实现B-树的相关运算算法
B-tree即B树,B即Balance,平衡的意思。B-树是一种多路搜索树(并不一定是二叉的)。
当查找的文件较大,且存放在磁盘等直接存取设备中时,为了减少查找过程中对磁盘的读写次数,提高查找效率,基于直接存取设备的读写操作以"页"为单位的特征。
1970年,R.Bayer和E.M.McCreight提出了一种称之为B-树的多路平衡查找树,在文件系统中有所应用,主要用作文件的索引。它是一种平衡的多叉树,称为B树(或B-树、B_树),适合在磁盘等直接存取设备上组织动态的查找表。
1、B-树(B树)的基本概念
B-树中所有结点中孩子结点个数的最大值称为B-树的阶,通常用m表示,从查找效率考虑,一般要求m>=3。
B-树(B树)结构特性
一棵m阶B-树或者是一棵空树,或者是满足以下条件的m(m>=3)叉树:
(1)根结点只有1个,关键字字数的范围[1,m-1],分支个数取值范围[2,m]
(2)每个中间节点都包含k-1个元素和k个孩子,其中 m/2 <= k <= m
(3)每一个叶子节点都包含k-1个元素,其中 m/2 <= k <= m,即每一个叶子结点最多包含m-1个关键字
(4)所有的叶子结点都位于同一层,并且不带信息(可以看作是外部结点或查找失败的结点,实际上这些结点不存在,指向这些结点的指针为空)。即所有叶子节点具有相同的深度,等于树高度。如一棵四阶B-树,其深度为4
(5)每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域分划
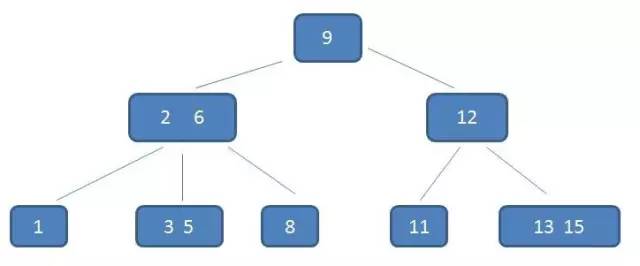
这棵三阶B-树符合上述所列的特征。
⑴树中每个结点至多有m 棵子树
⑵若根结点不是叶子结点,则至少有两棵子树
⑶除根结点之外的所有非叶子结点至少有[m/2] 棵子树
⑷所有的非叶子结点中包含以下信息数据:
(n,A0,K1,A1,K2,A2,…,Kn,An)
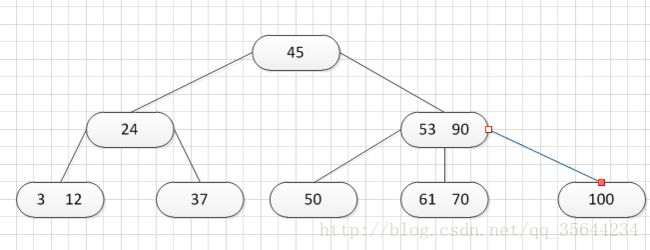
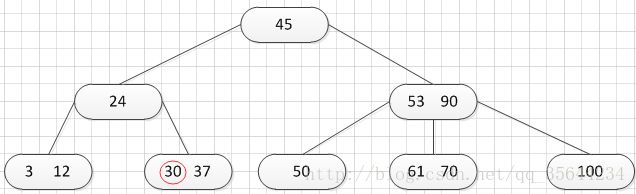
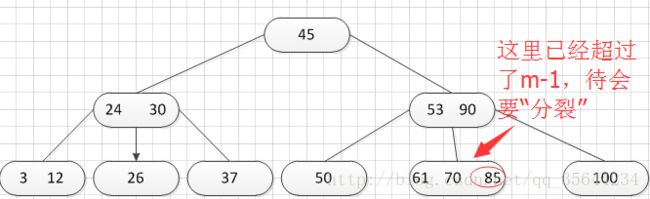
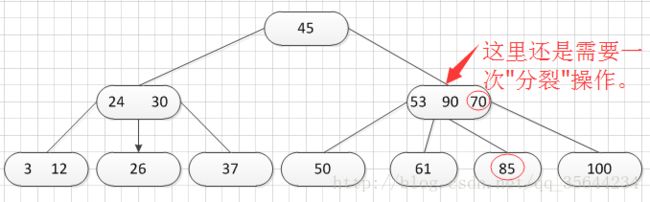
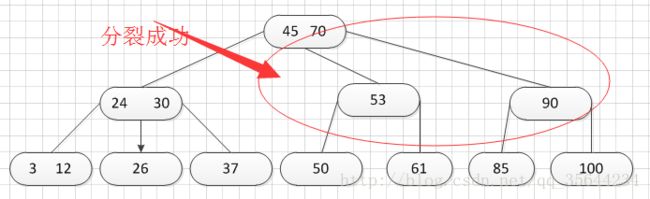
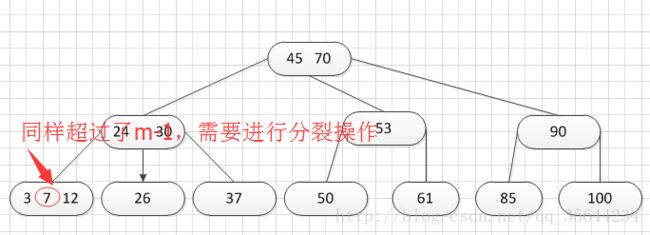
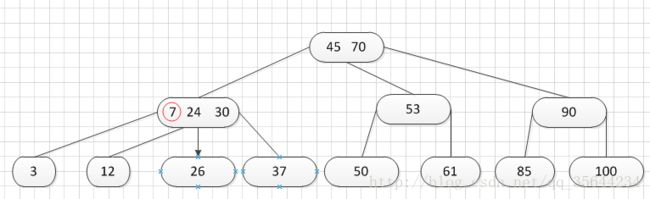
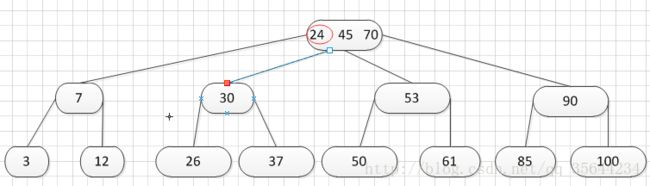
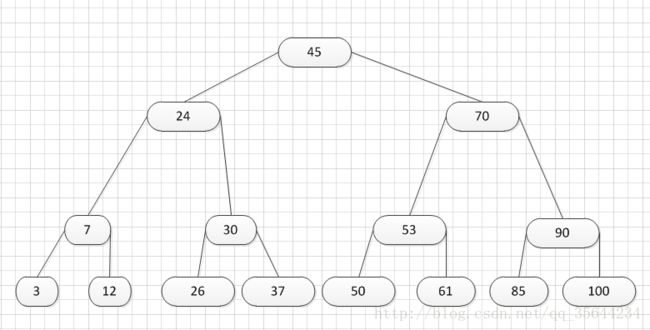
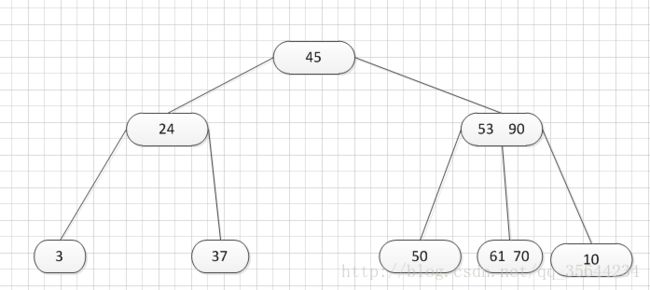
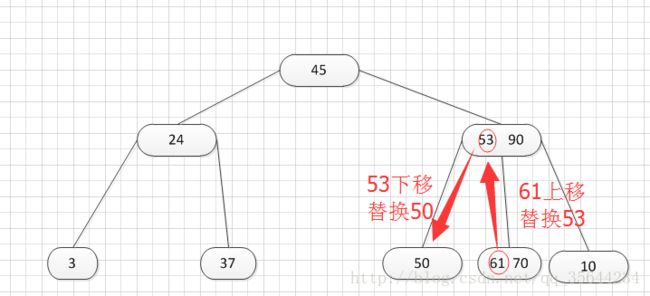
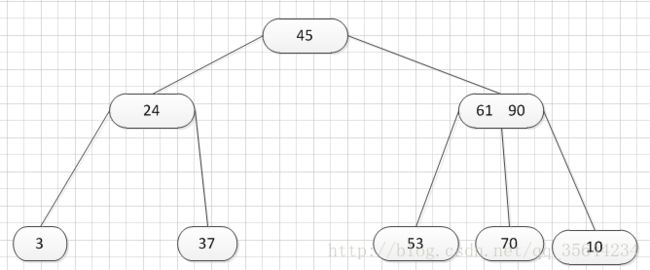
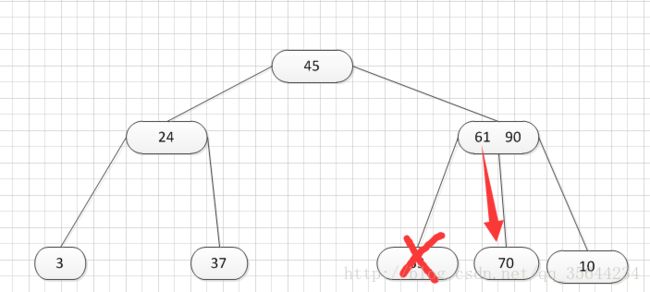
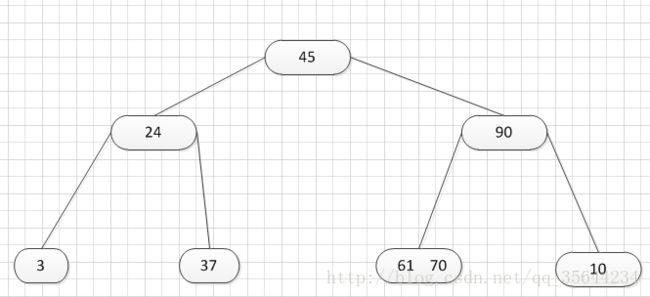
