引言
语法纠错(Grammatical Error Correction, GEC)是自然语言处理领域中的一个重要任务,GEC任务要求检测一句话中是否有语法错误,并自动将检测出的语法错误进行纠正,GEC在文本校对、外文学习辅助中都有重要的应用。下面是一个语法纠错任务的示例,在这句话中,加粗的形容词absolute应该修改为副词absolutely。
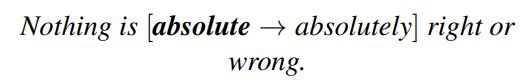
目前语法纠错任务主要是采用类似于机器翻译任务的Seq2Seq框架来实现的。具体来说,输入的错误句子为源语句,输出正确的句子为目标语句。例如下图中,“A B C D”为输入的错误句子,“X Y Z”为输出的修正句子。显然我们可以通过大规模的(错误句子,正确句子)平行语料来训练一个生成模型,然后通过生成模型实现语法错误的自动纠正。
通常生成模型需要大规模的平行语料来进行训练,例如机器翻译语料动辄数千万至数亿句不等。而语法纠错相关语料则比较匮乏,通常只有几十万句规模,因此如何解决数据匮乏问题是语法纠错研究的一个重点。此外,语法纠错任务中源语句和目标语句之间差别通常很小,使用Seq2Seq从头开始生成目标语句似乎有些“大材小用”。部分研究者根据此特点,提出了专门针对于语法纠错的模型结构,并取得了不错的效果。本文将主要针对语法纠错模型改进和语法纠错语料自动扩充两个方面进行重点介绍。
文本纠错技术介绍
1. 语料自动扩充方法
针对语法纠错训练数据不足的问题,部分研究者提出通过构造伪数据的方法来增加训练数据。猿辅导研究院的Wei Zhao等人提出采用随机制造错误数据的方法来构建伪数据,具体流程如下:按照10%的概率随机删除一个词;按照10%的比例随机增加一个词;按照10%的比例随机替换一个词;对所有的词语序号增加一个正态分布,然后对增加正态分布后的词语序号进行重新排序后得到的句子作为错误语句。该方法构造的训练数据在CoNLL2014等语法纠错数据集上获得了不错的表现。
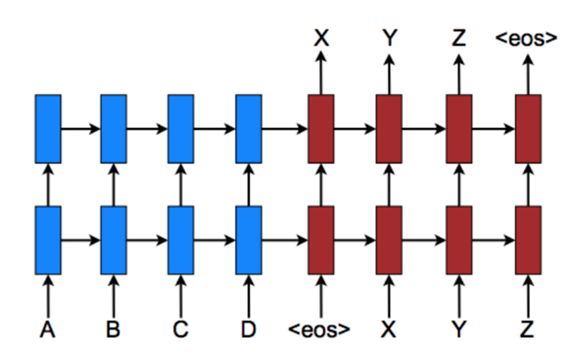
微软亚洲研究院的Tao Ge等人借鉴NMT领域的back translation思想提出了如下图所示的三种语料扩充方法。图中seq2seq error correction即我们最终要训练的语法纠错模型,seq2seq error generation是将训练数据的输入输出对调,将正确语句作为输入,错误语句作为输出训练得到的错误语句生成模型。

方法(a) back-boost通过将正确句子输入到seq2seq error generation中生成错误句子,那么得到的这个句对即可以作为error correction的训练数据。方法(b) self-boost将error correction生成模型本身生成的低质量纠正数据和正确语句组合在一起作为扩充的训练数据。方法(c) dual-boost则提出使用对偶学习的方法,将self-boost和back-boost进行结合,通过error generation和error correction不断扩充训练语料并互相促进学习。下表中的实验结果中可以看到dual-boost结果好于self-boost和back-boost。
随着深度学习技术的发展,机器翻译技术已经比较成熟,可以生成质量比较好的翻译。但是机器翻译系统仍然会产生一些难以避免的语法错误,Google研究院的Jared Lichtarge等人提出利用机器翻译系统来生成伪数据。具体方法是使用翻译系统将英语翻译成为一种中间语言(日语、法语等),然后再将中间语言翻译回英语。生成的英语语义和原始英语语句基本保持不变,但是往往会产生一些语法错误。Jared Lichtarge等人利用机器翻译的这种特性生成了大规模性的语法纠错伪数据,并在语法纠错任务上取得了很好的效果。
除了上述构造伪数据的方法外,Jared Lichtarge等人还提出采用维基百科的编辑记录来自动生成真实的语法纠错数据。维基百科会记录每一个版本的变化,里面包含大量的人工修正信息,因此可以采用两个相邻版本之间的变化来自动生成语法纠错数据。下图是实际生成的一些示例,我们可以从图中看到,维基百科数据生成的数据噪音比较大,会产生一些信息变动。

2. 模型改进方法
语法纠错任务中输入语句和输出语句之间的差异比较小,从下表可以看到输入语句和输出语句中80%以上的词语是相同的。猿辅导研究院的Wei Zhao等人基于此提出采用Copy机制来进行文本纠错,使模型的Attention等结构可以更多地学习如何纠正错误。

Copy机制的模型结构图如下所示,其主要思想是在生成序列过程中,考虑两个生成分布:分别是输入序列中的词语概率分布以及词典中的词语概率分布,将两者的概率分布加权求和作为最终生成的概率分布,进而预测每一个时刻生成的词语。该方法可以有效地利用输入语句和生成语句之间重叠词语多的特性,将简单的词语复制任务交给了Copy机制,将模型结构中的Attention等结构更多地用来学习比较难的新词生成。

