高于TPS的
IP(独立IP):一个IP可以发生多次UV和PV
PV(访问量):即Page View,页面浏览或点周量,用户每次新刷新即被计算一次
UV(独立访客):一般通过cookies记录等判断为一个独立用户,同一IP可能有多个UV(共享IP),发生多次PV
流量(网络流量):请求所产生的网络流量,因为受限于带宽也是并发中的一个重要指
一般公司演化阶段
1、优化运算代码、SQL查询、数据库索引等
2、进行应用负载均衡、数据库做主从/主主复制进行读写分离、增加缓存(Redis\Mem)
3、对系统和数据进行垂直拆分,按业务模块拆分成不同的应用及数据库表
4、分布式服务化、异步消息机制、数据库表水平拆分
优化运算代码、SQL查询、数据库索引等
一般初创公司系统大多数都是单体单库的系统,按照成本优先级第一要做的就是对系统进行代码级的优化。比如应用代码逻辑梳理、合理使用多线程、SQL避免全表扫描、少使用LIKE、
根据业务创建索引等。
案例
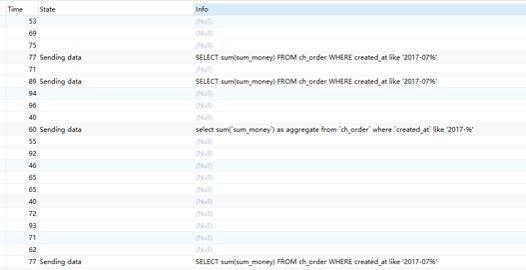
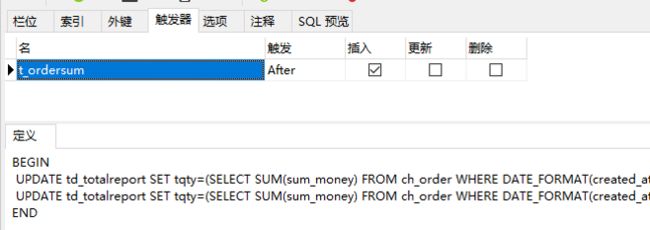
单次LIKE大数据量统计查询Sending data状态过多导致数据库连接被耗尽,系统停止响应。通过在统计表建立触发器更新单值表解决
负载均衡、读写分离、缓存
到了第二阶段,单体应用通过优化与增加硬件配置已无法解决高并发的问题,这时可以考虑进行以下架构的演化,这种演化对系统基本没有侵入性,成本低廉
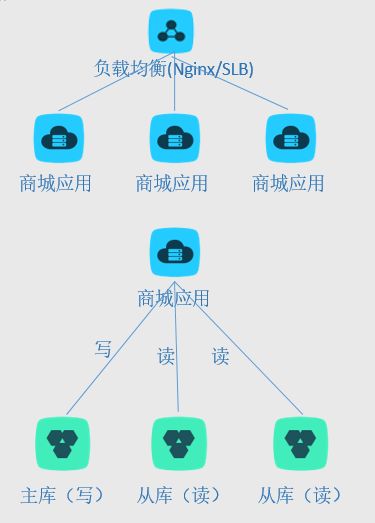
负载均衡:
可以通过Nginx反向代理、F5等进行应用的多流量分发,需要解决的问题就是会话问题,可采用Nginx的路由或是SESSION同步/独立。
读写分离:
采用数据库的主从复制机制,将写入库与读取库分离,可采用中间件进行代理路由,基本可以不改代码。
缓存:
可跟据业务规则将部分数据进行缓存
应用、数据垂直拆分
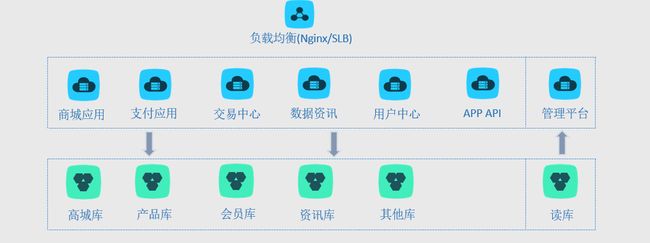
第二阶段支撑过一定量后,随着并发量再次的提升,由于单库表数据量变大以及访问限制已经不能满足,这时可以考虑进行数据库表的按系统模块垂直拆分。将内联的业务划分为独立的库表,相应的应用也
应随之拆分(应用这时加机器还能挺,不过做不到可审缩资源利用最大化)。同一应用系统访问同一库表,应用系统之间进行少量通信。
分布式服务化、异步消息机制、数据库表水平拆分
在经历过前三阶段后,能走到第四阶段说明平台的发展非常好了,对系统的高并发又有了进一步的要求,这也是成本最高最复杂的,系统架构需要进行很大的改造
分布式:
对系统应用进行服务化(如微服务),服务化的目的不只是为了高并发,也从系统的可维护性(团队大了)、资源利用最大化(对服务进行差异化支撑)方面考虑。
面临的挑战主要是分布式事务方面的控制,可采用二阶段提交方式或是分布式事务容器实现分布式事务。
异步消息机制:
主要解决大并发写入瓶颈,利用消息对列对写入消息进行排队,待数据库进
行处理。
数据库表水平拆分:按一定规则将同一业务表的数据拆分到不同的库/表中(如HASH),面临的挑战主要是跟业务关联性强、跨表的数据合并等。解决方案就是写
好代码吧。。。
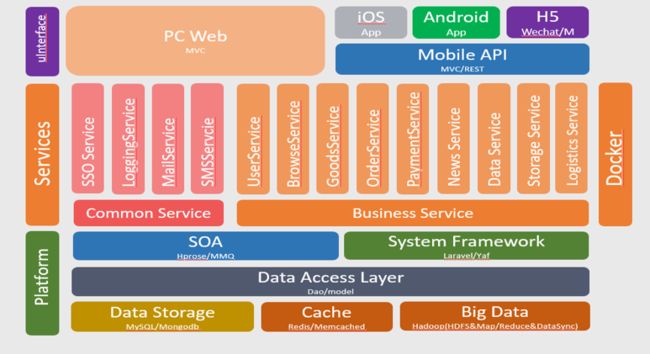
http://www.cnblogs.com/assion/p/7239106.html