前端如何搞监控--前端早早聊大会总结
前言 :
在4月25日,我参加了前端早早聊的在线直播话题—前端如何搞监控。
听完之后收获很大。我将把会议总结为前端搞监控的价值、需要监控的内容等方向去描述,并以自研监控SDK的经验为例,进一步了解前端搞监控的技术点所在。
本文已同步发表在掘金论坛上
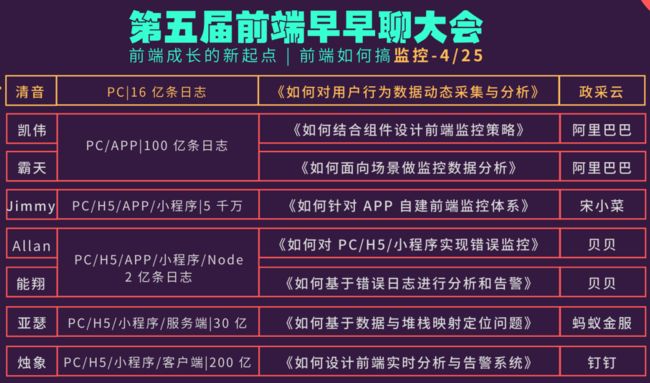
目录
- 一 前端监控系统概览:
- 1 为什么要做一套前端监控系统?
- 2.前端监控需要监控什么?
- 3.前端监控设计策略
- 3.1 面向组件设计监控策略
- 3.2 面向业务设计监控策略
- 二 自建前端监控体系
- 1 以宋小菜APP为例,针对APP自建前端监控体系
- 2 以贝贝自研SDK为例,对数据进行搜集与清洗
- 数据搜集与上报
- 数据清洗与压缩:
- 数据告警
- 3 基于错误日志进行进一步的优化
- 4 如何基于堆栈映射去定位问题?
- 三 监控系统在实际应用中还存在的问题
- 四 感触
- 五 关于前端早早聊大会
一 前端监控系统概览:
1 为什么要做一套前端监控系统?
通过用户行为采集分析,当前端及客户端线上出现异常时,可以通过用户行为链及设备环境,快速定位线上环境的问题所在。
齐次,当功能上线后,用户的使用效果没办法衡量。需要数据指标去衡量,比如功能使用率、性能指标等。
业务方的对业务的创意及需求需要反复不断的调优、开发,相同的组件开发了无数个,很可能明天又得改回去,这就造成了大量的资源浪费。如果没有一个量化体系的话,运营只能通过上次成功的经验来感觉。所以需要通过对用户数据的监控,从而得到一个调优策略和量化指标。
之后,我们需要知道对于界面设计风格及投放的广告资源,哪些手段会更有价值,去做一个人群的细分,提高用户体验。
2.前端监控需要监控什么?
前端监控采集的内容主要包括行为分析、异常监控、性能监控等。
其行为分析主要有:页面的进入、离开、点击、滚屏、自定义事件
简单做法是在项目的编译过程中,将项目ID、页面ID等挂载在标签上,当进入页面时,我们就可以根据这些ID去定位唯一一个页面,这样就可以知道用户的页面进入、离开及按钮的点击等事件

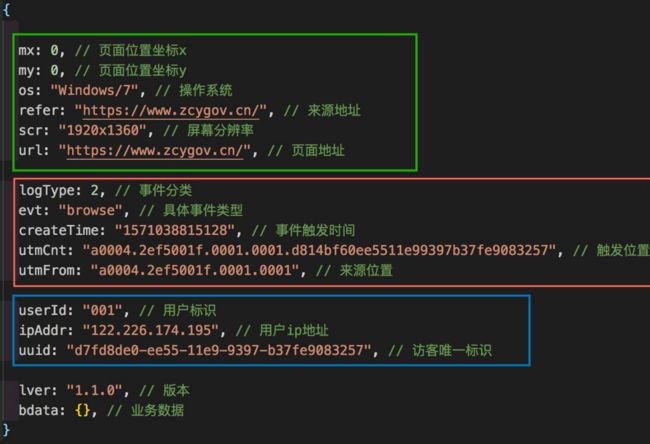
在这张图里可以看到上报的数据,比如坐标、分辨率等,从而可以分析用户点击的热力图、平台的整体兼容性、当前网络情况等
另外,还需要有对用户页面的浏览流程的一个上报,可以将ID拼接在超链接里,这样当用户点击页面跳转之后,就会被代入下一个页面,然后在下个页面中加载SDK后就会将该链接的值进行上报
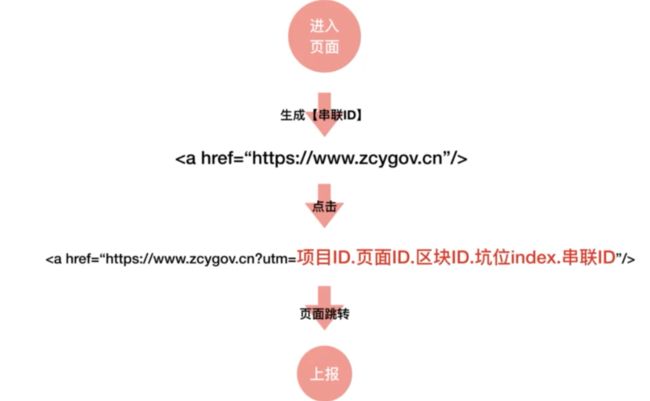
不过用户可能并不是完整地去走过了一个页面点击流程,而是从中间的页面进入比如点击了超链接,就需要让收集到的数据更有参考价值,以更准确地反映用户真实情况。
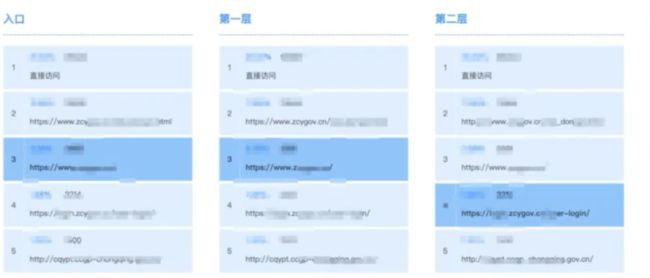
在路径分析里,去查看用户的来源和去向
另外可以记录用户的停留时长,因为有些用户可能一秒就关闭了窗口,而有些用户因没有关闭窗口就导致停留的时间非常长
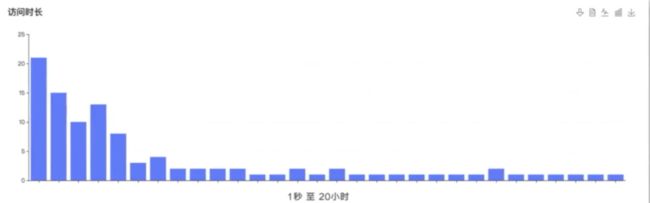
最后基于各个页面的分析数据,针对性地优化页面布局,增加用户吸引力,也可以根据用户的行为,深入分析用户对内容的注意力在哪块

