Miller-Rabin概率素数测试算法
本文首先鸣谢以下资料文章:
资料1
资料2
资料3
下面我们开始正文,从源头开始真正的梳理一下素数测试
1.素数
我们都知道,素数在当今的数论中占有非常重要的地位,主要原因就是素数最根本的性质——除了1,和自身以外,不会被任何一个数整除
并且,素数现在在我们的日常生活中伴有非常重要的地位,这一点的其一主要原因就是素数已经是密码学中最重要的一点,我们当今的密码学常常要涉及到利用超大素数作为我们的密钥和核心,所以说,我们对素数的研究就变得非常的重要了
很是遗憾,现在我们并没有一套合理的算法体系去真正的获取一个绝对100%是素数的一个非常大的数,这是当前做不到的,因为目前的确定性的算法朝朝大素数无外乎两种情况,耗时和空间占用,但是本文将从一种全新的角度带大家研究一种非确定性算法,该算法虽然并不是100%正确的,但是我们如果加上限制条件,我们可以将该算法的错误率降低到几乎可以忽略的程度,这也就是我们本文即将讲述的重点——Miller-Rabin算法
2.朴素素数测试 + 筛法
我们从刚开始学编程的时候,大学老师都会给我们将一种非常糟糕的算法(当然这处理我们的考试已经够了)这种算法叫做试除法
算法描述:
对一个已知的待测的数n,k从2开始一直到n-1,我们如果发现k|n,那么我们认为这是一个合数
当然,这是我们从素数的定义出发的一种算法,之所以说这种算法糟糕是因为当我们的待测的数非常的大的时候,我们不得不遍历一整遍数据来保证算法的正确性,这是无法容忍的
可能有的人还想在这个算法上搞搞优化什么的,其实都是治标不治本
至于朴素素数测试和筛法测试我会援引我的博客作为讲解
Lantian的朴素素数测试和筛法素数生成算法讲解
在这里我先声明:
筛法是一种非常高效的算法,但是在这里筛法没有办法发挥他的优势,因为筛法真正强大在可以快速的生成一定范围内的所有的素数,但是我们这里强调的是对超大素数的测试,并不需要获取那么多的素数
以上,筛法和朴素测试的时间复杂度都是O(n)和无限接近O(n),在这里我们确定性算法就走到了尽头,下面有请非确定性概率测试算法来施展身手
3.必要数论基础知识
在我们继续研究之前,我们还需要一些必备的知识来为我们打通道路
1.费马小定理:
其实在讲费马小定理之前,我们其实还需要讲解欧拉定理,飞马小丁立只是欧拉定理的特殊情况
欧拉定理:
![]() 这里的n,a必须是互素(Gcd(n,a)=1)
这里的n,a必须是互素(Gcd(n,a)=1)
费马小定理:
![]() 当欧拉定理中的n是素数的时候,很显然欧拉函数的值是n-1,费马小定理成立,这里就不描述费马小定理的证明了
当欧拉定理中的n是素数的时候,很显然欧拉函数的值是n-1,费马小定理成立,这里就不描述费马小定理的证明了
2.二次探测定理:
二次探测定理
为了更好的了解Miller-Rabin算法,我们在这里必须需要了解二次探测定理的证明和原理,相信我,这不难
首先,先给出二次探测定理的描述:
如果p是素数,x是小于p的正整数,且 ,那么要么x=1,要么x=p-1。这是显然的,因为相当于p能整除
,那么要么x=1,要么x=p-1。这是显然的,因为相当于p能整除 ,也即p能整除(x+1)(x-1)。由于p是素数,那么只可能是x-1能被p整除(此时x=1) 或 x+1能被p整除(此时x=p-1)。
,也即p能整除(x+1)(x-1)。由于p是素数,那么只可能是x-1能被p整除(此时x=1) 或 x+1能被p整除(此时x=p-1)。
4.费马测试
首先我们先来看看费马测试
刚才我们的费马小定理已经说明了素数成立的必要条件,也就是说,如果一个数不满足费马小定理,那么这个数必定是合数,但是如果这个数满足我们就没有办法确定是不是合数还是素数了,因为历史上有一种非常神秘的数的存在——卡密歇尔数,这类数我们也叫伪素数
如果想要了解更多的话,可以百度查询,我们这里只需要了解到,因为卡米歇尔书满足费马小定理但是同时又不是素数,所以这使得我们的费马测试(费马小定理的逆定理)不是正确的,也就不能称之为算法
但是我们还是需要知道这种测试的情况的,对于至少也是一种测试算法
