Pandas
Pandas是python里分析结构数据化的工具集
基础是numpy:高性能矩阵运算
图形库matplotlib:提供数据可视化
创建关键数据结构
s = pd.Series([1,2,3,np.NaN,8,4])
data = pd.DataFrame(np.random.randn(6,4),index = dates,cloums = list(“ABCD”))
d = {“A”:1,“B”:2,“C”:rang(4),“D”:arange(4)}
data.head() #默认查看前5行,括号中参数就是行数
data.tail() #默认查看后五行,括号中参数就是行数
data.tail(3)
data.index #查看行标签
data.sort_index(axis=1,ascending=Fales) #按顺序排序,axis = 1是列标签,默认=0行标签,ascending=Fales是降序,True是升序
data.columes #查看列标签
data.T #转置
data.sort_values(by = “a”) #列标签a进行排序
读取文件:
1.csv,tsv,txt用逗号。tan分割的纯文本文件:pd.read_csv
2.excle微软xls或者xlsx文件:pd.read_excel
3.musql关系型数据库表:pd.read_sql
读取csv

读取txt文件

读取excel文件

读取mysql表:

Pandas数据结构:
1.DataFrame:二维数组,整个表格,多行多列

2。Series:是一种类似一位数组的对象,由一组数据(不同数据类型)以及一组与之相关的数据标签(索引)组成。:一维数据,一行或者一列,
Series和DataFrame搭配使用:DataFrame查询出一个区块,仍然是一个二维表格,那么仍然是DataFrame,但是如果结果是一列或者一行,那么他的结构就是Series。
创建Series的方法:
1.s = pd.Series([1,“a”,5.2,7]) #类似于列表
s.index #获取索引
s.values #获取元素值的列表
2.s = pd.Series([1,“a”,5.2,7],index = [“d”,“b”,“a”,“c”])
s
d 1
b a
a 5.2
c 7
dtype:object
3.s1 = {“a”:30,“b”:24,“c”:52}
s = pd.Series(s1)
s
a 30
b 24
c 52
dtype:object
根据标签索引查询数据
类似于python的dict
s = pd.Series([1,“a”,5.2,7],index = [“d”,“b”,“a”,“c”])
s[“a”]
5.2
s[[“b”,“a”]]
a,5.2
DataFrame:
和series不同,dataframe有行索引index也有列索引columns。
可以被看做是有series组成的字典,创建dataframe最常用的方法就是上面提到的读取纯文本文件,excel和mysql数据库。
根据多个字典序列创建dataframe。
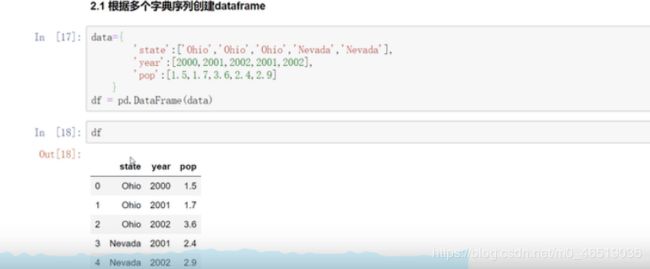
df.dypes
state object
year int64
pop float64
dtype:object
df.columns
state,year,pop
df.index
start = 0,stop=5,step =1
dataframe中查询出series
查询列:
df[’'year"] #series,查询一类,返回的是行的索引
df[“year”,“pop”] #dataframe
查询行:
df.loc[1] #series,需要用到loc方法,返回的索引是列名
df.loc[1:3] #查询多行,这里需要注意,这里都是闭区间,也就是包含第三行。这也是一个dataframe
pandas如何对数据进行查询(df.loc的5种方法)
5种方法分别是按数值,列表,区间,条件,函数
Pandas的查询方法:
1.df.loc方法,根据行,列的标签值查询(.loc既能查询,又能覆盖写入,强烈推荐!!)
df.loc的5个查询数据的方法:
1.使用单个label值查询数据
2.使用值列表批量查询
3.使用数值区间进行范围查询
4.使用条件表达式查询
5.调用函数查询
以上的查询方法,适用于各个维度。既适用于行,也适用于列,注意观察降维dataframe>Series>值
数据: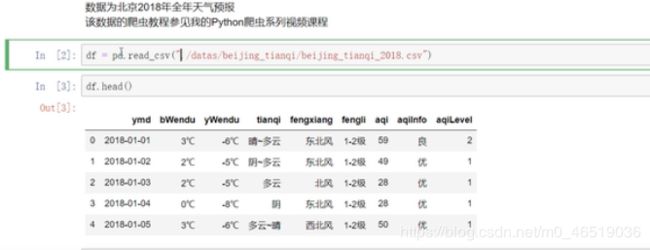
df.set_index(“ymd”,inplace=“True”) #改变行名,由0-1-2-3-4.。。。改变成日期,inplace:True是直接改变这个df。

