Hadoop实战之路——第二章 Hadoop集群实验环境安装
所谓“万事开头难”,Hadoop集群实验环境的安装放倒了不少新手,没有安装好实验环境导致后面的内容没法学习,于是乎只有放弃了。Hadoop的运行模式主要有三种:
• 单机模式。默认情况下,Hadoop被配置成以非分布式模式运行的一个独立Java进程。这对调试非常有帮助。
• 伪分布式模式。Hadoop可以在单节点上以所谓的伪分布式模式运行,此时每一个Hadoop守护进程都作为一个独立的Java进程运行。
• 完全分布式模式。具有实际意义的Hadoop集群,其规模可从几个节点的小集群到几千个节点的超大集群。
2.1 Hadoop1.x的完全分布式实验环境安装
首先说明一下,下面的安装过程仅供参考学习,不考虑优化。
2.1.1 硬件环境
处理器:二核1.7G+ 硬盘:40G+ 内存:768M+ 网络:局域网
2.1.2 软件环境
(1) JDK:Java 6+,可以从Oracle官网下载Linux版本。
(2) Hadoop1.x:可以从Hadoop官网http://hadoop.apache.org/core/releases.html
(3) 操作系统:CentOS,下载地址:http://isoredirect.centos.org/centos/6.5/isos/
2.1.3 安装过程
(1) 安装3台搭载CentOS的主机,也可以用虚拟主机,并保证每台主机上有统一的登录名,如hadoop,相同的目录结构。
1)更改hostname,将每台主机名改成便于管理的名字:vi /etc/sysconfig/network 修改hostname
2)更改hosts,在作为namenode节点的主机上配置IP与主机名的对应关系:vi /etc/hosts,如:
172.16.51.204 master204
172.16.51.214 slaver214
172.16.51.217 slaver217
3)关闭防火墙
service iptables stop
chkconfig iptables off
(2) 安装JDK
在每台主机上安装JDK,使用PieTTY 0.3.26登录CentOS,可直接使用root用户登录(仅为了学习的方便,不产生更多障碍,生产环境中不建议)。要安装JDK需把准备好的jdk-7u55-linux-x64.tar.gz放到Linux系统中,当然可以采用wget方法直接下载,也可采用WinSCP上传。说下WinSCP的文件上传吧。
step1:下载安装WinSCP,如果不会下载安装,先百度啦。
step2:打开WinSCP,如图2-1:
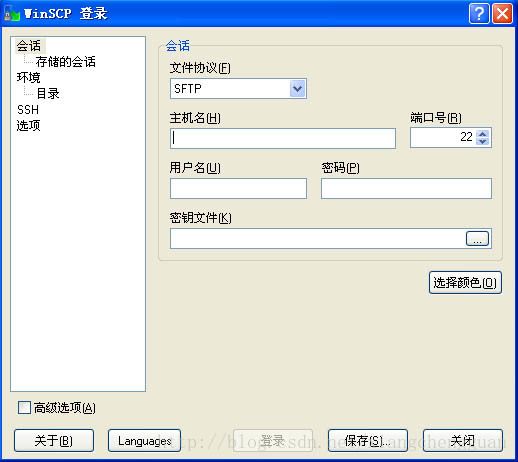
图2-1 WinSCP界面
step3:在主机名处输入主机的IP地址,也可输入名(但需要设置hosts),输入root及登录密码,单击“登录”按钮,出现如图2-2:

图2-2 WinSCP操作界面
note:左侧圆角框所示为本地Windows系统目录结构,右侧直角框所示为Linux目录结构。
step4:在左侧找到等上传的jdk-7u55-linux-x64.tar.gz,在右侧找到目标位置,这里选择的是/usr/local目录,将左侧的jdk-7u55-linux-x64.tar.gz拖至右侧即可。
接下来的工作就是到Linux系统上安装JDK啦,找到/usr/local目录,命令:
cd /usr/local
1) 用ls查看一下目录下的文件,确认jdk-7u55-linux-x64.tar.gz已经存在后,使用命令:
tar -zxvf jdk-7u55-linux-x64.tar.gz
2) 配置JAVA环境变量
step1:vi /etc/profile
step2:按下i键进入编辑模式,加入以下内容:
export JAVA_HOME=/usr/local/jdk1.1.0_55
export PATH=.:$JAVA_HOME/bin:$PATH
step3:按ESC键后再输入:wq保存退出。
step4:使用source命令在当前bash环境下读取并执行profile中的命令,如下:
source /etc/profile
step5:确认,使用java -version出现面2-3的界面说明JDK安装成功。

