测试的用例中,因为limit的大小不同,而产生了完全不同的执行计划:
1. 测试case:
create table t1 ( f1 int(11) not null, f2 int(11) not null, f3 int(11) not null, f4 tinyint(1) not null, primary key (f1), unique key (f2, f3), key (f4) ) engine=innodb; insert into t1 values (1,1,991,1), (2,1,992,1), (3,1,993,1), (4,1,994,1), (5,1,995,1), (6,1,996,1), (7,1,997,1), (8,1,998,1), (10,1,999,1), (11,1,9910,1), (16,1,9911,1), (17,1,9912,1), (18,1,9913,1), (19,1,9914,1), (20,1,9915,1), (21,1,9916,1), (22,1,9917,1), (23,1,9918,1), (24,1,9919,1), (25,1,9920,1), (26,1,9921,1), (27,1,9922,1);
2. 两个不同limit的sql生成的执行计划:
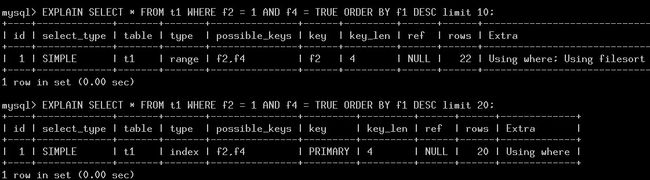
3. 分析过程:
step 1. 获取可用的key,并计算rows
update_ref_and_keys
get_quick_record_count
结果: f2, f4可用, 其分配的quick_rows=[22, 22]

从上面的cardinality来看,f2,f4的过滤性都是2, 这样扫描f2,需要11行,然后根据primary回聚簇表扫描,有需要11行,所有,使用f2, f4索引的扫描需要22行。
step2:穷举下执行计划,找到cost最低的
best_access_path
best_extension_by_limited_search
结果: 全表扫描的代价比较低,records=17, cost=2, 所以最后join->best_position[0]记录的就是全表扫描的执行计划。
step3:limit的影响
在make_join_select的过程,对于limit进行处理,理由是:如果有limit,并且比当前best_position的记录数小,我们尝试是否有可用的index,减少扫描代价
所以,在limit=10的时候,进行test_quick_select查找,并使用f2的索引。而limit=20的查询,不满足条件,所以继续使用全表扫描。
相关注释和代码如下:
/* We plan to scan all rows. Check again if we should use an index. We could have used an column from a previous table in the index if we are using limit and this is the first table */ if ((cond && !tab->keys.is_subset(tab->const_keys) && i > 0) || (!tab->const_keys.is_clear_all() && i == join->const_tables && join->unit->select_limit_cnt < join->best_positions[i].records_read && !(join->select_options & OPTION_FOUND_ROWS)))
step4: order by的影响
函数:test_if_skip_sort_order
limit=10:ref_key=f2: 判断有一个primary key的index可以覆盖order by查询, 但走pk的代价高于ref_key=f2。
limit=20:ref_key=0: 判断有一个primary key的index可以覆盖order by查询,而且当前使用的是全表扫描,代价小于全表,所以选择pk。
所以,两个limit值不同的查询,导致了不同的执行计划。