自监督:对比学习contrastive learning
对比自监督学习
英文原文
对比自监督学习
导读
利用数据本身为算法提供监督。
对比自监督学习技术是一种很有前途的方法,它通过学习对使两种事物相似或不同的东西进行编码来构建表示。
自监督方法将取代深度学习中占主导地位的直接监督范式的预言已经存在了相当一段时间。Alyosha Efros打了一个著名的赌,赌在2015年秋季之前,一种无监督的方法将会在检测Pascal VOC方面胜过有监督的R-CNN。但四年之后,他的预言现在已经实现了。目前,自监督方法(MoCo, He et al., 2019)在Pascal VOC上的检测性能已经超越了监督方法,并在许多其他任务上取得了良好的效果。
最近自监督学习复苏背后的一系列方法遵循一种被称为对比学习(contrastive learning)的范式。
许多现代的ML方法依赖于人类提供的标签或奖励作为训练过程中使用的唯一学习信号形式。这种对直接语义监督的过度依赖有几个危险:
- 基础数据的结构比稀疏标签或奖励所能提供的要丰富得多。因此,纯监督学习算法往往需要大量的样本来学习,并收敛于脆弱的解决方案。
- 高维问题不能直接监督,RL等问题获取标签的边际成本更高。
- 它导致针对特定任务的解决方案,而不是可以重新利用的知识。
自监督学习提供了一个很有前途的选择,其中数据本身为学习算法提供监督。在这篇文章中,我会试着概述对比方法与其他自监督学习技术的不同之处,并回顾这一领域最近的一些论文。
图解的例子
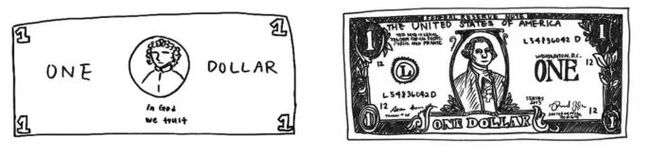
左图:凭记忆画的一美元钞票。右图:照着一美元钞票画的。
看看Epstein, 2016年做的这个实验,在这个实验中,受试者被要求尽可能详细地画一张美元的图片。
左边的图表示通过回忆一美元钞票的样子画出的。右边的图是他们后来照着一张现钞画的。很明显,在没有美元钞票的情况下所画的图与根据原型所画的图有很大的不同。
尽管我们已经无数次地看到一美元纸币,但我们没有得到它的完整表示。事实上,我们只保留了足够的特征来将它与其他物体区分开来。类似地,我们能否建立一种不关注像素级细节、只编码足以区分不同物体的高级特征的表示学习算法?
生成方法 vs 对比方法
当代的自监督学习方法大致可以分为两类:

对比法,顾名思义,就是通过对比正负样本来学习表示。虽然不是一个新的范式,这种方法在计算机视觉任务已经得到了巨大的成功经验的计算机视觉任务与非监督对比的预训练。
最值得注意的是:
- 对比方法在未标记的ImageNet数据上进行训练,使用线性分类器进行评估,超过现在监督AlexNet的准确性。与纯监督学习相比,从标记数据学习时,它们也表现出了显著的数据效率(data - efficient CPC, Henaff et al., 2019)。
- ImageNet的预训练成功地迁移到了其他下游任务,并优于有监督的预训练对手(MoCo, He et al., 2019)。
它们不同于更传统的生成方法来学习表示,后者关注于像素空间中的重构误差来学习表示。
- 使用像素级损失可能导致这种方法过于关注基于像素的细节,而不是更抽象的潜在因素。
- 基于像素的目标通常假定每个像素之间是独立的,因此降低了它们建模相关性或复杂结构的能力。
对比方法如何工作?