其中:Ki(i=1,2,…,n)为关键码,且k1 2、B-树的基本操作-查找介绍 B-树的查找类似二叉排序树的查找,所不同的是B-树每个结点上是多关键码的有序表,在到达某个结点时,先在有序表中查找,若找到,则查找成功;否则,到按照对应的指针信息指向的子树中去查找,当到达叶子结点时,则说明树中没有对应的关键码。 给出如下的一棵4阶(B-树中所有结点中孩子结点个数的最大值)的B-树结构: 这是一个4阶的B-树,假设需要查找45这个数是否在B-树中。 1)从根结点出发,发现根结点a有1个关键字为35,其中45>35,往右子树走,进入结点c 2)发现结点c有2个关键字,其中43<45<78,所以进入结点g 3)发现结点g有3个关键字,其中3<45<47,所以继续往下走,发现进入了结束符结点:F,所以45不在B-树中 从上述的查找的过程可以得出,在B-树的查找过程为: 1)B-树中查找结点 2)在结点中查找关键字 由于B- 树通常存储在磁盘上, 则前一查找操作是在磁盘上进行的, 而后一查找操作是在内存中进行的,即 在磁盘上找到指针p 所指结点后, 先将结点中的信息读入内存, 然后再利用顺序查找或折半查找查询等于K 的关键字。显然, 在磁盘上进行一次查找比在内存中进行一次查找的时间消耗多得多。 因此, 在磁盘上进行查找的次数、即待查找关键字所在结点在B-树上的层次数, 是决定B树查找效率的首要 因素,对于有n个关键字的m阶B-树,从根结点到关键字所在结点的路径上路过的结点数不超过: 3、B-树的插入 B-树的插入,主要分为如下两个步骤: 1)使用查找算法查找出关键字的插入位置,如果在B-树中查找到了关键字,则直接返回。否则,它一定会失败在某个最底层的终端结点上。 2)然后,判断那个终端结点上的关键字数量是否满足:n<=m-1,如果满足的话,直接在该终端结点上添加一个关键字,否则,需要产生结点的“分裂”。 分裂的方法是:生成一新结点。把原结点上的关键字和需要插入的值key按升序排序后,从中间位置把关键字(不包括中间位置的关键字)分成两部分。左部分所含关键字放在旧结点中,右部分所含关键字放在新结点中,中间位置的关键字连同新结点的存储位置插入到父结点中。如果父结点的关键字个数也超过(m-1),则要再分裂,再往上插。直至这个过程传到根结点为止。 举例说明,假设这个B-树的阶为:3。树的初始化时如下: 首先,插入一个关键字:30,得到如下结果: 再插入26,得到如下结果: 此时如图所示,在插入的终端结点中,它的关键字数已经超过了m-1=2,需要对结点进分裂,先对关键字排序,得到:26 30 37 ,所以左部分为(不包括中间值):26,中间值为:30,右部分为:37,左部分放在原来的结点,右部分放入新的结点,而中间值则插入到父结点,并且父结点会产生一个新的指向子树的指针,指向新的结点的位置,如下图所示: 继续插入新的关键字:85,得到如下结果: 此时如图所示,在插入的终端结点中,它的关键字数已经超过了m-1=2,需要对结点进分裂,先对关键字排序,得到:61 70 85 ,所以左部分为(不包括中间值):61,中间值为:70,右部分为:85,左部分放在原来的结点,右部分放入新的结点,而中间值则插入到父结点,如下图所示: 结点的度:结点拥有的子树数。 当分裂完后,发现之前的那个结点的父亲结点的度为4,说明它的关键字数超过了m-1,所以需要对其父结点进行“分裂”操作,得到如下的结果: 继续插入一个新的关键字:7,得到如下结果: 同样,需要对新的结点进行分裂操作,得到如下的结果: 到了这里,需要继续对父亲结点进行分裂操作,因为它的关键字数超过了:m-1 此时,根结点关键字数量超过m-1,需要对父亲结点进行分裂操作,但是根结点不存在父亲结点,需要重新创建根结点。 4、B-树的删除操作 B-树的删除操作分为两个步骤: 1、利用B-树的查找算法找出该关键字所在的结点,然后根据 k(需要删除的关键字)所在结点是否为叶子结点有不同的处理方法。如果没有找到,则直接返回。 2、若该结点为非叶子结点,且被删关键字为该结点中第i个关键字key[i],则可从指针son[i]所指的子树中找出最小关键字min_key,代替key[i]的位置,然后在叶子结点中删去min_key。 