一般以2为a做测试,我们一般应用费马测试的时候都是提前利用了一张伪素数表来进行容错处理,当我们找到了满足费马测试并且又不在伪素数表(基于底数2)上的时候我们就可以断定是一个素数,但是这样有两个缺点:
1.占用时间,我们生成伪素数需要很大的计算资源(我还真不知道有什么好的算法可以快速求伪素数)
2.当我们内存资源不允许伪素数表的时候,我们的费马测试错误率太高,不能实际应用
费马小定理毕竟只是素数判定的一个必要条件.满足费马小定理条件的整数n未必全是素数.有些合数也满足费马小定理的条件*.这些合数被称作Carmichael数,前3个Carmichael数是561,1105,1729.
Carmichael数是非常少的.在1~100000000范围内的整数中,只有255个Carmichael数.数据越大,之后的卡米歇尔数越稀疏
但是在允许伪素数表的情况下对于快速计算幂取模的话(因为测试的素数非常的大)我们可以用快速幂来实现:Lantian的快速幂算法详解
5.Miller-Rabin素性测试
Miller和Rabin两个人的工作让Fermat素性测试迈出了革命性的一步,建立了Miller-Rabin素性测试算法
在这之前,我们为了更好的了解算法的本质,我们来看一下伪素数341是如何被Miller-Rabin的二次探测定理卡掉的
一下摘引自资料1:
我们下面来演示一下上面的定理如何应用在Fermat素性测试上。前面说过341可以通过以2为底的Fermat测试,因为2^340 mod 341=1。如果341真是素数(对于任意的x<341,我们必须都要满足x=1||x=340)的话,那么2^170(2^340开方,这时候的2^340满足了)mod 341只可能是1或340;当算得2^170 mod 341确实等于1时,我们可以继续查看2^85除以341的结果。我们发现,2^85 mod 341=32,这一结果摘掉了341头上的素数皇冠
在这里,我们抽离一下本质,我们用Miller-Rabin做素数测试的时候将a^(n-1)
转化成了a^(d*2^r)这里的d是一个正奇数(1也是)
这就是Miller-Rabin素性测试的方法。不断地提取指数n-1中的因子2,把n-1表示成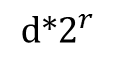 (其中d是一个奇数)。那么我们需要计算的东西就变成了
(其中d是一个奇数)。那么我们需要计算的东西就变成了 除以n的余数。于是,
除以n的余数。于是, 要么等于1,要么等于n-1。如果等于1,定理继续适用于
要么等于1,要么等于n-1。如果等于1,定理继续适用于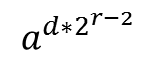 ,这样不断开方开下去,直到对于某个i满足
,这样不断开方开下去,直到对于某个i满足 或者最后指数中的2用完了得到的
或者最后指数中的2用完了得到的
在这里我们需要明确一点,当这种情况出现的时候,我们没有办法继续满足二次探测定理了,我们就不对这种情况继续判断,支队等于1的情况继续用二次探测定理判断
所以我们的算法流程就出来了
我们首先从先计算出
x=(mod n)
然后如果x=n-1,我们返回true,是一个素数
如果不是我们继续判断知道,我们中途发现x!=1&&x!=n-1我们返回false,是个合数
知道最后,我们看看剩下的数是1还是n-1还是别的数
在这里我们还有一些技巧需要学习:
1.利用数论的只是证明之后我们可以发现,只要我们的Miller-Rabin多次随机选择底数a的话,重复进行k次,我们可以将错误降低到2^(-k),次数越多越精确,错误概率越小
2.Miller-Rabin素性测试同样是不确定算法,我们把可以通过以a为底的Miller-Rabin测试的合数称作以a为底的强伪素数(strong pseudoprime)。第一个以2为底的强伪素数为2047。第一个以2和3为底的强伪素数则大到1 373 653。
Miller-Rabin算法的代码也非常简单:计算d和r的值(可以用位运算加速,即快速积,快速幂),然后二分计算的值,最后把它平方r次。