3.前端监控设计策略
3.1 面向组件设计监控策略
我们将对网页的埋点分为如下几个级别,从而更好地为后面的分析提供服务
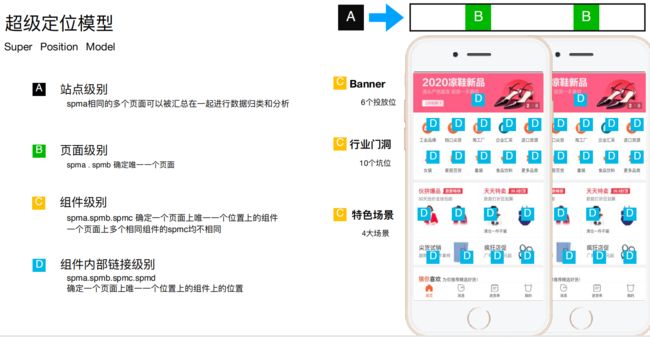
对不同的组件定义一些分析指标如转化率、渲染速度等,从而把一些效果比较好的组件的优先级不断提升
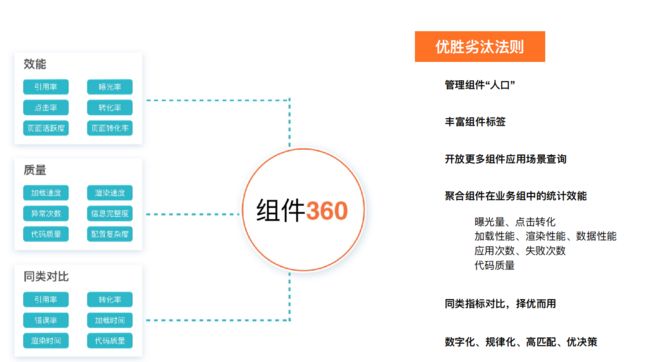
之后我们就可以对不同的组件进行一个综合的对比
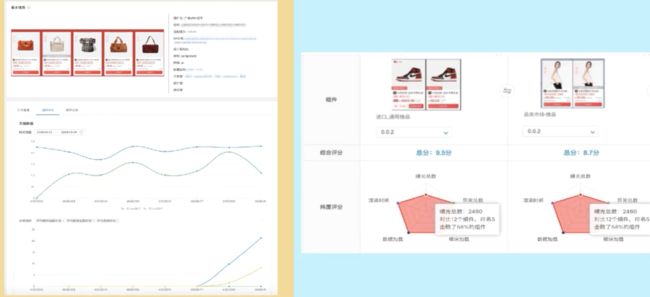
为了更方便分析数据。当内网访问时,CDN判断为白名单用户,就会为页面注入数据化分析能力,从而更方便地实时查看数据而无需再打开额外的数据分析平台
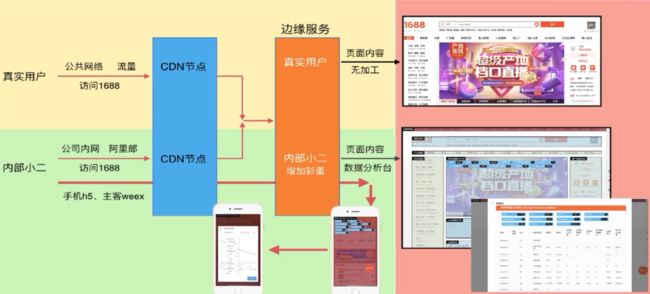
3.2 面向业务设计监控策略
对于不同风格的组件,需要进行一个精准的人群的划分
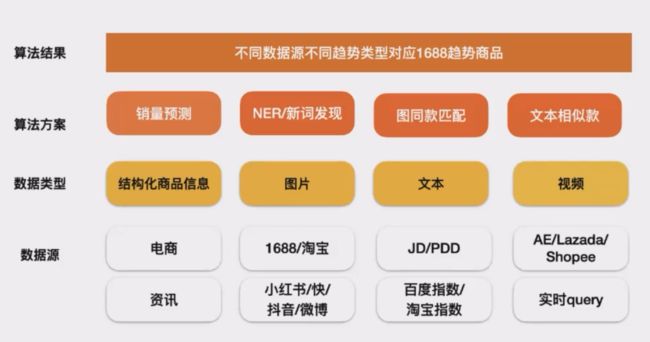
除了需要分析页面跟用户行为的关系之外,我们还需要依赖其他平台的信息,就比如在商城平台,疫情的爆发导致口罩的需求相应增加,微博抖音上某个商品的热度增加,从而为商品去打一个趋势分并分析用户的人群画像
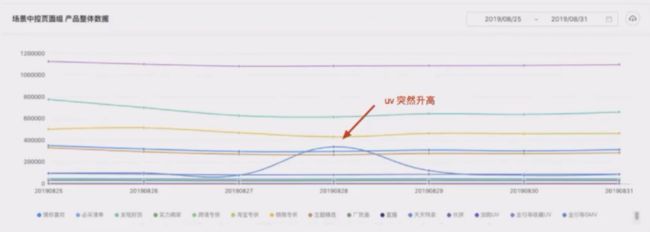
当发现监控数据在某个时间段发生了波动,从而帮助我们更好地去定位原因。比如是商品大促?媒体宣传?
整个下来需要有一个数据采集、数据存储、数据清洗、数据异常、数据展示的过程。
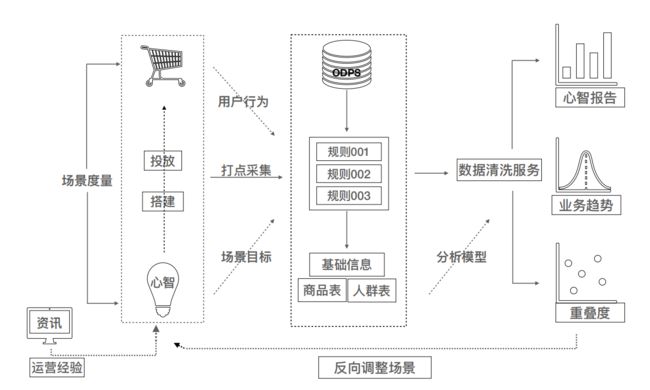
其中采集方式包括无埋点采集和有埋点采集。
无埋点采集主要是通过在框架层预设SDK,预设通用的事件。
有埋点采集对用户的浏览日志、浏览内容、触发时机等一些自定义事件的一种采集方式
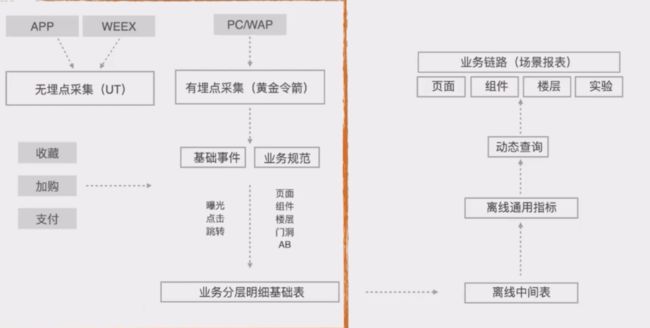
有时会根据业务去增加一些自定义采集