如果是叶子结点,分下面三种情况删除: 1、如果被删关键字所在结点的原关键字个数n>=[m/2] ( 上取整),说明删去该关键字后该结点仍满足B-树的定义。这种情况最为简单,只需删除对应的关键字:k和指针:A 即可。 关键字的个数不小于(向上取整:不管四舍五入的规则, 只要后面有小数前面的整数就加1)[m/2],如下图删除关键字:12 删除12后的结果如下,只是简单的删除关键字12和其对应的指针。 2、如果被删关键字所在结点的关键字个数n等于( 向上取整)[ m/2 ]-1,说明删去该关键字后该结点将不满足B-树的定义,需要调整。 调整过程为: 如果其左右兄弟结点中有“多余”的关键字,即与该结点相邻的右兄弟(或左兄弟)结点中的关键字数目大于( 向上取整)[m/2]-1。则可将右兄弟(或左兄弟)结点中最小关键字(或最大的关键字)上移至双亲结点。而将双亲结点中小(大)于该上移关键字的关键字下移至被删关键字所在结点中。 关键字个数n等于( 向上取整)[ m/2 ]-1,而且该结点相邻的右兄弟(或左兄弟)结点中的关键字数目大于( 向上取整)[m/2]-1。 如上图所示,要删除关键字50,需要把50的右兄弟中最小的关键字:61上移到其父结点,然后替换小于61的关键字53的位置,53则放至50的结点中。得到如下的结果: 3、被删关键字所在结点和其相邻的兄弟结点中的关键字数目均等于(向上取整)[m/2]-1。假设该结点有右兄弟,且其右兄弟结点地址由双亲结点中的指针Ai所指,则在删去关键字之后,它所在结点中剩余的关键字和指针,加上双亲结点中的关键字Ki一起,合并到 Ai所指兄弟结点中(若没有右兄弟,则合并至左兄弟结点中)。 关键字个数n等于( 向上取整)[ m/2 ]-1,而且被删关键字所在结点和其相邻的兄弟结点中的关键字数目均等于(向上取整)[m/2]-1 如上图所示,要删除关键字53,就要把53所在结点的其他关键字(这里没有其他关键字了)和父亲结点的关键字61一起合并到关键字70所在的结点。得到如下所示的结果: /** #include #define MAX_M 10 //定义B-树的最大的阶数 typedef int key_type; //KeyType为关键字类型 /*----------------------------以下定义为全局变量----------------------------*/ /** for(i = 0; i < p->keynum && p->key[i + 1] <= k; i++); /** while (p != NULL && found == 0) r.i = i; return r; //返回k的位置(或插入位置) /** for(j = q->keynum; j > i; j--) //空出一个位置 /** int i, s = (m + 1) / 2; ap = (b_tree_node *)malloc(sizeof(b_tree_node)); //生成新结点*ap ap->ptr[0] = q->ptr[s]; //后一半移入ap /** t->keynum = 1; /** if (q == NULL) //t是空树(参数q初值为NULL) /** if(t != NULL) printf("%d", t->key[i]); if(t->keynum > 0) for(i = 0; i < t->keynum; i++) //对每个子树进行递归调用 /** for(j = i + 1; j <= p->keynum; j++) //前移删除key[i]和ptr[i] /** for (q = p->ptr[i]; q->ptr[0] != NULL; q = q->ptr[0]); /** b_tree_node *t = p->ptr[i]; /** b_tree_node *t; t = p->ptr[i]; //把右兄弟中的关键字移动到双亲兄弟中 /** b_tree_node *q = p->ptr[i]; //指向右结点,它将被置空和删除 /** if(p == NULL) /** int main(void) k = 1; return 0; 创建一棵3阶B-树: n为关键码的个数。
n为关键码的个数。
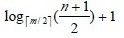


* 实验题目:
* 实现B-树的相关运算算法
* 实验内容:
* 编写程序实现B-树的相关运算,在此基础上完成如下功能:
* 1、由{4, 9, 0, 1, 8, 6, 3, 5, 2, 7}创建一颗B-树,并以括号表示法输出。
* 2、在b中分别删除关键字为8和1的结点,并以括号表示法输出删除后的B-树。
*/
#include
typedef struct node //B-树结点类型定义
{
int keynum; //结点当前拥有的关键字的个数
key_type key[MAX_M]; //key[1..keynum]存放关键字,key[0]不用
struct node *parent; //双亲结点指针
struct node *ptr[MAX_M]; //孩子结点指针数组ptr[0..keynum]
}b_tree_node;
typedef struct //B-树的查找结果类型
{
b_tree_node *pt; //指向找到的结点
int i; //1..m,在结点中的关键字序号
int tag; //1:查找成功,0:查找失败
}result;
int m; //m阶B-树,为全局变量
int Max; //m阶B-树中每个结点的至多关键字个数,Max=m-1
int Min; //m阶B-树中非叶子结点的至少关键字个数,Min=(m-1)/2
* 功能:
* 在p->key[1...keynum]中查找i,使得p->key[i] <= k < p->key[i + 1]
*
*/
static int search1(b_tree_node *p, key_type k)
{
int i = 0;
return i;
}
* 功能:
* 在m阶B-树t上查找关键字key,返回结果(pt, i, tag)。
* 若查找成功,则标志tag = 1,指针pt所指结点中第i个关键
* 字等于k;否则标志tag = 0,等于k的关键字应插入在指针pt
* 所指结点中第i个和第(i + 1)个关键字之间。
*
*/
static result search_b_tree(b_tree_node *t, key_type k)
{
b_tree_node *p = t, *q = NULL; //初始化,p指向待查结点,q指向p的双亲
int found = 0, i = 0;
result r;
{
i = search1(p, k); //在p->key[1..keynum]中查找i,使得p->key[i]<=k
if (i > 0 && p->key[i] == k) //找到待查关键字
found = 1;
else
{
q = p;
p = p->ptr[i];
}
}
if (found == 1) //查找成功
{
r.pt = p;
r.tag = 1;
}
else //查找不成功,返回K的插入位置信息
{
r.pt = q;
r.tag = 0;
}
}
* 功能:
* 将x和ap分别插入到q->key[i + 1]和q->ptr[i + 1]中