上述基于Copy机制的方法可以比较好地利用输入语句和生成语句之间词语重复的特性,但是该方法仍然使用Seq2Seq框架从头开始生成目标语句,导致模型的预测速度较慢。
对于此问题,Google研究院的Eric Malmi等人在EMNLP2019中提出了一种基于文本编辑的文本生成模型LaserTagger。该模型的核心思想是:不直接生成文本,而是使用序列标注方法来预测编辑操作,再将预测的编辑操作结合输入文本转换为输出文本。论文主要定义了四类编辑操作:Keep、Delete、Keep-AddX和Delete-AddX,即保持、删除、保持当前词语的情况下在前面加入X短语,在删除当前词语的情况下在前面加入X短语。短语X均来自固定大小的短语词表,短语词表由训练集中源文本和目标文本没有对齐的top-n个n-grams构成。该方法可以在保证语法纠错精度损失较小的情况下提升语法纠错的预测速度。
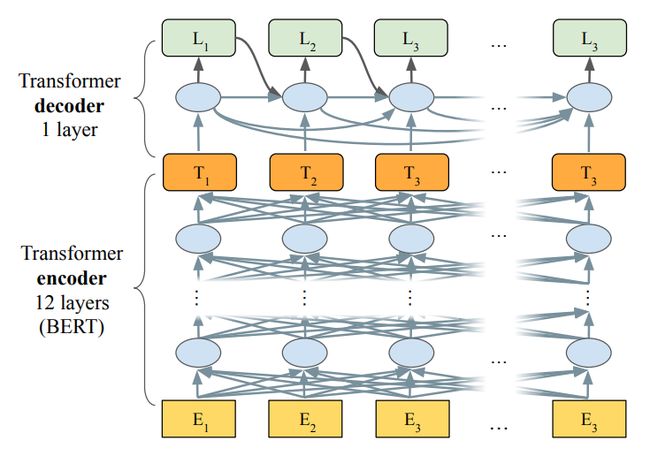
同样在EMNLP2019上,Awasthi等人提出一种并行迭代编辑(Parallel Iterative Edit, PIE)模型来解决局部序列转换问题(LST)。PIE模型的输出不是词汇表中的token,而是“复制、增加、删除、替换”等操作。PIE模型结构如下图所示,该模型是一个类似BERT的模型结构,只是每个token额外输入了两种表示,分别为[M,pi]和[M,![]() ]。其中M为[MASK]的表示,pi为位置表示,[M,pi]可以用来处理pi位置词语替换的情况;
]。其中M为[MASK]的表示,pi为位置表示,[M,pi]可以用来处理pi位置词语替换的情况;![]() 为两个词语中间的位置表示,[M,
为两个词语中间的位置表示,[M,![]() ]用来解决在pi和pi+1位置中间增加词语的情况。PIE模型能够并行解码,预测速度快且在精度上可以与seq2seq模型相媲美。
]用来解决在pi和pi+1位置中间增加词语的情况。PIE模型能够并行解码,预测速度快且在精度上可以与seq2seq模型相媲美。

目前存在的问题及挑战
目前的语法纠错任务主要存在以下几个问题:
1. 速度太慢,难以大规模应用:目前语法纠错技术主要采用的是Seq2Seq生成式模型,语法检测等任务则是采用的BERT模型,这些模型对应的规模比较大,在实际应用中往往需要使用GPU且速度较慢。这些问题极大地限制了语法纠错技术的应用和普及,所以如何压缩和减小语法纠错的模型,加快预测速度是一个研究的重点。
2. 真实的训练数据太少:虽然研究人员提出了各种各样的方法来增加训练数据,但是增加的训练数据质量往往不尽如人意,如何增大真实训练数据的规模仍然是一个研究重点。
3. 针对语法纠错的模型:目前语法纠错领域采用的模型更多使用的还是机器翻译、文本摘要中的一些模型,很少有专门针对语法纠错任务特点进行模型设计。如何根据语法纠错中输入语句和生成语句相近这一特性提出对应的模型也是一大挑战。
总结
语法纠错是NLP领域的一个重要研究课题,目前研究者们通常采用机器翻译的Seq2Seq方法来进行自动纠错。针对数据缺乏等问题,研究者提出了多种数据扩充方法,并在语法纠错任务上取得了不错的进展。同时部分研究者根据语法纠错输入语句和生成语句相近这一特点,提出了一些针对性的模型,也取得了很好的效果。目前语法纠错任务仍然有速度慢、数据量不足等问题,相信随着深度学习和NLP技术的快速发展,这些问题都将获得较好的解决。
参考文献
[1] Liang Wang, Wei Zhao, Ruoyu Jia, Sujian Li, Jingming Liu. Denoising based Sequence-to-Sequence Pre-training for Text Generation. EMNLP 2019.
[2] Jared Lichtarge, Chris Alberti, Shankar Kumar, Noam Shazeer, Niki Parmar, Simon Tong. Corpora Generation for Grammatical Error Correction. NAACL 2019.
[3] Tao Ge, Furu Wei, Ming Zhou. Fluency Boost Learning and Inference for Neural Grammatical Error Correction. ACL 2018.
[4] Wei Zhao, Liang Wang, Kewei Shen, Ruoyu Jia, Jingming Liu. Improving Grammatical Error Correction via Pre-Training a Copy-Augmented Architecture with Unlabeled Data. NAACL 2019.
[5] Eric Malmi, Sebastian Krause, Sascha Rothe, Daniil Mirylenka, Aliaksei Severyn. Encode, Tag, Realize: High-Precision Text Editing. EMNLP 2019.
[6] Abhijeet Awasthi, Sunita Sarawagi, Rasna Goyal, Sabyasachi Ghosh, Vihari Piratla. Parallel Iterative Edit Models for Local Sequence Transduction. EMNLP 2019.