还需要对多端进行一个统一的采集,只有通过规范化的采集方式,才能更有效地整合数据,并在服务端才可以很容易地去查询和排查。
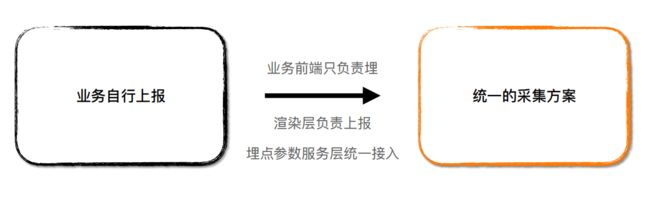
二 自建前端监控体系
作为开发运营者来说,自建前端监控体系,需要清楚地去分析及追踪,当线上的前端与客户端发生问题时,如何快速定位到这些问题并解决
1 以宋小菜APP为例,针对APP自建前端监控体系
其目前的系统架构如下
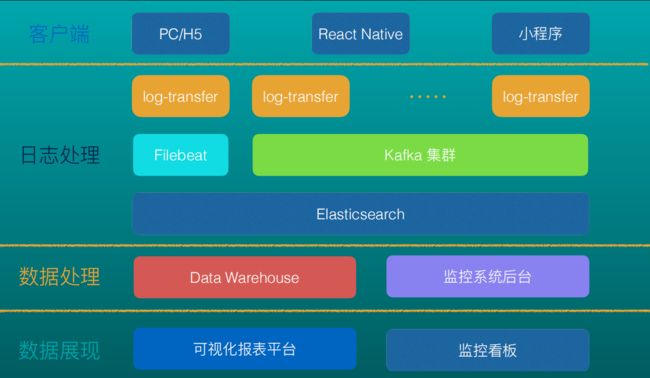
首先需要明确要采集哪些错误日志数据,然后去相应的设计SDK

主要SDK设计如下
RN SDK
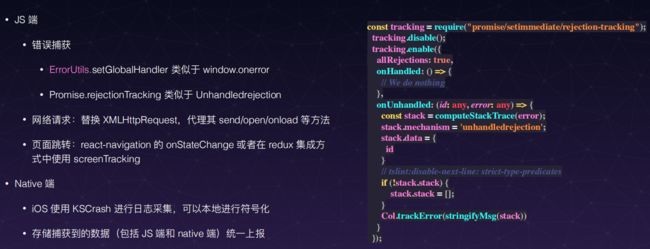
微信小程序 SDK

对Page和Component两个方法进行全局代理,这样就没必要在每次初始化小程序页面时都要埋点

在收集到的错误log里使用kafka进行转发
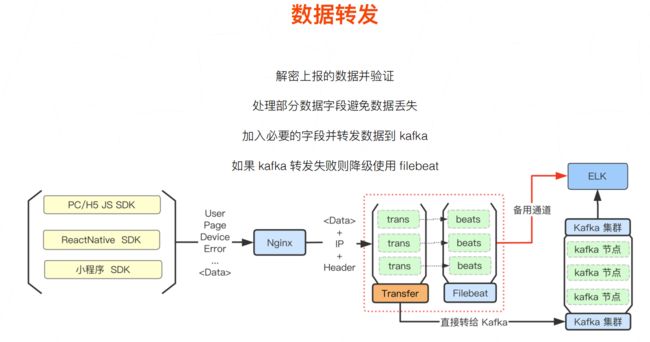
在日志处理时,可以采用一些策略
- 在向ES写入JSON时,由于数据量大,可以按时或按天建立索引,从而不会查询的时候特别慢
- 要建立一个统一的索引模板,对于索引的保存的数据类型要统一,否则会造成数据保存失败
- 由于上报的类型涉及到了多端,而且又包括自定义的上报内容,所以设计的上报的规范也不能太死。哪些字段变化哪些字段不变需要根据系统衡量

- 有一些字段是某些场景下是没有必要建立索引的,否则会造成字段爆炸,那么就可以以String类型存储下来
在报警监控系统的设计上,我们可以在监控后台上创建报警任务,然后报警任务通过kafka推送到任务管理中,任务管理器根据不同的任务分发到任务执行器中
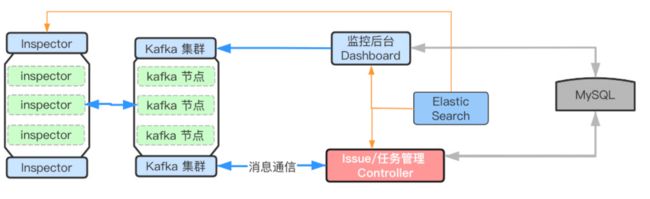
在收集到的错误信息上,都经过TraceKit做一个标准化,之后根据错误类型去做一个归类,如下面这些特征。根据这些特征,来判断信息是否为重复的问题