3.对于大数的素性判断,目前Miller-Rabin算法应用最广泛。一般底数仍然是随机选取,但当待测数不太大时,选择测试底数就有一些技巧了。比如,如果被测数小于4 759 123 141,那么只需要测试三个底数2, 7和61就足够了。当然,你测试的越多,正确的范围肯定也越大。如果你每次都用前7个素数(2, 3, 5, 7, 11, 13和17)进行测试,所有不超过341 550 071 728 320的数都是正确的。如果选用2, 3, 7, 61和24251作为底数,那么10^16内唯一的强伪素数为46856248255981
4.最好不要用合数作为底,出错概率太大,至少也是素数作为底,证明的话,不会
6.Miller-Rabin 代码
本人用正向迭代和反向迭代都了一遍,发现正向迭代在很大的偶数的情况下比反向的速度快一点点,平均的时间都差不多
#include"iostream"
#include"cstdio"
#include"cstring"
#include"cstdlib"
#include"ctime"
using namespace std;
long long quicks(long long a,long long b,long long c)
{
long long ans=1;
a=a%c;
while(b!=0)
{
if(b & 1) ans=(ans*a)%c;
b>>=1;
a=(a*a)%c;
}
return ans;
}
bool Miller_Rabin_1(long long n) //标准代码
{
long long t=0;
long long b=n-1;
while((b&1)==0)
{
t++;
b>>=1;
}
//现在的a^(b*2^t)=1(mod n)
long long a=11; //测试
long long x=quicks(a,b,n);
//个人认为这里如果加上优先判定是不是1,n-1的话,会更快一点?是不是呢?????
for(long long i=1;i<=t;i++)
{
long long y=quicks(x,2,n);
if(y==1&&x!=1&&x!=n-1) return false; //这里的意思是如果a^(d*2^r)是1,但是a^(d*2^(r-1))不是1也不是n-1的情况,这时候我们认为是合数
x=y;
}
if(x!=1) return false;
else return true;
}
bool Miller_Rabin_2(long long n) //正向迭代
{
long long p=n-1;
long long a=11;
long long x=quicks(a,p,n);
if(x==n-1) return true;
else
{
long long w;
do
{
p>>=1;
w=quicks(a,p,n);
if(w==n-1) return true;
else if(w!=1) return false;
}
while((p&1)!=1);
if(w==1||w==n-1) return true;
else return false;
}
}
int main()
{
double time=clock();
if(Miller_Rabin_1(2222222222222222222222)) printf("YES\n");
else printf("NO\n");
printf("%lf\n",clock()-time);
time=clock();
if(Miller_Rabin_2(2222222222222222222222)) printf("YES\n");
else printf("NO\n");
printf("%lf\n",clock()-time);
return 0;
}7.Thinking
感谢前人的无私分享,我在匍匐前进,特以此文鸣谢资料和论文的作者
剩余几个问题待解:
1.算法中最后的(n-1)|x的情况为什么不考虑,只考虑x!=1的情况?
2.在检查的过程中,如果出现了(n-1)|x我们怎么回避呢
3.在计算出来d,b之后我们可不可以提前判断一下a^d是不是1或者n-1的倍数从而加快速度呢?