*/
static void insert1(b_tree_node *&q, int i, key_type x, b_tree_node *ap)
{
int j;
{
q->key[j + 1] = q->key[j];
q->ptr[j + 1] = q->ptr[j];
}
q->key[i + 1] = x;
q->ptr[i + 1] = ap;
if (ap != NULL)
ap->parent = q;
q->keynum++;
}
* 功能:
* 将结点q分成两个结点,前一半保留,后一半移入新生结点ap
*/
static void split(b_tree_node *&q, b_tree_node *&ap)
{
if(ap == NULL)
{
printf("split: 分配内存失败!\n");
return;
}
for (i = s + 1; i <= m; i++)
{
ap->key[i - s] = q->key[i];
ap->ptr[i - s] = q->ptr[i];
if(ap->ptr[i - s] != NULL)
ap->ptr[i - s]->parent = ap;
}
ap->keynum = q->keynum - s;
ap->parent = q->parent;
for (i = 0; i <= q->keynum - s; i++) //修改指向双亲结点的指针
if (ap->ptr[i] != NULL)
ap->ptr[i]->parent = ap;
q->keynum = s - 1; //q的前一半保留,修改keynum
}
* 功能:
* 生成含信息(t, x, ap)的新的根结点*t,原t和ap为子树指针
*/
static void create_new_root(b_tree_node *&t, b_tree_node *p, key_type x, b_tree_node *ap)
{
t = (b_tree_node *)malloc(sizeof(b_tree_node));
if(t == NULL)
{
printf("create_new_root: 分配内存失败!\n");
return;
}
t->ptr[0] = p;
t->ptr[1] = ap;
t->key[1] = x;
if (p != NULL)
p->parent = t;
if (ap != NULL)
ap->parent = t;
t->parent = NULL;
}
* 功能:
* 在m阶B-树t上结点*q的key[i]与key[i + 1]之间插入关键字k。
* 若引起结点过大,则沿双亲链进行必要的结点分裂调整,使得t仍是一
* 棵m阶B-树。
*/
static void insert_b_tree(b_tree_node *&t, key_type k, b_tree_node *q, int i)
{
b_tree_node *ap;
int finished, need_new_root, s;
key_type x;
create_new_root(t, NULL, k, NULL); //生成仅含关键字k的根结点*t
else
{
x = k;
ap = NULL;
finished = need_new_root = 0;
while (need_new_root == 0 && finished == 0)
{
insert1(q, i, x, ap); //将x和ap分别插入到q->key[i+1]和q->ptr[i+1]
if (q->keynum <= Max) finished = 1; //插入完成