至于在监控系统中选择kafka而不是RPC等通信的原因如下:

最后,我们可以手动创建一些报警任务,比如针对某一个错误,规定是否当某一个规则满足时才上报以及监控的频率等
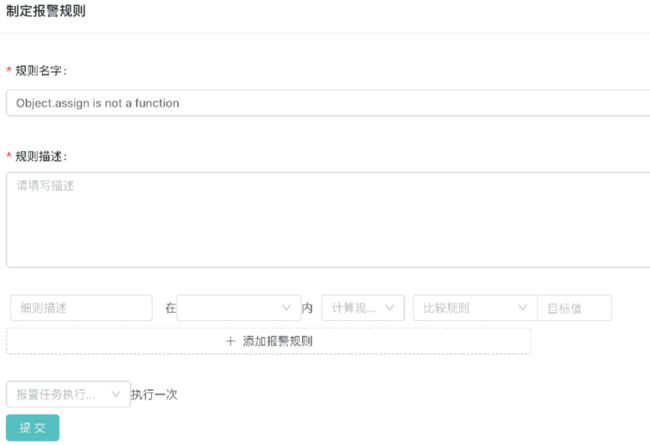
针对数据流这里不作过多介绍,可以参考该分享者发的链接60 天急速自研-搭建前端埋点监控系统大浪子
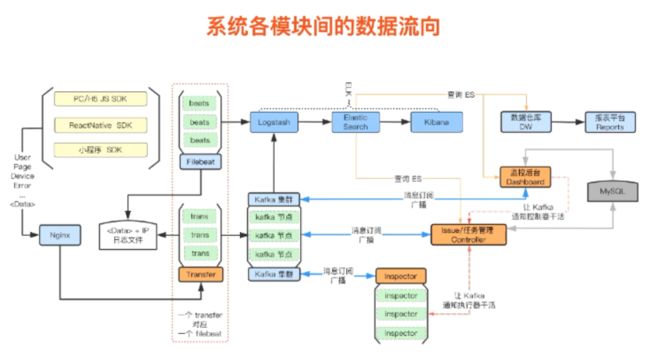
2 以贝贝自研SDK为例,对数据进行搜集与清洗
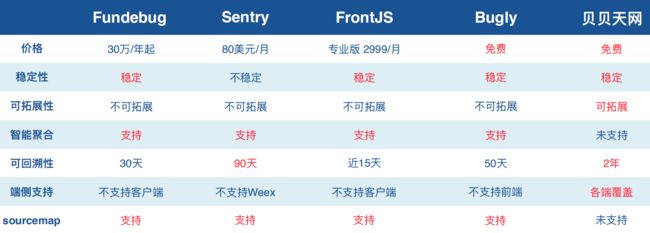
在监控平台上,贝贝选择的是自研SDK,原因是端平台多、项目多,第三方需要去考虑成本,另外在扩展性、支持的平台方面等,在目前的监控方案如Sentry、FundeBug、Bugly,也存在受限。
其整体流程为通过SDK进行上报给ES,在调度中心进行任务清洗,再将信息存储在MySQL中。最后通过Node.js为前端可视化提供接口
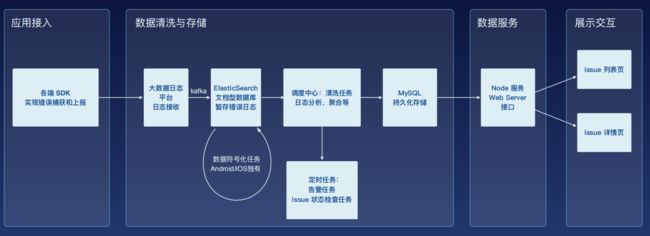
数据搜集与上报
在前端,可以通过上报上来的错误堆栈去分析应用出现的错误原因,方便排查问题
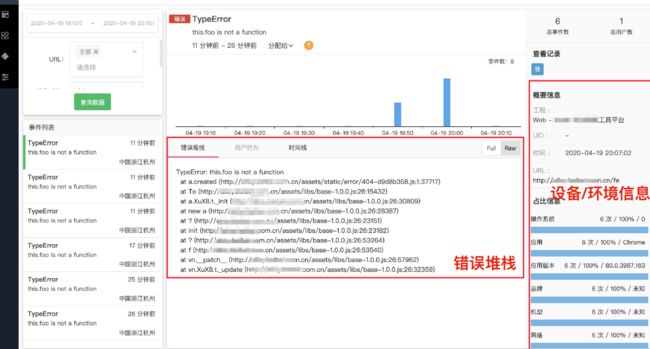
上报方式SDK如何设计?
对于上报方式,可以分为自动上报(左)和手动上报(右)