图2-3 java -version效果
(3) 配置hosts
vi /etc/hosts
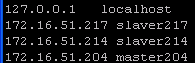
说明:slaver217,slaver214作为datanode节点,master204作为namenode节点。另外,各datanode节点主机上只需配置如:172.16.51.214 slaver214。
(4) 安装Hadoop1.x
1) 使用WinSCP将hadoop-1.1.2.tar.gz上传至Linux服务器/usr/local目录下。
2) 登录Linux系统后,进入/usr/local目录下,命令:
cd /usr/local
3) 解压hadoop-1.1.2.tar.gz,命令:
tar -zxvf hadoop-1.1.2.tar.gz
解压后可将文件夹名称hadoop-1.1.2改为hadoop1,命令:mv hadoop-1.1.2 hadoop1
4) 配置环境变量
vi /etc/profile
加入:
export HADOOP_HOME=/usr/local/hadoop1
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
验证:命令hadoop
5) 配置Hadoop的hadoop-env.sh
进入到目录/usr/local/hadoop/conf,命令:cd /usr/local/hadoop/conf
ls后如图2-4所示。
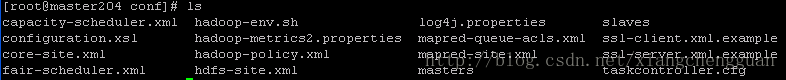
图2-4 conf目录结构
vi hadoop-env.sh
找到行export JAVA_HOME所在行,去掉注释#,将其改为:export JAVA_HOME=/usr/local/jdk1.7.0_55,保存退出。
6) 配置core-site.xml
vi core-site.xml
配置如下:
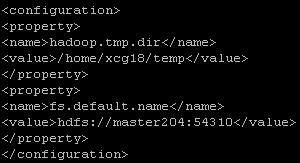
说明:hadoop.tmp.dir hadoop文件系统依赖的基础配置,很多路径都依赖它,如果指定的目录不存在,要及时建立(mkdir命令)
fs.default.name NameNode的名称(IP地址)和端口号
7) 配置hdfs-site.xml
vi hdfs-site.xml
配置如下:
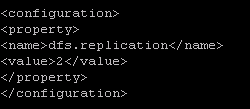
说明:dfs.repliction 文件备份系数,就不大于datanode数。
8) 配置mapred-site.xml
vi mapred-site.xml
配置如下:
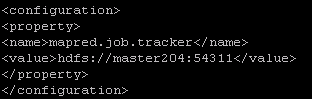
说明:mapred.job.tracker 连接jobtrack服务器的配置项,默认不写是local,map数1,reduce数1。
9) 配置masters文件
vi master
将localhost改为namenode结点的主机名或IP,这里我使用的是master204。
10) 配置slaves文件
vi slaves
将localhost去掉,加入作为datanode节点的主机名或IP,一个主机名占(IP)占一行。
10) 复制配置好的hadoop/到各datanode主机的同名文件夹下,确保目录结构与namenode机一致。命令:
scp -r /usr/local/hadoop1 root@slaver214:/usr/local/local/hadoop1
scp -r /usr/local/hadoop1 root@slaver217:/usr/local/local/hadoop1
(5) 设置ssh登录(很关键)
在namenode主机上,我这里用的是master204,进入目录root下,命令:
cd /root
ssh-keygen -t rsa
一路回车,生成id_rsa.pub等文件。
chmod 0700 .ssh
用命令ls -a查看,存在.ssh文件夹,如下:

cd .ssh
![]()
在各datanode节点主机下也作相同的工作。
将id_rsa.pub拷贝到各datanode节点的相同目录下,执行touch /root/.ssh/authorized_keys (如果已经存在这个文件, 跳过这条),chmod 600 ~/.ssh/authorized_keys (# 注意: 必须将~/.ssh/authorized_keys的权限改为600, 该文件用于保存ssh客户端生成的公钥,可以修改服务器的ssh服务端配置文件/etc/ssh/sshd_config来指定其他文件名),cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys (将id_rsa.pub的内容追加到 authorized_keys 中, 注意不要用 > ,否则会清空原有的内容,使其他人无法使用原有的密钥登录)
验证: ssh slaver214
成功情况如下所示:

(6) 格式化namenode
hadoop namenode -format
观察各datanode节点是否正常。
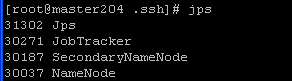
(7) 启动HDFS,命令:start-all.sh,验证进程,用命令jps,成功启动时应该有5个进程。
namenode节点上的进程如下:
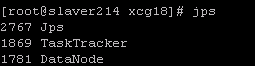
datanode节点上的进程如下:
还可以在浏览器中输入:http://172.16.51.204:50070,出现如下的界面说明安装成功。