else
{
s = (m + 1) / 2;
split(q, ap);
x = q->key[s];
if (q->parent) //在双亲结点*q中查找x的插入位置
{
q = q->parent;
i = search1(q, x);
}
else
need_new_root = 1;
}
}
if (need_new_root == 1) //根结点已分裂为结点*q和*ap
create_new_root(t, q, x, ap); //生成新根结点*t,q和ap为子树指针
}
}
* 功能:
* 以扩号表示法输出B-树
*/
static void display_b_tree(b_tree_node *t)
{
int i; //循环变量
{
printf("["); //输出当前结点关键字
for(i = 1; i < t->keynum; i++)
printf("%d ", t->key[i]);
printf("]");
{
if(t->ptr[0] != 0) //至少有一个子树时输出"("号
printf("(");
{
display_b_tree(t->ptr[i]); //对前两个子树进行递归调用
if(t->ptr[i + 1] != NULL) //子树之间的结点用,分割
printf(",");
}
display_b_tree(t->ptr[t->keynum]); //对最后一个子树进行递归调用
if(t->ptr[0] != 0) //至少有一个子树时输出")"号
printf(")");
}
}
}
* 功能:
* 从*p结点删除key[i]和它的孩子指针ptr[i]
*/
static void remove_node(b_tree_node *p, int i)
{
int j;
{
p->key[j - 1] = p->key[j];
p->ptr[j - 1] = p->ptr[j];
}
p->keynum--;
}
* 功能:
* 查找被删关键字p->key[i](在非叶子结点中)的替代叶子结点
*/
static void successor(b_tree_node *p, int i)
{
b_tree_node *q;
p->key[i] = q->key[1]; //复制关键字值
}
* 功能:
* 将一个关键字移动到右兄弟中
*/
static void move_right(b_tree_node *p, int i)
{
int c;
for (c = t->keynum; c > 0; c--) //将右兄弟中所有关键字移动一位
{
t->key[c + 1] = t->key[c];
t->ptr[c + 1] = t->ptr[c];
}
t->ptr[1] = t->ptr[0]; //从双亲结点移动关键字到右兄弟中
t->keynum++;
t->key[1] = p->key[i];
t = p->ptr[i - 1]; //将左兄弟中最后一个关键字移动到双亲结点中
p->key[i] = t->key[t->keynum];
p->ptr[i]->ptr[0] = t->ptr[t->keynum];
t->keynum--;
}
* 功能:
* 将一个关键字移动到左兄弟中
*/
static void move_left(b_tree_node *p, int i)
{
int c;
t = p->ptr[i - 1]; //把双亲结点中的关键字移动到左兄弟中
t->keynum++;
t->key[t->keynum] = p->key[i];
t->ptr[t->keynum] = p->ptr[i]->ptr[0];
