R语言----Factor类型的变量
- factor类型的创建
factor( )
> credit_rating <- c("BB", "AAA", "AA", "CCC", "AA", "AAA", "B", "BB") #生成名为credit_rating的字符向量
> credit_factor <- factor(credit_rating) # step 2.将credit_rating转化为因子
> credit_factor
[1] BB AAA AA CCC AA AAA B BB
Levels: AA AAA B BB CCC
> str(credit_rating) #调用str()函数,显示credit_rating结构
chr [1:8] "BB" "AAA" "AA" "CCC" "AA" "AAA" "B" "BB"
> str(credit_factor) #调用str()函数,显示credit_factor结构
Factor w/ 5 levels "AA","AAA","B",..: 4 2 1 5 1 2 3 4
- levels( )
上述代码中第二个运行后得到了levals,用于显示不同的因子(不重复),上述代码运行一二行
>credit_rating <- c("BB", "AAA", "AA", "CCC", "AA", "AAA", "B", "BB")
> credit_factor <- factor(credit_rating) # step 2.将credit_rating转化为因子
> credit_factor
[1] BB AAA AA CCC AA AAA B BB
Levels: AA AAA B BB CCC
> levels(credit_factor)
[1] "AA" "AAA" "B" "BB" "CCC"
>levels(credit_factor) <-c("2A","3A","1B","2B","3C")
> credit_factor
[1] 2B 3A 2A 3C 2A 3A 1B 2B
Levels: 2A 3A 1B 2B 3C
- Factor 汇总:summary()函数
> summary(credit_rating)
Length Class Mode
8 character character
> summary(credit_factor)
AA AAA B BB CCC
2 2 1 2 1
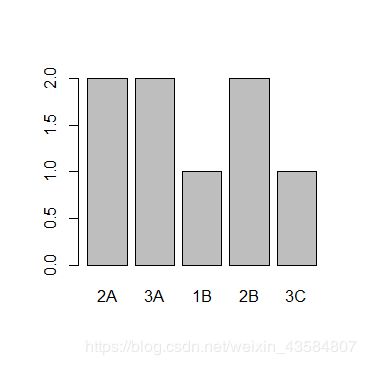
- factor 可视化:plot()
# 使用plot()将credit_factor可视化
plot(credit_factor)
#> summary(credit_factor)
# AA AAA B BB CCC
# 2 2 1 2 1
5. cut( )函数 对数据进行分组
>AAA_rank <- sample(seq(1:100), 50, replace = T)
> AAA_rank
[1] 90 28 63 57 96 41 93 70 76 36 26 1 86 43 47 15 23 70
[19] 63 1 79 100 20 59 17 23 84 96 21 33 32 19 52 58 81 37
[37] 22 58 42 75 41 64 15 58 63 2 1 65 54 35
> # step 1:使用cut()函数为AAA_rank创建4个组
> AAA_factor <- cut(x = AAA_rank , breaks =c(0,25,50,75,100) )
> > AAA_factor
[1] (75,100] (25,50] (50,75] (50,75] (75,100] (25,50] (75,100] (50,75]
[9] (75,100] (25,50] (25,50] (0,25] (75,100] (25,50] (25,50] (0,25]
[17] (0,25] (50,75] (50,75] (0,25] (75,100] (75,100] (0,25] (50,75]
[25] (0,25] (0,25] (75,100] (75,100] (0,25] (25,50] (25,50] (0,25]
[33] (50,75] (50,75] (75,100] (25,50] (0,25] (50,75] (25,50] (50,75]
[41] (25,50] (50,75] (0,25] (50,75] (50,75] (0,25] (0,25] (50,75]
[49] (50,75] (25,50]
Levels: (0,25] (25,50] (50,75] (75,100]
> # step 2:使用levels()按顺序将级别重命名
> levels(AAA_factor) <- c("low","medium","high","very_high")
>
> # step 3:输出AAA_factor
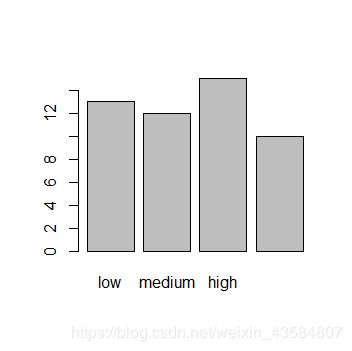
> AAA_factor
[1] medium medium very_high high very_high high high
[8] high medium medium very_high high medium very_high
[15] medium low medium low high medium low
[22] medium high very_high very_high very_high medium very_high
[29] low low low medium very_high low very_high
[36] low very_high low low high medium medium
[43] medium low low low low medium medium
[50] medium
Levels: low medium high very_high
>
> # step 4:绘制AAA_factor
> plot(AAA_factor)
>
6. 删除元素 :- 表示删除,
(1)-1:删除第一位的元素,-3:删除第三位的元素
(2)
> credit_factor
[1] BB AAA AA CCC AA AAA B BB
Levels: AA AAA B BB CCC
> # 删除位于`credit_factor`第3和第7位的`A`级债券,不使用`drop=TRUE`
> keep_level <- credit_factor[c(-3,-7)]
>
> # 绘制keep_level
> plot(keep_level)
>
> # 使用相同的数据,删除位于`credit_factor`第3和第7位的`A`级债券,使用`drop=TRUE`
> drop_level <-credit_factor[c(-3,-7),drop=TRUE]
>
> # 绘制drop_level
> plot(drop_level)
>
- 转换Factor为String类型
>cash=data.frame(company = c("A", "A", "B"), cash_flow = c(100, 200, 300), year = c(1, 3, 2)) #创建数据框
>str(cash)
'data.frame': 3 obs. of 3 variables:
$ company : Factor w/ 2 levels "A","B": 1 1 2
$ cash_flow: num 100 200 300
$ year : num 1 3 2
注意:创建数据框时,R的默认行为是将所有字符转换为因子
那么,如何在创建数据框时,不让r的默认行为执行呢?
采用 stringsAsFactors = FALSE
> cash=data.frame(company = c("A", "A", "B"), cash_flow = c(100, 200, 300), year = c(1, 3, 2),stringsAsFactors=FALSE) #创建数据框
> str(cash)
'data.frame': 3 obs. of 3 variables:
$ company : chr "A" "A" "B"
$ cash_flow: num 100 200 300
$ year : num 1 3 2
- 创建有序Factor类型:ordered=TRUE
# 有序Factor类型
credit_rating <- c("AAA", "AA", "A", "BBB", "AA", "BBB", "A")
credit_factor_ordered <- factor(credit_rating, ordered = TRUE, levels = c("AAA", "AA", "A", "BBB"))
>credit_rating <- c("BB", "AAA", "AA", "CCC", "AA", "AAA", "B", "BB")
> credit_factor <- factor(credit_rating) # step 2.将credit_rating转化为因子
> credit_factor #此时的credit_factor 无序
>ordered(credit_factor, levels = c("AAA", "AA", "A", "BBB"))
- 删除因子级别时,采用drop=TRUE
>credit_factor
[1] AAA AA A BBB AA BBB A
Levels: BBB < A < AA < AAA
>credit_factor[-1]
[1] AA A BBB AA BBB A
Levels: BBB < A < AA < AAA #可见,AAA还存在
>credit_factor[-1, drop = TRUE] #完全放弃AAA级别
[1] AA A BBB AA BBB A
Levels: BBB < A < AA