solr是什么?Solr集群环境的系统架构有
solr
- solr是什么?
solr是Apache下的一个顶级开源项目,用的是Java开发的,是基于Lucene的全文搜索服务器。但是,它提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,还对索引、搜索性能进行了优化。
Solr需要运行在一个Servlet容器中,Solr4.10.3版本jdk使用1.7以上,Solr默认提供Jetty(Java写的Servlet容器)、Tomcat等这些servlet容器中,
我们以前用的是用Tomcat作为servlet容器,环境是Solr4.10.3、JDK1.7.0_7、apache-tomcat-7.0.53;
Solr和tomcat整合的步骤:
- 将dist\solr-4.10.3.war拷贝到Tomcat的webapp目录下改名为solr.war
- 启动tomcat后,solr.war自动解压,将原来的solr.war删除。
- 拷贝example\lib\ext 目录下所有jar包到Tomcat的webapp\solr\WEB-INF\lib目录下
- 拷贝log4j.properties文件
在 Tomcat下webapps\solr\WEB-INF目录中创建文件 classes文件夹,
复制Solr目录下example\resources\log4j.properties至Tomcat下webapps\solr\WEB-INF\classes目录
- 创建solrhome及配置solrcore的solrconfig.xml文件
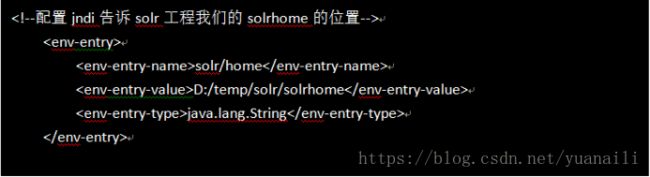
- 修改Tomcat目录 下webapp\solr\WEB-INF\web.xml文件,如下所示:
设置Solr home
并且我们在用Solr的时候还安装了中文分词器
二
我们用的时候都是用Solr的集群的,还有一个是SolrCloud(Solr云),SolrCloud是Solr提供的分布式搜索方案,当需要大规模、容错、分布式索引和检索能力时使用SolrCloud。当一个系统少的时候是不需要使用SolrCoud的;当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,它的主要思想是使用Zookeeper作为集群的配置信息中心。
它有几个特色功能:
1)集中式的配置信息
2)自动容错
3)近实时搜索
4)查询时自动负载均衡
那么,Solr集群环境的系统架构有:
- 物理结构(三个Solr实例( 每个实例包括两个Core),组成一个SolrCloud)
- 逻辑结构
索引集合包括两个Shard(shard1和shard2),shard1和shard2分别由三个Core组成,其中一个Leader两个Replication,Leader是由zookeeper选举产生,zookeeper控制每个shard上三个Core的索引数据一致,解决高可用问题。
用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。
- collection
collection在SolrCloud集群中是一个逻辑意义上的完整的索引结构,常常被划分问为一个或多个Shard(分片),他们使用相同的配置信息。比如:针对商品信息搜索可以创建一个collection。
collection=shard1+shard2+....+shardX
- Core
每个Core是Solr中一个独立运行单位,提供 索引和搜索服务。一个shard需要由一个Core或多个Core组成。由于collection由多个shard组成所以collection一般由多个core组成。
- Master或Slave
Master是master-slave结构中的主结点(通常说主服务器),Slave是master-slave结构中的从结点(通常说从服务器或备服务器)。同一个Shard下master和slave存储的数据是一致的,这是为了达到高可用目的。
- Shard
Collection的逻辑分片。每个Shard被化成一个或者多个replication,通过选举确定哪个是Leader
7、我们需要实现的Solr集群架构为:

Zookeeper作为集群的管理工具。
1、集群管理:容错、负载均衡。
2、配置文件的集中管理
3、集群的入口
需要实现zookeeper 高可用。需要搭建集群。建议是奇数节点。需要三个zookeeper服务器。
搭建solr集群需要7台服务器。
搭建伪分布式:
需要三个zookeeper节点
需要四个tomcat节点。
建议虚拟机的内容1G以上。