p->key[i] = t->key[1];
p->ptr[0] = t->ptr[1];
t->keynum--;
for (c = 1; c <= t->keynum; c++) //将右兄弟中所有关键字移动一位
{
t->key[c] = t->key[c + 1];
t->ptr[c] = t->ptr[c + 1];
}
}
* 功能:
* 将三个结点合并到一个结点中
*/
static void combine(b_tree_node *p, int i)
{
int c;
b_tree_node *l = p->ptr[i - 1];
l->keynum++; //l指向左结点
l->key[l->keynum] =p->key[i];
l->ptr[l->keynum] = q->ptr[0];
for (c = 1; c <= q->keynum; c++) //插入右结点中的所有关键字
{
l->keynum++;
l->key[l->keynum] = q->key[c];
l->ptr[l->keynum] = q->ptr[c];
}
for (c = i; c < p->keynum; c++) //删除父结点所有的关键字
{
p->key[c] = p->key[c + 1];
p->ptr[c] = p->ptr[c + 1];
}
p->keynum--;
free(q); //释放空右结点的空间
}
/**
* 功能:
* 关键字删除后,调整B-树,找到一个关键字将其插入到p->ptr[i]中
*/
static void restore(b_tree_node *p, int i)
{
if (i == 0) //为最左边关键字的情况
if (p->ptr[1]->keynum > Min)
move_left(p, 1);
else
combine(p, 1);
else if (i == p->keynum) //为最右边关键字的情况
if (p->ptr[i - 1]->keynum > Min)
move_right(p, i);
else
combine(p, i);
else if (p->ptr[i - 1]->keynum > Min) //为其他情况
move_right(p, i);
else if (p->ptr[i + 1]->keynum > Min)
move_left(p, i + 1);
else
combine(p, i);
}
* 功能:
* 在结点p中查找关键字key的位置i,成功时返回1,否则返回0
*/
static int search_node(key_type key, b_tree_node *p, int &i)
{
if (key < p->key[1]) //k小于*p结点的最小关键字时返回0
{
i = 0;
return 0;
}
else //在*p结点中查找
{
i = p->keynum;
while (key < p->key[i] && i > 1)
i--;
return(key == p->key[i]);
}
}
/**
* 功能:
* 查找并删除关键字key
*/
static int rec_delete(key_type key, b_tree_node *p)
{
int i;
int found;
return 0;
else
{
if((found = search_node(key, p, i)) == 1) //查找关键字key
{
if(p->ptr[i-1] != NULL) //若为非叶子结点
{
successor(p, i); //由其后继代替它