在错误捕获机制上,可以分为如下几种:
- window.onerror:运⾏时错误捕获
- window.addEventListener(‘unhandledrejection’):promise 没有 catch 错误
- try/catch 处理跨域脚本错误
- 其他技术栈中(Vue、React)的错误捕获
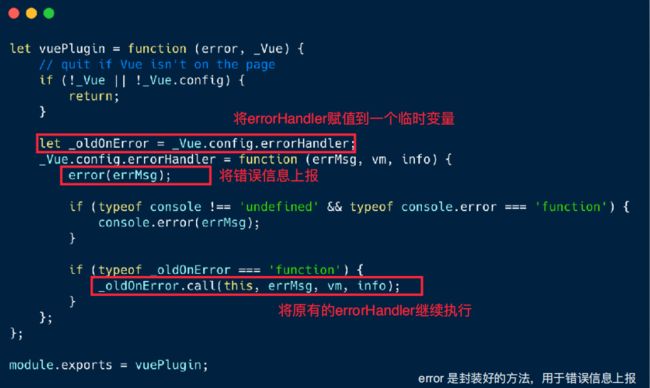
例如在Vue中,我们可以劫持它的errorHandler,然后在发生错误的时候上报,之后再去执行剩下的操作
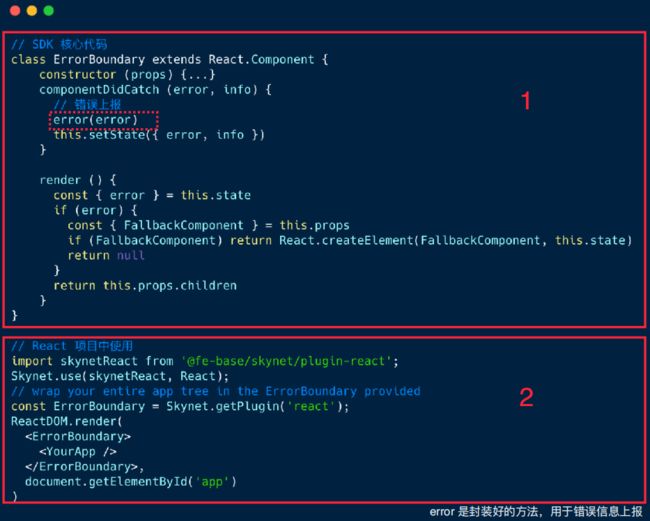
在React中,可以通过监听componentDidCatch,将错误捕获上报
SDK又如何去做信息收集?
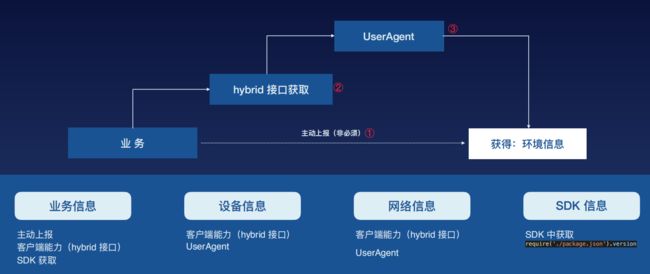
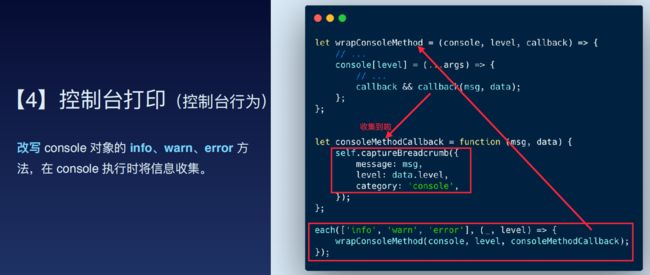
针对用户行为,通过全局监听事件,从而获取dom名称、行为栈等,当页面发生错误时,将行为和错误一起上报
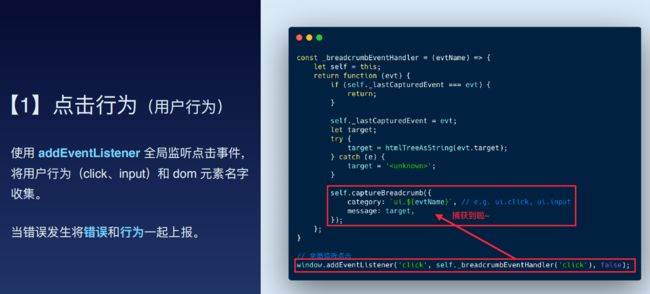
针对发送行为,通过监听XMLHttpRequest对象的回调函数
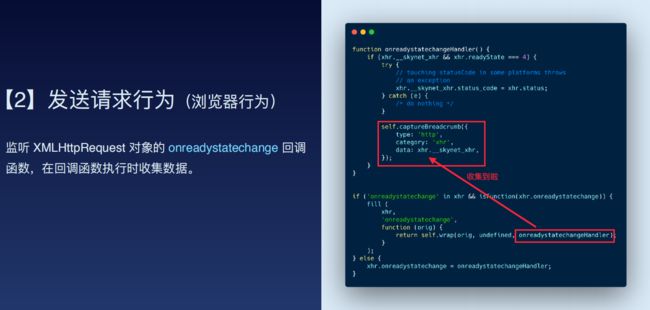
针对页面跳转,如前进、后退,通过监听window.onpopstate方法
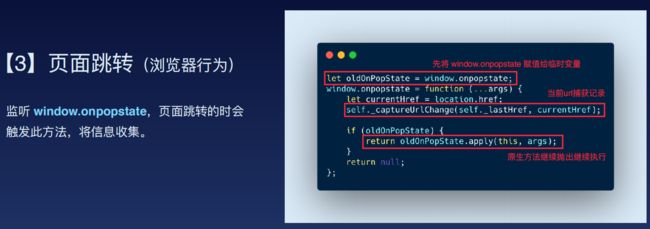
针对控制台打印,可以重写其info、warn、error方法
SDK如何进行数据上报?
使用通过GET方法发送一个1*1的GIF图片及错误信息进行上报
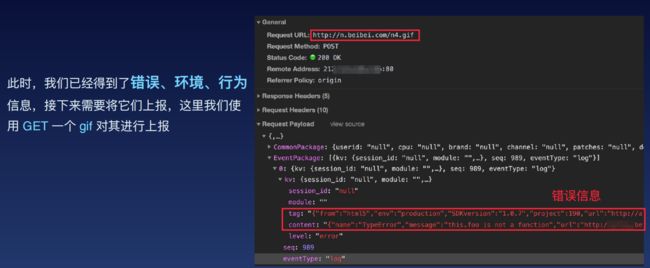
这里为什么要用1 * 1的GIF图片?