把bwendu列的数据进行处理:
df.loc[:,“bwendu”] = df[“bwendu”].str.replace(“℃”,"").sdtype(“int32”)
df.loc[:,“ywendu”] = df[“ywendu”].str.replace(“℃”,"").sdtype(“int32”)

正题开始:
1.使用单个label值查询数据:行或者列,都可以值传入单个值,事先精准匹配
df.loc[“2018-01-03”,“bWendu”]
2
df.loc[“2018-01-03”,][“bWendu”,“yWendu”]
bWendu 2
yWendu -5
Name:2018-01-03,dtype:object
2.使用值列表进行批量查询
df.loc[[“2018-01-03”,“2018-01-04”,“2018-01-05”],[“bWendu”,“yWendu”]]

3.使用数值区间进行范围查询
df.loc[“2018-01-03”:“2018-01-05”,“bWendu”]

4.使用条件表达式查询,返回的是bool类型的数组,bool列表的长度等于行数或者列数。
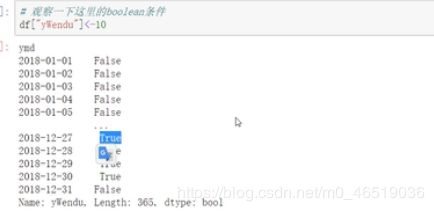
例子1.查询全年最低温度低于-10度的列表:
df.loc[df[“bWendu”]<-10,:] #这个series传入df以后,只会返回结果为True的数据.后面的:表示从索引取所有行
观察返回的series,左侧返回的是ymd,右侧返回的是bool类型。

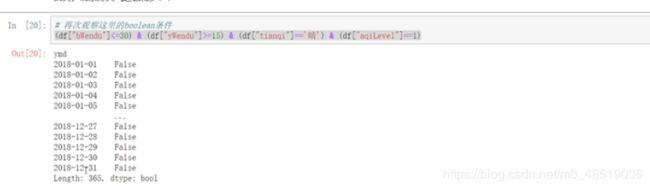
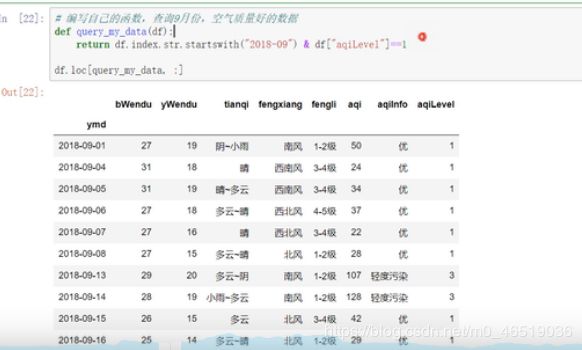
例子2.查询我心中的完美天气:
df.loc[(df[dWendu]>15)&(df[yWendu]<30)&(df[“tianqi”] == “晴”)&(df[“aqiLevel”] == 1),:]

5.调用函数查询
df.loc[lambda df :(df[“bWendu”]<=30)&df[“yWendu”]>=15,:]

2.df.iloc方法,根据行,列的数字位置查询
3.df.where方法(比较高级)
4.df.query方法(比较高级)
python新增数据列(直接赋值,apply,assign,分条件赋值)
pandas怎样新增数据列:
在进行数据分析时,经常按照一定条件创建新的数据列,然后进行进一步的分析。
直接赋值
apply:df.apply
assign:df,assign
分条件赋值:按条件选择分组分别赋值

1.直接赋值法(在上一小节,已经处理温度的时候,想把3℃变成int类型,这种方法就是直接赋值):
df.loc[:,“bWendu”] = df[“bWendu”],str,replace(“℃”,"").astype(“int32”) #df.loc[:,“bWendu”]选择所有行数的bWendu这列,等于最低温度这一列的str形式的replace函数(这个函数是把逗号后面的“”中数据替换成前面的“”中的数据)。最后astype(转换类型,类型为astype后面引号中的数据类型)
df,loc[:,“yWendu”] = df[“yWendu”],str,replace(“℃”,"").astype(“int32”)
df.head()

df.loc[:,“wencha”] = df[“bWendu”] - df[“yWendu”]
#注意。df[“bWendu”]其实是一个Series,后面的减法返回的是Series。
df.head()

2.df.apply()
沿着df的某个轴,应用了一个函数,传入给函数的对象,是一个Series,这个Series 要么是df的index(axis = 0),要么是cloumns(axis = 1)
df.loc[:,“wendu_type”] = df.apply(get_wendu_type,axis = 1)
实例:添加一列温度类型:
def get_wendu_type(x):
if x[“bWendu”]>33:
return “高温”
elif x[“bWendu”]<-10:
return"低温"
else:
return"常温"
df.loc[:,“wendu_type”] = df.apply(get_wendu_type,axis = 1)
#查看温度类型的计数:
df[“wendu_type”].value_counts()

