SQL中IN和EXISTS用法的区别,sql中exists,not exists的用法
NOT IN
SELECT DISTINCT MD001 FROM BOMMD WHERE MD001 NOT IN (SELECT MC001 FROM BOMMC)
NOT EXISTS,exists的用法跟in不一样,一般都需要和子表进行关联,而且关联时,需要用索引,这样就可以加快速度
select DISTINCT MD001 from BOMMD WHERE NOT EXISTS (SELECT MC001 FROM BOMMC where BOMMC.MC001 = BOMMD.MD001)
exists是用来判断是否存在的,当exists(查询)中的查询存在结果时则返回真,否则返回假。not exists则相反。
exists做为where 条件时,是先对where 前的主查询询进行查询,然后用主查询的结果一个一个的代入exists的查询进行判断,如果为真则输出当前这一条主查询的结果,否则不输出。
in和exists
in 是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。一直以来认为exists比in效率高的说法是不准确的。
如果查询的两个表大小相当,那么用in和exists差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in:
例如:表A(小表),表B(大表)1:select * from A where cc in (select cc from B)
效率低,用到了A表上cc列的索引;select * from A where exists(select cc from B where cc=A.cc)
效率高,用到了B表上cc列的索引。
相反的2:select * from B where cc in (select cc from A)
效率高,用到了B表上cc列的索引;select * from B where exists(select cc from A where cc=B.cc)
效率低,用到了A表上cc列的索引。
not in 和not exists如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
in 与 =的区别
select name from student where name in ('zhang','wang','li','zhao');
与
select name from student where name='zhang' or name='li' or name='wang' or name='zhao'
的结果是相同的。
例子如下(即exists返回where后2个比较的where子句中相同值,not exists则返回where子句中不同值):
exists (sql 返回结果集为真)
not exists (sql 不返回结果集为真)
如下:
表A
ID NAME
1 A1
2 A2
3 A3
表B
ID AID NAME
1 1 B1
2 2 B2
3 2 B3
表A和表B是一对多的关系 A.ID --> B.AID
SELECT ID , NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE A.ID = B.AID)
执行结果为
1 A1
2 A2
原因可以按照如下分析
SELECT ID , NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID = 1)
-->SELECT * FROM B WHERE B.AID = 1有值返回真所以有数据
SELECT ID , NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID = 2)
-->SELECT * FROM B WHERE B.AID = 2有值返回真所以有数据
SELECT ID , NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID = 3)
-->SELECT * FROM B WHERE B.AID = 3无值返回真所以没有数据
NOT EXISTS 就是反过来
SELECT ID , NAME FROM A WHERE NOT EXIST (SELECT * FROM B WHERE A.ID = B.AID)
执行结果为
3 A3
sql in与exists区别
IN
确定给定的值是否与子查询或列表中的值相匹配。
EXISTS
指定一个子查询,检测行的存在。
比较使用 EXISTS 和 IN 的查询
这个例子比较了两个语义类似的查询。第一个查询使用 EXISTS 而第二个查询使用 IN。注意两个查询返回相同的信息。
USE pubs
Go
SELECT DISTINCT pub_name
FROM publishers
WHERE EXISTS
(SELECT *
FROM titles
WHERE pub_id = publishers.pub_id
AND type = 'business')
go
-- Or, using the IN clause:
USE pubs
GO
SELECT distinct pub_name
FROM publishers
WHERE pub_id IN
(SELECT pub_id
FROM titles
WHERE type = 'business')
GO
下面是任一查询的结果集:
pub_name
----------------------------------------
Algodata Infosystems
New Moon Books
(2 row(s) affected)
exits 相当于存在量词:表示集合存在,也就是集合不为空只作用一个集合.例如 exist P 表示P不空时为真; not exist P表示p为空时 为真 in表示一个标量和一元关系的关系。例如:s in P表示当s与P中的某个值相等时 为真; s not in P 表示s与P中的每一个值都不相等时 为真
in和exists
in 是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。
一直以来认为exists比in效率高的说法是不准确的。
如果查询的两个表大小相当,那么用in和exists差别不大。
全文:
in和exists
in 是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。
一直以来认为exists比in效率高的说法是不准确的。
如果查询的两个表大小相当,那么用in和exists差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in:
例如:表A(小表),表B(大表)
1:
select * from A where cc in (select cc from B)
效率低,用到了A表上cc列的索引;
select * from A where exists(select cc from B where cc=A.cc)
效率高,用到了B表上cc列的索引。
相反的
2:
select * from B where cc in (select cc from A)
效率高,用到了B表上cc列的索引;
select * from B where exists(select cc from A where cc=B.cc)
效率低,用到了A表上cc列的索引。
not in 和not exists
如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;
而not extsts 的子查询依然能用到表上的索引。
所以无论那个表大,用not exists都比not in要快。
in 与 =的区别
select name from student where name in ('zhang','wang','li','zhao');
与
select name from student where name='zhang' or name='li' or name='wang' or name='zhao'
的结果是相同的。
-----------------------------------------------------------------------------
- EXISTS用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False
- EXISTS 指定一个子查询,检测 行 的存在。
- 语法: EXISTS subquery
- 参数: subquery 是一个受限的 SELECT 语句 (不允许有 COMPUTE 子句和 INTO 关键字)。
- 结果类型: Boolean 如果子查询包含行,则返回 TRUE ,否则返回 FLASE 。
- SQL中EXISTS怎么用
- 2
- (一). 在子查询中使用 NULL 仍然返回结果集
- select * from TableIn where exists(select null)
- 等同于: select * from TableIn
- SQL中EXISTS怎么用
- 3
- (二). 比较使用 EXISTS 和 IN 的查询。注意两个查询返回相同的结果。
- select * from TableIn where exists(select BID from TableEx where BNAME=TableIn.ANAME)
- select * from TableIn where ANAME in(select BNAME from TableEx)
- SQL中EXISTS怎么用
- 4
- (三). 比较使用 EXISTS 和 = ANY 的查询。注意两个查询返回相同的结果。
- select * from TableIn where exists(select BID from TableEx where BNAME=TableIn.ANAME)
- select * from TableIn where ANAME=ANY(select BNAME from TableEx)
- SQL中EXISTS怎么用
- 5
- NOT EXISTS 的作用与 EXISTS 正好相反。如果子查询没有返回行,则满足了 NOT EXISTS 中的 WHERE 子句。
- 6
- 结论:
- EXISTS(包括 NOT EXISTS )子句的返回值是一个BOOL值。 EXISTS内部有一个子查询语句(SELECT ... FROM...), 我将其称为EXIST的内查询语句。其内查询语句返回一个结果集。 EXISTS子句根据其内查询语句的结果集空或者非空,返回一个布尔值。
- 7
- 一种通俗的可以理解为:将外查询表的每一行,代入内查询作为检验,如果内查询返回的结果取非空值,则EXISTS子句返回TRUE,这一行行可作为外查询的结果行,否则不能作为结果。
- 8
- 分析器会先看语句的第一个词,当它发现第一个词是SELECT关键字的时候,它会跳到FROM关键字,然后通过FROM关键字找到表名并把表装入内存。接着是找WHERE关键字,如果找不到则返回到SELECT找字段解析,如果找到WHERE,则分析其中的条件,完成后再回到SELECT分析字段。最后形成一张我们要的虚表。
- WHERE关键字后面的是条件表达式。条件表达式计算完成后,会有一个返回值,即非0或0,非0即为真(true),0即为假(false)。同理WHERE后面的条件也有一个返回值,真或假,来确定接下来执不执行SELECT。
- 分析器先找到关键字SELECT,然后跳到FROM关键字将STUDENT表导入内存,并通过指针找到第一条记录,接着找到WHERE关键字计算它的条件表达式,如果为真那么把这条记录装到一个虚表当中,指针再指向下一条记录。如果为假那么指针直接指向下一条记录,而不进行其它操作。一直检索完整个表,并把检索出来的虚拟表返回给用户。EXISTS是条件表达式的一部分,它也有一个返回值(true或false)。
- 9
- 在插入记录前,需要检查这条记录是否已经存在,只有当记录不存在时才执行插入操作,可以通过使用 EXISTS 条件句防止插入重复记录。
- INSERT INTO TableIn (ANAME,ASEX)
- SELECT top 1 '张三', '男' FROM TableIn
- WHERE not exists (select * from TableIn where TableIn.AID = 7)
- 10
- EXISTS与IN的使用效率的问题,通常情况下采用exists要比in效率高,因为IN不走索引,但要看实际情况具体使用:
- IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。
exists : 强调的是是否返回结果集,不要求知道返回什么, 比如:
select name from student where sex = 'm' and mark exists(select 1 from grade where ...) ,只要
exists引导的子句有结果集返回,那么exists这个条件就算成立了,大家注意返回的字段始终为1,如果改成“select 2 from grade where ...”,那么返回的字段就是2,这个数字没有意义。所以exists子句不在乎返回什么,而是在乎是不是有结果集返回。
而 exists 与 in 最大的区别在于 in引导的子句只能返回一个字段,比如:
select name from student where sex = 'm' and mark in (select 1,2,3 from grade where ...)
