MySql语句------select查询语句关键字
select语句关键字
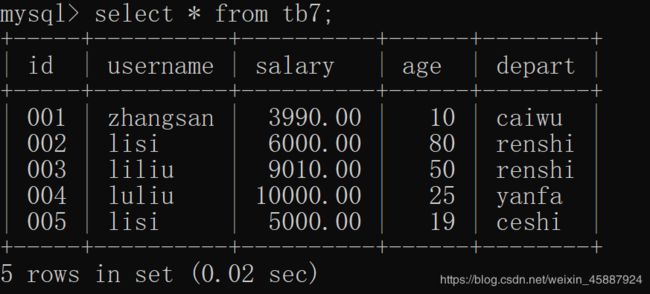
表名:tb7
使用查询语句select * from tb7;
其中*表示查询表中所有内容。
单关系查询
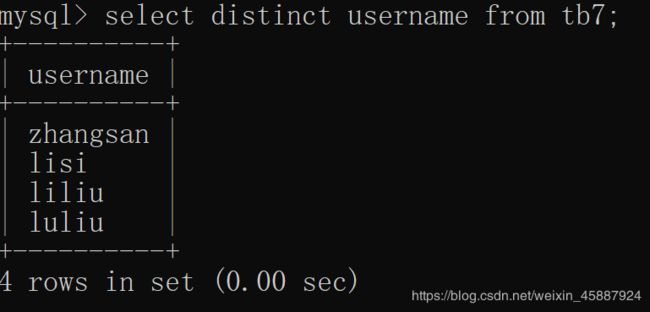
distinct:
去重复,对于所查询的内容,如果出现相同的记录,就只保留一条记录。
select distinct username from tb7;
all:
再select后面加all表示不去重复,select语句默认也是all
select all username from tb7;

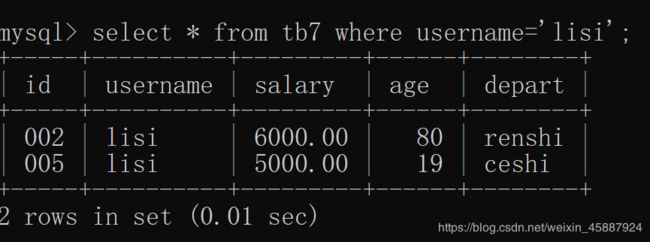
where:
后跟查询需要满足的条件
select * from tb7 where username='lisi';
and:
用于where之后表示将判断条件连接起来,即查询同时满足and连接的所有条件
select * from tb7 where username='lisi' and salary=6000.00;

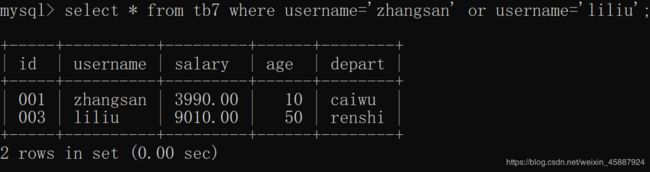
or:
在where后使用表示判断条件多选一,即查询满足where后条件中的一个即可
select * from tb7 where username='zhangsan' or username='liliu';
not:
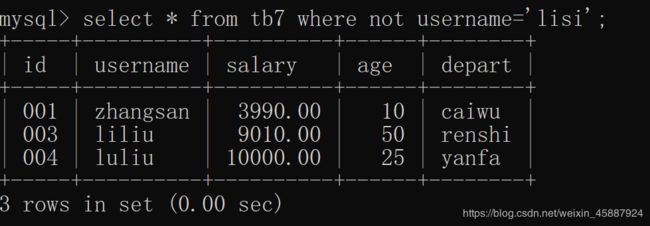
在where之后使用,表示查询not后条件的取反结果
select * from tb7 where not username='lisi';
聚集函数运算查询
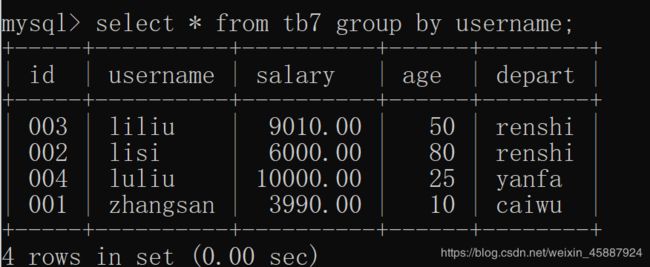
group by:
将在group by上取值相同的信息分在一个组里
select * from tb7 group by username;
having:
对group by产生的分组进行筛选,可以使用聚集函数
select * from tb7 group by username having username='lisi';