数据清洗与压缩:
SDK获取到的数据量大、没有分类聚合、也没有过滤,所以需要去进行一个数据清洗
首先在存储方案上,选择MySQL作为永久存储,选择ES作为临时存储
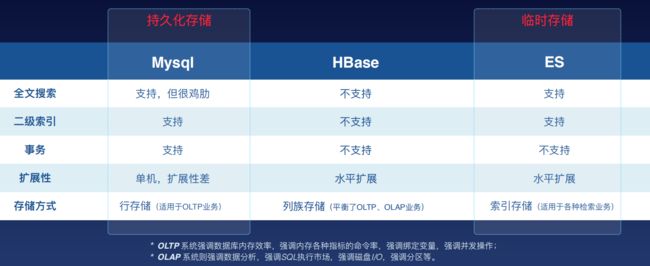
我们需要经过从ES保存的数据中获取数据->数据预处理->数据聚合这几个阶段,针对同样的错误,只处理前面的部分
对于收集到的数据设置阈值,即规定:
每分钟数据获取上限 10000 条,超过就采样⼊库。同类型错误数量⼤于 200 条,只统计数量
同时,由于ES返回的是String流格式,需要使用JSON.parse()解析出来。
最后将下面的数据去做修正如去掉转义符,忽略非法数据等。最终存到MySQL中。

针对一些相同类型的错误,需要进行数据聚合以起到压缩目的
在聚合的维度上,可以分为业务名、数据类型、错误信息
按照这样的3个维度,做成MD5以用于判断后面发生的错误是否为相同的错误

对于相同的错误,统计量就少了很多,同时可以记录错误的次数
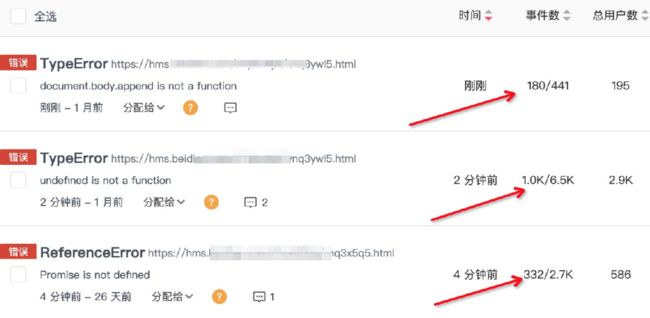
最后,针对监控系统中的数据清洗任务,我们也可以单独拿出来做一个监控
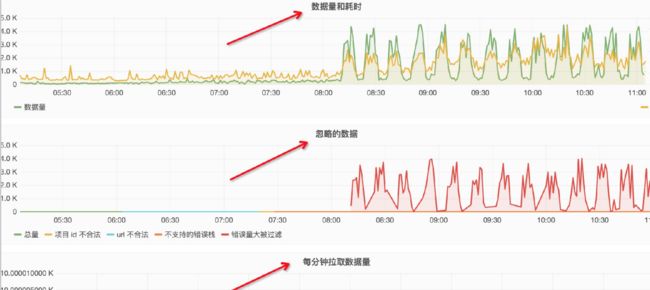
数据告警
当监控条件满足时,监控平台会将错误发送给相应的开发者
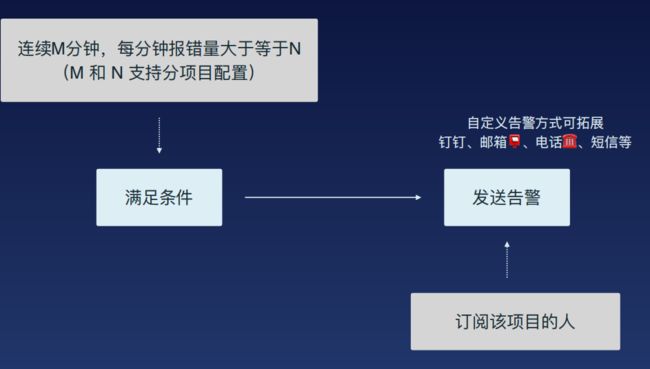
至此就完成了Web端的监控。其他平台则只需以统一的格式上传,后面的分析、清洗等都可以拿来复用。
比如对于Android来说,当错误发生时,先存储到本地的数据库,然后进行尝试地上报。如果上报成功,就将本地数据删除,否则待下次APP启动的时候再上报

3 基于错误日志进行进一步的优化
在系统中,需要对数据日志清洗、辅助分析能力、用户界面展示、错误告警追踪能力进行进一步优化
在错误聚合中可分为通用优化和专用优化

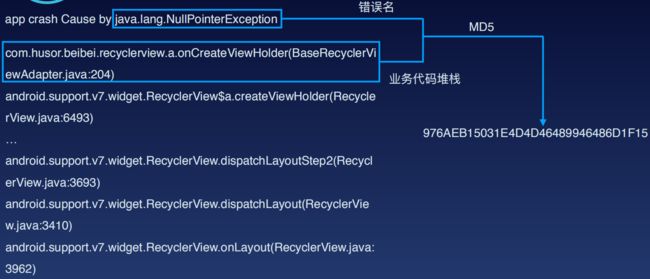
举个例子,下面是android端收集到的其错误名称、错误描述、错误堆栈
如果本是同一个错误,却因为一些原因如发生错误的视图信息(红色部分)导致描述不同,就可以只把相同的部分,错误名和错误堆栈做一个散列

另外,可能因为系统的不同,错误堆栈可能调用链路一样,但发生的位置有些差别
这时可以通过正则去掉系统类对应的行号去掉,再去散列

还可能因APP版本等问题,导致堆栈链路也不同但实质上也为同一个错误,则只需抽取业务类和部分系统类堆栈,再去散列,而不是全部错误链路
对于OOM,因为导致的原因五花八门,堆栈意义较小,更多地是去看设备信息、页面信息等其他维度去查看
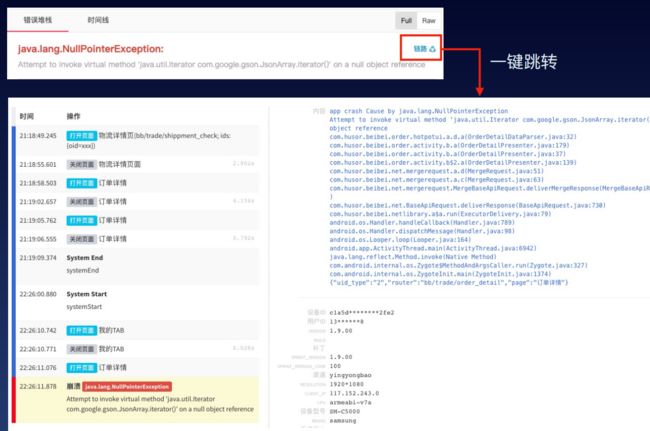
比如在前端上,可以分析前端的行为链路