更正式地说,对于任何数据点x,对比方法的目的是学习编码器f:
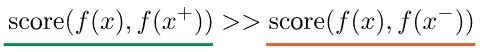
- 这里x+是与x相似或相等的数据点,称为正样本。
- x−是与x不同的数据点,称为负样本。
- score函数是一个度量两个特征之间相似性的指标。
x通常被称为“锚”数据点。为了优化这一特性,我们可以构造一个softmax分类器来正确地分类正样本和负样本。这个分类器鼓励score函数给正例样本赋于大值,给负样本赋于小值:
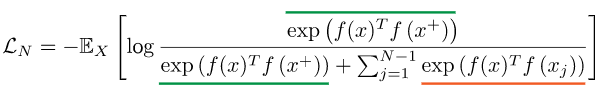
分母项由一个正样本和N - 1个负样本组成。这里我们使用点积作为score函数:
![]()
这是N-way softmax分类器常见的交叉熵损失,在对比学习文献中通常称为InfoNCE损失。在之前的工作中,我们将其称为多类n-pair loss和基于排序的NCE。
InfoNCE也与互信息有关系。具体地说,最小化InfoNCE损失可使f(X)和f(X+)之间互信息的下界最大化。
让我们更仔细地看看不同的对比方法来理解他们在做什么:
Deep InfoMax

Deep InfoMax中的对比任务
Deep InfoMax (DIM, Hjelm等人,2018)通过利用图像中的本地结构来学习图像的表示。DIM的对比任务是区分全局特征和局部特征是否来自同一幅图像。在这里,全局特征是卷积编码器的最终输出(一个平面向量,Y),局部特征是编码器中间层(一个M x M特征图)的一个输出。每个局部特征图都有一个有限的感受野。所以,直观上,这意味着要做好对比任务全局特征向量必须从所有不同的局部区域中获取信息。
DIM的损失函数看起来与我们上面描述的对比损失函数完全一样。给定一个锚图像x,
- f(x)为全局特征。
- f(x+)为同一图像(正样本)的局部特征。
- f(x−)是指来自另一幅图像(负样本)的局部特征。
DIM的应用还延伸到了其他领域,如graph和RL。对DIM的后续研究,即增强多尺度DIM (Bachman et al., 2019),使用线性分类协议评估时,使用无监督训练在ImageNet上实现了68.4%的Top-1准确率。
Contrastive Predictive Coding
对比预测编码(CPC (van den Oord et al ., 2018) (https://arxiv.org/abs/1807.03748))是一种对比方法,可以应用于任何形式的可以表示为有序序列的数据:文字,语音,视频,甚至图片(一个图像可以看作是一系列像素或patch)。
CPC通过编码信息来学习表示,这些信息在相隔多个时间步的数据点之间共享,放弃了局部信息。这些特征通常被称为“慢特征”:不会随着时间变化得太快的特征。具体的例子包括音频信号中说话者的身份,视频中进行的活动,图像中的物体等。
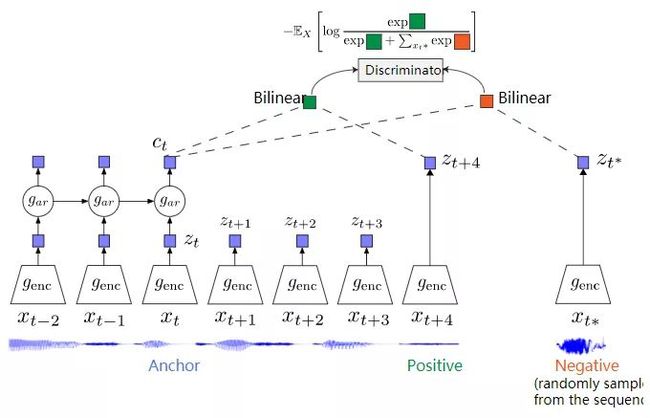
图解使用音频输入的CPC的对比任务
CPC的对比任务设置如下。设{x1,x2,…,xN}为数据点序列,xt为锚点。然后,