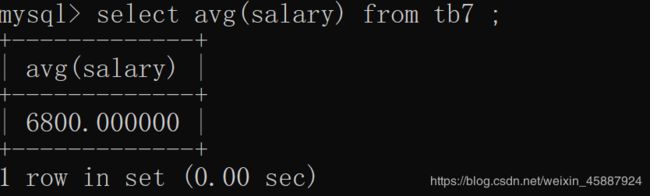
avg:
平均值函数,
用于select前作为查询条件
用于having后,作为判断条件一般和group by连用
select avg(salary) from tb7 ;
select * from tb7 group by id having avg(salary)>5000;

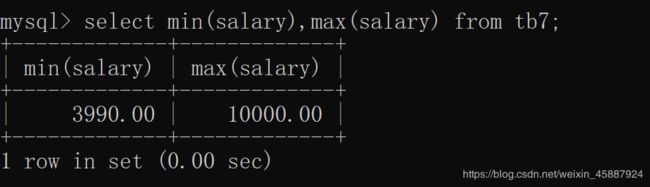
min、max:
最小最大值函数
select min(salary),max(salary) from tb7;
select * from tb7 group by id having min(salary)>5000;

sum:
求和函数
select sum(salary) from tb7;

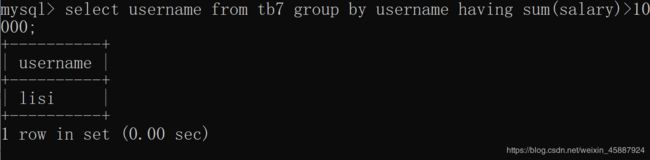
select name from tb7 group by username having sum(salary)>10000;
count:
计数函数
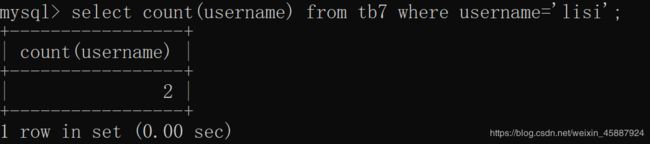
select count(username) from tb7 where username='lisi';
select count(username) from tb7 where username='lisi';
select count(*) from tb7 where username like 'li%';

附加值查询
as:
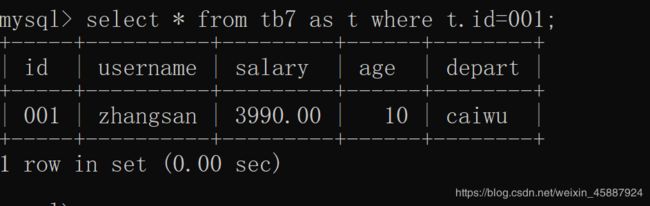
给as前的关系起一个别名,在此语句中,用别名代替此表
select * from tb7 as t where t.id=001;
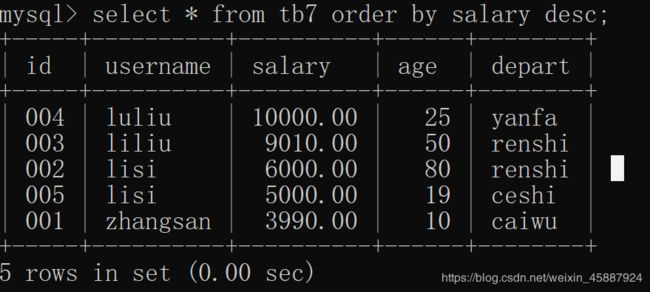
order by:
对查询结果进行排序
desc表示降序
asc表示升序(默认)
select * from tb7 order by salary desc;