rec_delete(p->key[i], p->ptr[i]); //p->key[i]在叶子结点中
}
else
remove_node(p, i); //从*p结点中位置i处删除关键字
}
else
found = rec_delete(key, p->ptr[i]); //沿孩子结点递归查找并删除关键字k
if (p->ptr[i] != NULL)
if (p->ptr[i]->keynum < Min) //删除后关键字个数小于MIN
restore(p, i);
return found;
}
}
* 功能:
* 从B-树root中删除关键字key,若在一个结点中删除指定的关键字后
* 不再有其他关键字,则删除该结点。
*/
static void delete_b_tree(key_type key, b_tree_node *&root)
{
b_tree_node *p;
//用于释放一个空的root
if(rec_delete(key, root) == 0)
printf(" 关键字%d不在B-树中\n", key);
else if(root->keynum == 0)
{
p = root;
root = root->ptr[0];
free(p);
}
}
{
b_tree_node *t = NULL;
result s;
int j;
int n = 10;
key_type a[] = {4, 9, 0, 1, 8, 6, 3, 5, 2, 7};
key_type k;
m = 3; //3阶B-树
Max = m - 1;
Min = (m - 1) / 2;
printf(" 创建一棵%d阶B-树:\n",m);
for (j = 0; j < n; j++) //创建一棵3阶B-树t
{
s = search_b_tree(t, a[j]);
if (s.tag == 0)
insert_b_tree(t, a[j], s.pt, s.i);
printf(" 第%d步,插入%d: ", j + 1, a[j]);
display_b_tree(t);
printf("\n");
}
printf(" 构造的B-树为: ");
display_b_tree(t);
printf("\n");
printf(" 删除操作:\n");
k = 8;
delete_b_tree(k, t);
printf(" 删除%d: ", k);
display_b_tree(t);
printf("\n");
delete_b_tree(k, t);
printf(" 删除%d: ", k);
display_b_tree(t);
printf("\n\n");
}
测试结果:
第1步,插入4: [4]
第2步,插入9: [4 9]
第3步,插入0: [4]([0],[9])
第4步,插入1: [4]([0 1],[9])
第5步,插入8: [4]([0 1],[8 9])
第6步,插入6: [4 8]([0 1],[6],[9])
第7步,插入3: [4]([1]([0],[3]),[8]([6],[9]))
第8步,插入5: [4]([1]([0],[3]),[8]([5 6],[9]))
第9步,插入2: [4]([1]([0],[2 3]),[8]([5 6],[9]))
第10步,插入7: [4]([1]([0],[2 3]),[6 8]([5],[7],[9]))
构造的B-树为: [4]([1]([0],[2 3]),[6 8]([5],[7],[9]))
删除操作:
删除8: [4]([1]([0],[2 3]),[6]([5],[7 9]))
删除1: [4]([2]([0],[3]),[6]([5],[7 9]))