- xt+k是锚点的正样本。
- 从序列中随机采样的数据点xt∗是一个负样本。
CPC利用单一任务中的多个k来捕获在不同时间尺度上演化的特征。
在计算xt的表示时,我们可以使用运行在编码器网络之上的自回归网络来编码历史上下文。
最近的研究(Henaff et al., 2019)扩展了CPC,在ImageNet上用线性分类器评估时达到了71.5%的top-1准确率。
使用对比学习学习不变性
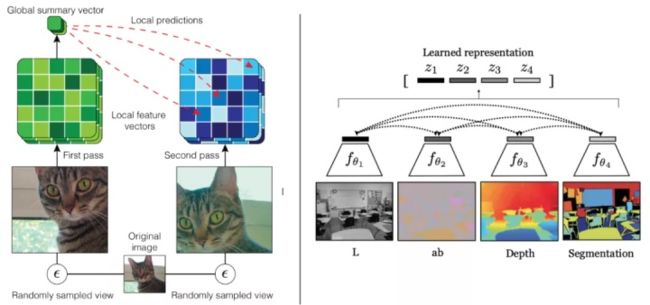
左:AMDIM学习数据增强(如随机裁剪)之间的不变的表示。右:CMC学习图像的不同视图(通道)之间不变的表示
对比学习提供了一种简单的方法在表示空间中来施加不变性。假设我们想要一个表示对一个变换T不变(例如剪裁、灰度缩放),我们可以简单地构造一个对比目标,给定一个锚点x,
- T(x)是正样本
- T(x′)其中x′是随机的图像或数据,是负样本
最近的几篇论文中使用了这种方法,并取得了巨大的经验成功:
- 增强多尺度DIM (AMDIM,Bachman et al., 2019)使用标准的数据增强技术作为转换集,表示应该对不同的增强方法具有不变性。
- 对比多视图编码(CMC, Tian et al., 2019)使用同一幅图像的不同视图(深度、亮度、亮度、色度、表面法线和语义标签)作为变换集,其表示也应该是不变的。
扩展负样本的数量 (MoCo)
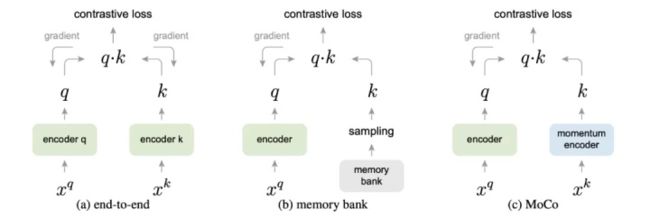
对比方法中使用负样本的不同策略的比较。这里xq是正样本,xk是负样本。注意,在MoCo中,梯度不会通过动量编码器回流。
对比方法在有更多的负样本的情况下效果更好,因为假定更多的负样本可以更有效地覆盖底层分布,从而给出更好的训练信号。在通常的对比学习公式中,梯度流通过编码器的正样本和负样本。这意味着正样本的数量被限制在mini-batch的尺寸上。动量对比(MoCo,He et al., 2019)通过维持一个大的负样本队列,并且不使用反向传播来更新负编码器,有效地绕过了这个问题。相反,它定期更新负编码器使用动量更新:
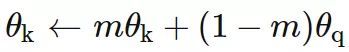
其中,θk表示负样本编码器的权重,θq表示正样本编码器的权重。
来自MoCo的一个相当惊人的结果是,在PASCAL VOC、COCO和其他数据集上,效果比有监督的预训练模型好,有时候远远超过。传统上,这些任务需要在ImageNet上进行有监督的预培训才能获得最佳效果,但MoCo的结果表明,无监督和有监督的预训练训之间的差距已经很大程度上缩小了。
自监督学习的一个泛化的范式
尽管在这篇文章中对比学习的大部分应用都集中在标准的计算机视觉任务上,我希望对比学习对于自监督学习来说是一个任意领域和任务的范式。它允许我们将关于数据结构的先验知识注入到表示空间中。这意味着,当我们远离静态iid数据集(丢弃了数据中的大量底层结构)并利用额外的结构信息时,我们可以构建更强大的自监督方法。
—END—