在浏览器中输入:http://172.16.51.204:50030,出现如下界面。

2.2 Hadoop2.x的完全分布式实验环境安装
在安装Hadoop2.x时,安装JDK(32-bit)、配置hosts、配置hostname、关闭防火墙与安装hadoop1.x相同的。不过要强调一下,下面的安装是基于32-bit的centOS(在64-bit下安装Hadoop2.x需要重新编译Hadoop),这里就从Hadoop2.x安装开始。
因为namenode与各datanode的配置相同,故在namenode节点主机上安装好后,再复制到各datanode节点主机。
2.2.1 Hadoop2.x的获取
下载地址:http://apache.claz.org/hadoop/common/hadoop-2.2.0/
将下载的hadoop-2.2.0.tar.gz上传至namenode节点主机的/usr/local目录下,也可直接用wget命令下载到此目录下。wget http://apache.claz.org/hadoop/common/hadoop-2.2.0/
2.2.2 解压hadoop-2.2.0.tar.gz
(1) 解压
tar -zxvf hadoop-2.2.0.tar.gz
(2) 重命名文件夹hadoop-2.2.0为hadoop2
mv hadoop-2.2.0 hadoop2
(3) 进入hadoop2文件夹,建data、name、tmp文件夹
cd hadoop2
mkdir data
mkdir name
mkdir tmp
[root@master101 hadoop2]# ls
bin data etc include lib libexec LICENSE.txt name NOTICE.txt README.txt sbin share tmp
2.2.3 修改Hadoop配置文件
配置HADOOP_HOME,命令:
[root@master101 hadoop]# vi /etc/profile
加入:export HADOOP_HOME=/usr/local/hadoop2
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:PATH
Hadoop2.x需要修改的配置文件有7个,都存放于hadoop2/etc/hadoop目录下,下面一一介绍各配置文件的配置。
(1) hadoop-env.sh
[root@master101 hadoop]# vi hadoop-env.sh
找到JAVA_HOME所在行,配置JAVA_HOME。如下:
export JAVA_HOME=/usr/local/jdk1.7.0_55
(2) yarn-env.sh
[root@master101 hadoop]# vi yarn-env.sh
找到JAVA_HOME所在行,配置JAVA_HOME。如下:
export JAVA_HOME=/usr/local/jdk1.7.0_55
(3) slaves
[root@master101 hadoop]# vi slaves
加入datanode节点主机的IP或hostname
slaver102
slaver103
slaver104
(4) core-site.xml
[root@master101 hadoop]# vi core-site.xml
(5) hdfs-site.xml
[root@master101 hadoop]# vi hdfs-site.xml
(6) mapred-site.xml
这个文件不存在时,可以通过[root@master101 hadoop]# cp mapred-site.xml.template mapred-site.xml复制
(7) yarn-site.xml
[root@master101 hadoop]# vi yarn-site.xml
2.2.4 分发Hadoop至各datanode节点主机
[root@master101 local]# scp -r ./hadoop2 root@slaver102:/usr/local/hadoop2
[root@master101 local]# scp -r ./hadoop2 root@slaver103:/usr/local/hadoop2
[root@master101 local]# scp -r ./hadoop2 root@slaver104:/usr/local/hadoop2
2.2.5 启动Hadoop集群
(1) 格式化namenode节点
在namenode节点进入hadoop2.x安装目录hadoop2,命令:
[root@master101 hadoop2]# ./bin/hdfs namenode -format
(2) 启动hfds
在namenode节点进入hadoop2.x安装目录hadoop2,命令:
[root@master101 hadoop2]# ./sbin/start-dfs.sh
Starting namenodes on [master101]
master101: starting namenode, logging to /usr/local/hadoop2/logs/hadoop-root-namenode-master101.out
slaver104: starting datanode, logging to /usr/local/hadoop2/logs/hadoop-root-datanode-slaver104.out
slaver103: starting datanode, logging to /usr/local/hadoop2/logs/hadoop-root-datanode-slaver103.out
slaver102: starting datanode, logging to /usr/local/hadoop2/logs/hadoop-root-datanode-slaver102.out
Starting secondary namenodes [master101]
master101: starting secondarynamenode, logging to /usr/local/hadoop2/logs/hadoop-root-secondarynamenode-master101.out
(3) 启动yarn
在namenode节点进入hadoop2.x安装目录hadoop2,命令:
[root@master101 hadoop2]# ./sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop2/logs/yarn-root-resourcemanager-master101.out
slaver103: starting nodemanager, logging to /usr/local/hadoop2/logs/yarn-root-nodemanager-slaver103.out
slaver102: starting nodemanager, logging to /usr/local/hadoop2/logs/yarn-root-nodemanager-slaver102.out
slaver104: starting nodemanager, logging to /usr/local/hadoop2/logs/yarn-root-nodemanager-slaver104.out
2.2.6 验证
在namenode节点主机master101上执行命令: [root@master101 hadoop2]# jps,存在以下进程:
ResourceManager
NameNode
SecondaryNameNode
在datanode节点主机slaver102、slaver103、slaver104上执行命令: [root@master101 hadoop2]# jps,存在以下进程:
DataNode
NodeManager