在客户端上,用户产生的行为日志包括网络日志,通过链路ID进行关联起来
监控系统最终还要形成一个错误闭环,当发生错误时,及时交付给相应开发人员,版本成功修复以后再对线上监控进行一个更新
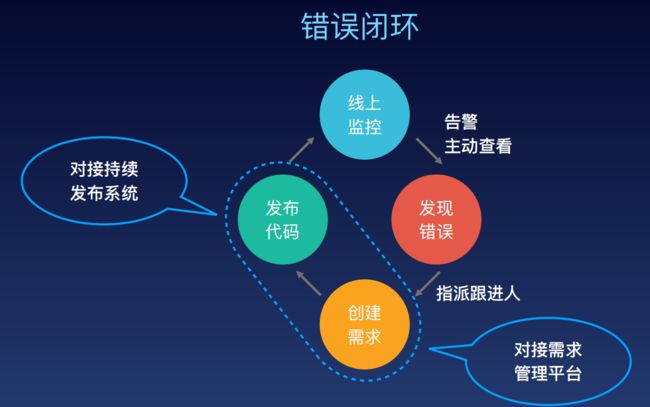
比如看版本变更后是否问题改善,或是因版本的问题而产生的异常
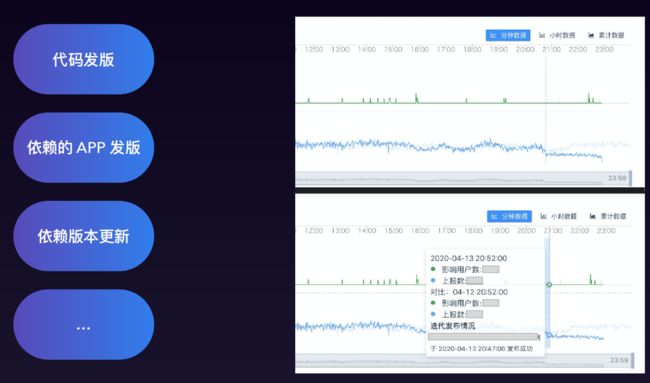
告警要监控时效性和有效性
在监控的筛选时间中,还要注意客户端是先将错误保存到本地,之后会尝试性地去上报错误。端侧会累积错误并存在延迟,所以服务器接受到的错误很可能并不是最新的错误。
所以对于数据的筛选与告警阈值的设定,就可以有下面这两种策略。
如果按服务端时间来进行筛选,就可以定义一个小时内发生的错误为最近的错误。如果按客户端时间,则看在这一个小时内,哪些错误在一个小时内,其记录的错误里间隔一分钟的时间的错误数量超过了阈值。

4 如何基于堆栈映射去定位问题?
前端问题的定位难在什么地⽅?
前端的日志不像服务端,它是发生在端侧的,所以只能依赖于上报,但上报的话又不可能获取到所有的信息,可能会缺失上下文,另外前端代码会进行混淆,堆栈无法直接使用。

异常定位实践:
可以在服务端将堆栈做个SourceMap映射到源码上
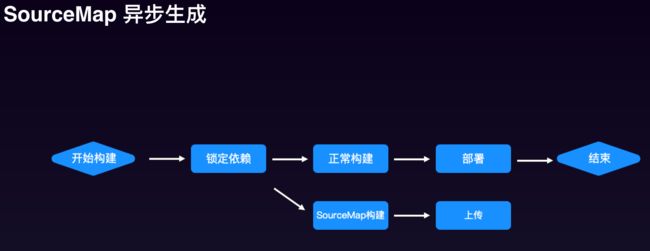
但会有一些问题,比如可能因为依赖的包的版本变化,导致线上映射后和实际生产环境的代码不对应。SourceMap映射也相对较慢,等映射完再去排查可能浪费了很多时间而且映射时会占用很大内存
给出的解决方案是异步生成SourceMap。首先锁定依赖,避免后面因版本问题导致堆栈对不上,之后将SourceMap映射和正常的版本构建分离开,这样就不会因SourceMap的占用内存过大导致影响正常版本的上线
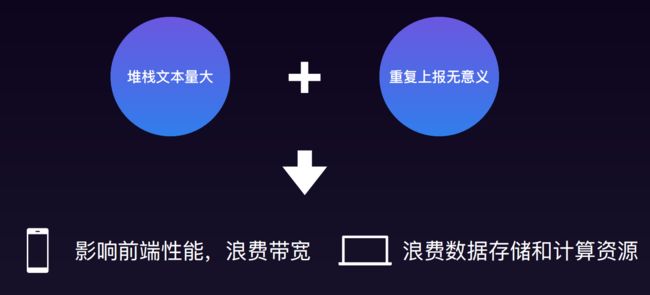
前端也不能全堆栈上报,否则会带来一些问题
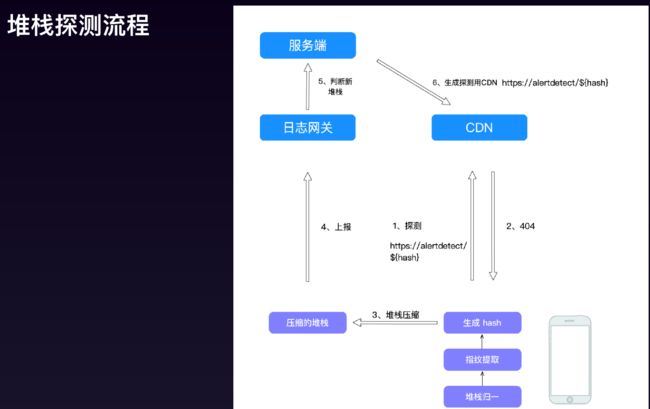
为了减少堆栈上报,需要判断重复堆栈。那么怎么判断重复堆栈?
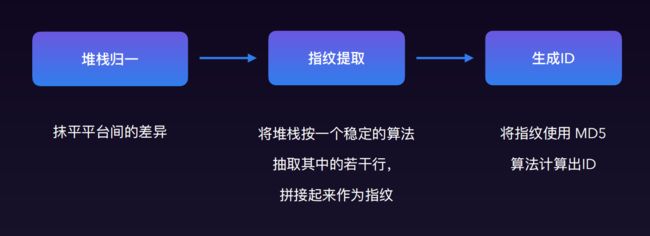
客户端拿到这个堆栈ID后,最简单的方式是服务端提供接口进行查询。但当堆栈量级巨大时,为了提高查询性能。可以先将哈希拼接到url上去CDN看是否有资源,如果没有上报过肯定返回404,然后将堆栈和哈希上报到服务端中,服务端再向CDN发一个空文件。后面再判断时发现已经有过了就不再上报了。
前端监控本身还有好多路要走,比如对于一些不是很严重的错误就尽量少报,不要无论什么信息都上报等等