,in子句返回了三个字段,这是不正确的,exists子句是允许的,但in只允许有一个字段返回,在1,2,3中随便去了两个字段即可。
而not exists 和not in 分别是exists 和 in 的 对立面。
exists (sql 返回结果集为真)
not exists (sql 不返回结果集为真)
下面详细描述not exists的过程:
如下:
表A
ID NAME
1 A1
2 A2
3 A3
表B
ID AID NAME
1 1 B1
2 2 B2
3 2 B3
表A和表B是1对多的关系 A.ID => B.AID
SELECT ID,NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE A.ID=B.AID)
执行结果为
1 A1
2 A2
原因可以按照如下分析
SELECT ID,NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID=1)
--->SELECT * FROM B WHERE B.AID=1有值返回真所以有数据
SELECT ID,NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID=2)
--->SELECT * FROM B WHERE B.AID=2有值返回真所以有数据
SELECT ID,NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID=3)
--->SELECT * FROM B WHERE B.AID=3无值返回真所以没有数据
NOT EXISTS 就是反过来
SELECT ID,NAME FROM A WHERE NOT EXIST (SELECT * FROM B WHERE A.ID=B.AID)
执行结果为
3 A3
===========================================================================
EXISTS = IN,意思相同不过语法上有点点区别,好像使用IN效率要差点,应该是不会执行索引的原因
SELECT ID,NAME FROM A WHERE ID IN (SELECT AID FROM B)
NOT EXISTS = NOT IN ,意思相同不过语法上有点点区别
SELECT ID,NAME FROM A WHERE ID NOT IN (SELECT AID FROM B)
有时候我们会遇到要选出某一列不重复,某一列作为选择条件,其他列正常输出的情况.
如下面的表table:
Id Name Class Count Date
1 苹果 水果 10 2011-7-1
1 桔子 水果 20 2011-7-2
1 香蕉 水果 15 2011-7-3
2 白菜 蔬菜 12 2011-7-1
2 青菜 蔬菜 19 2011-7-2
如果想要得到下面的结果:(Id唯一,Date选最近的一次)
1 香蕉 水果 15 2011-7-3
2 青菜 蔬菜 19 2011-7-2
正确的SQL语句是:
SELECT Id, Name, Class, Count, Date
FROM table t
WHERE (NOT EXISTS
(SELECT Id, Name, Class, Count, Date FROM table
WHERE Id = t.Id AND Date > t.Date))
如果用distinct,得不到这个结果, 因为distinct是作用与所有列的
SELECT DISTINCT Id, Name, Class, Count, Date FROM table
结果是表table的所有不同列都显示出来,如下所示:
1 苹果 水果 10 2011-7-1
1 桔子 水果 20 2011-7-2
1 香蕉 水果 15 2011-7-3
2 白菜 蔬菜 12 2011-7-1
2 青菜 蔬菜 19 2011-7-2
如果用Group by也得不到需要的结果,因为Group by 要和聚合函数共同使用,所以对于Name,Class和Count列要么使用Group by,要么使用聚合函数. 如果写成
SELECT Id, Name, Class, Count, MAX(Date)
FROM table
GROUP BY Id, Name, Class, Count
得到的结果是
1 苹果 水果 10 2011-7-1
1 桔子 水果 20 2011-7-2
1 香蕉 水果 15 2011-7-3
2 白菜 蔬菜 12 2011-7-1
2 青菜 蔬菜 19 2011-7-2
如果写成
SELECT Id, MAX(Name), MAX(Class), MAX(Count), MAX(Date)
FROM table
GROUP BY Id
得到的结果是:
1 香蕉 水果 20 2011-7-3
2 青菜 蔬菜 19 2011-7-2
如果用in有时候也得不到结果,(有的时候可以得到,如果Date都不相同(没有重复数据),或者是下面得到的Max(Date)只有一个值)
SELECT DISTINCT Id, Name, Class, Count, Date FROM table
WHERE (Date IN
(SELECT MAX(Date)
FROM table
GROUP BY Id))
得到的结果是:(因为MAX(Date)有两个值2011-7-2,2011-7-3)
1 桔子 水果 20 2011-7-2
1 香蕉 水果 15 2011-7-3
2 青菜 蔬菜 19 2011-7-2
注意in只允许有一个字段返回
有一种方法可以实现:
SELECT Id, Name, Class, COUNT, Date
FROM table1 t
WHERE (Date =
(SELECT MAX(Date)
FROM table1
WHERE Id = t .Id))
比如在Northwind数据库中有一个查询为
SELECT c.CustomerId,CompanyName FROM Customers c
WHERE EXISTS(
SELECT OrderID FROM Orders o WHERE o.CustomerID=c.CustomerID)
这里面的EXISTS是如何运作呢?子查询返回的是OrderId字段,可是外面的查询要找的是CustomerID和CompanyName字段,这两个字段肯定不在OrderID里面啊,这是如何匹配的呢?
EXISTS用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False
EXISTS 指定一个子查询,检测 行 的存在。
语法: EXISTS subquery
参数: subquery 是一个受限的 SELECT 语句 (不允许有 COMPUTE 子句和 INTO 关键字)。
结果类型: Boolean 如果子查询包含行,则返回 TRUE ,否则返回 FLASE 。
| 例表A:TableIn | 例表B:TableEx |
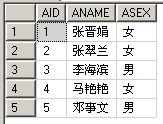 |
 |
(一). 在子查询中使用 NULL 仍然返回结果集
select * from TableIn where exists(select null)
等同于: select * from TableIn
(二). 比较使用 EXISTS 和 IN 的查询。注意两个查询返回相同的结果。
select * from TableIn where exists(select BID from TableEx where BNAME=TableIn.ANAME)
select * from TableIn where ANAME in(select BNAME from TableEx)

(三). 比较使用 EXISTS 和 = ANY 的查询。注意两个查询返回相同的结果。
select * from TableIn where exists(select BID from TableEx where BNAME=TableIn.ANAME)
select * from TableIn where ANAME=ANY(select BNAME from TableEx)
NOT EXISTS 的作用与 EXISTS 正好相反。如果子查询没有返回行,则满足了 NOT EXISTS 中的 WHERE 子句。
结论:
EXISTS(包括 NOT EXISTS )子句的返回值是一个BOOL值。 EXISTS内部有一个子查询语句(SELECT ... FROM...), 我将其称为EXIST的内查询语句。其内查询语句返回一个结果集。 EXISTS子句根据其内查询语句的结果集空或者非空,返回一个布尔值 。
一种通俗的可以理解为:将外查询表的每一行,代入内查询作为检验,如果内查询返回的结果取非空值,则EXISTS子句返回TRUE,这一行行可作为外查询的结果行,否则不能作为结果。
分析器会先看语句的第一个词,当它发现第一个词是SELECT关键字的时候,它会跳到FROM关键字,然后通过FROM关键字找到表名并把表装入内存。接着是找WHERE关键字,如果找不到则返回到SELECT找字段解析,如果找到WHERE,则分析其中的条件,完成后再回到SELECT分析字段。最后形成一张我们要的虚表。
WHERE关键字后面的是条件表达式。条件表达式计算完成后,会有一个返回值,即非0或0,非0即为真(true),0即为假(false)。同理WHERE后面的条件也有一个返回值,真或假,来确定接下来执不执行SELECT。
分析器先找到关键字SELECT,然后跳到FROM关键字将STUDENT表导入内存,并通过指针找到第一条记录,接着找到WHERE关键字计算它的条件表达式,如果为真那么把这条记录装到一个虚表当中,指针再指向下一条记录。如果为假那么指针直接指向下一条记录,而不进行其它操作。一直检索完整个表,并把检索出来的虚拟表返回给用户。EXISTS是条件表达式的一部分,它也有一个返回值(true或false)。
在插入记录前,需要检查这条记录是否已经存在,只有当记录不存在时才执行插入操作,可以通过使用 EXISTS 条件句防止插入重复记录。
INSERT INTO TableIn (ANAME,A***)
SELECT top 1 '张三', '男' FROM TableIn
WHERE not exists (select * from TableIn where TableIn.AID = 7)
- (6) 删除重复记录: ——易思博。。。
- 最高效的删除重复记录方法 ( 因为使用了ROWID)例子:
- DELETE FROM EMP E WHERE E.ROWID > (SELECT MIN(X.ROWID)
- FROM EMP X WHERE X.EMP_NO = E.EMP_NO);
EXISTS与IN的使用效率的问题,通常情况下采用exists要比in效率高,因为IN不走索引,但要看实际情况具体使用:
IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。