三 监控系统在实际应用中还存在的问题
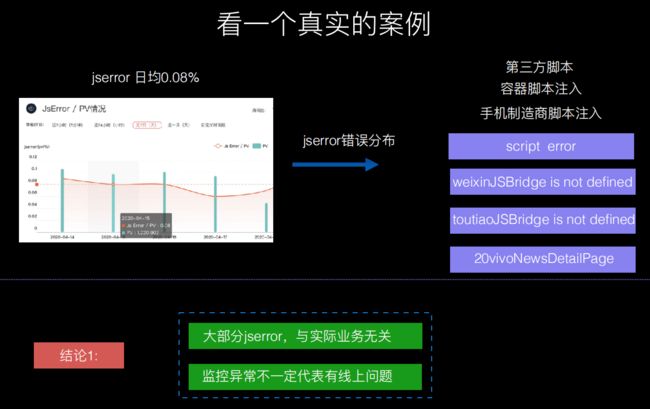
1.有些异常是由于手机厂商、第三方注入等导致的,并不是实际业务引起的
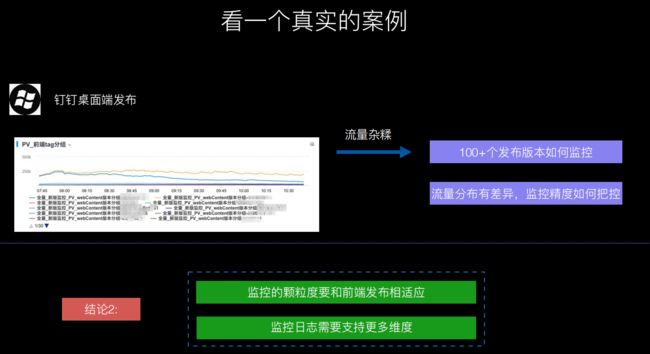
2.对于客户端,会因为版本的迭代不同,客户端版本不统一,所以监控日志就需要更多维度
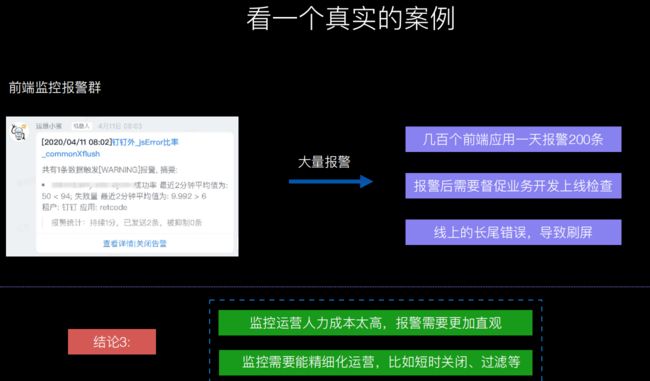
3.另外对于多个应用,更需要去筛选过滤。同一个应用可能之前已经解决了,但客户端未更新版本,则无需关注
钉钉通过日志聚合、日志过滤、日志分组、日志报警、计算规则这一系列流程对日志流处理,通过白名单、黑名单确定报上来的日志是有效的日志

另外采用了日志双写同时进行存储和运算,使得实时能力加强
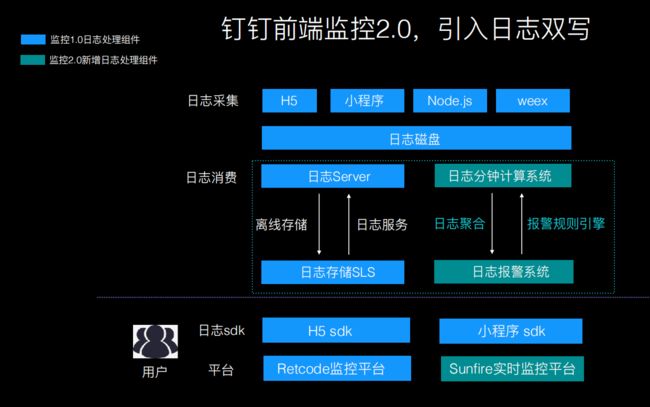
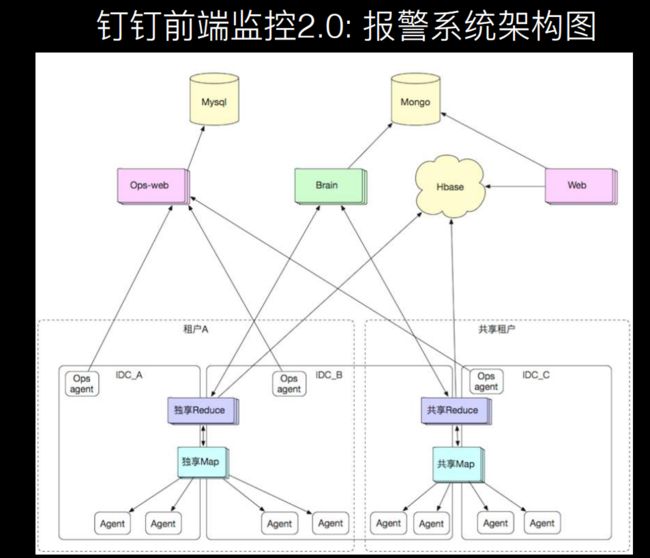
这是钉钉的监控架构,可以参考谈阿里核心业务监控平台 SunFire 的技术架构
四 感触
从会议中了解到了前端搞监控的巨大意义和相关技术点,使用监控系统从而更好地提升用户体验和产品开发以及问题排查,这些都是自己之前从未接触过的。特别感谢前端早早聊大会的分享,收获颇多!
五 关于前端早早聊大会
关于前端早早聊大会:前端早早聊大会目标成为用得上、听得懂、抄得走的技术大会,计划
2020年办>= 15期,由前端早早聊与掘金联合举办,前端早早聊大会行程动态、录播视频/PPT/讲稿资料下载请关注 「前端早早聊」 公众号跟进。