3.df.assign
和apply不同的是,assign可以一次增加多个列。assign是把cloumns传给函数。
df.assign(
yWendu_huashi = lambda x : x[“yWendu”]*9/5+32,
bWendu_huashi = lambda x : x[“bWendu”]*9/5+32)
#key就是我们要新增的列,value就是我们的函数
assign不会修改我们本来的df,会生成一个新的对象。
4.按条件选择分组分别赋值
按条件先选择数据,然后对这部分数据赋值新列。
实例:高低温差大于10度,则认为温差大
df[“wencha_type”] = “”
df.loc[df[“bWendu”]-df[“yWendu”]>10,“wemcja_type”] = “温差大”
df[“wencha_type”] = “”
df.loc[df[“bWendu”]-df[“yWendu”]<=10,“wemcja_type”] = “温差大”
df[“wencha_type”].value_counts()
Pandas数据统计函数(汇总类统计,唯一去重和按值计数,相关系数和斜方差)
1.汇总类统计(对于数字类型)
df.describe() #一下子提取所有数字列统计结果

也可以查看单个Serise的数据
df[“bWendu”].mean() #平均
df[“bWendu”].min() #最小
df[“bWendu”].max() #最大
2.对于非数字类型:唯一去重和按值计数
df[“fengji”].unique() #找到某一列的全部取值
![]()
df[“fengxiang”].value_counts() #查看每个值出现了多少次

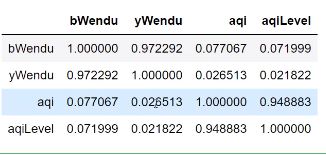
3.相关系数和协方差

df.cov() #协方差矩阵,数据正负号,如果都为正,说明数据都是同向变化,比如对于空气质量指数,和高温低温都是正向变化。

df.corr() #相关系数矩阵,空气质量指数和高温低温是0,07和0.02,说明他们的相关性比较小。但是空气质量指数和空气质量等级是0.94。非常的相关
也可以只查看2个列之间的影响
df[“aqi”].corr[df[“yWendu”]] #空气质量和最低温度之间的相关系数
df[“aqi”].corr(df[“bWendu”]-df[“yWendu”]) #空气质量和温差之间的相关系数
Pandas对缺失值的处理
pandas使用这些函数处理缺失值:
isnull和notnull:检测是否是空值,可用于df和serier
dropna:丢弃,删除缺失值,他的参数:
axis:删除行还是列
how:如果等于any,则任何值为空都删除,如果等于all,则所有值都为空才删除
inplace:如果True,则修改当前df,否则返回新的df
fillna:填充空值:,他的参数:
vlaue:用于填充的值,可以是单个值,或者字典(key是列名,value是值)
method:等于ffill:使用前一个不为空的值填充forword fill,等于bfill:使用后一个不为空的值填充backword fidd
asix:按行还是按列填充
inplace:如果为True则修改当前df,否则返回新的df
练习:
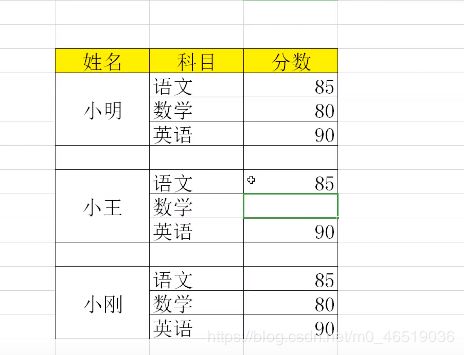
1.导入文件 #skiprows = 2是让pandas略过前面2个空行,从第三行开始读取


studf.isnull()

studf[“分数”].notnull()

studf.loc[studf[“分数”].notnull(),:]

删除全是空值的列:
studf.dropna(axis = “columns”,how = “all”,inplace = True)

删除全是空值的行:
studf.dropna(axis = “index”,how = “all”,inplace = “True”)
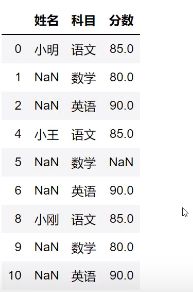
将分数为空的值填充为0
studf.fillna({“分数”:0})
等同于studf.loc[:,“分数”] = studf[“分数”].fillna(0)
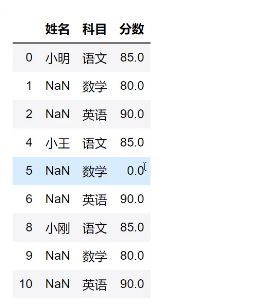
将姓名的缺失值进行填充
studf.loc[:,“姓名”] = studf[“姓名”].fillna(method = “ffill”)
保存文件,
index = False
pandas 的SettingWithCopyWarning


condition = df[“ymd”].str.startswith(“2018-03”)
Pandas 数据排序
Series的排序:
Series.sort_vlaue(ascending=True,inplace=False)
ascending:默认True(升序排列)
inplace:是否修改原始Series
DataFrame的排序:
DataFrame.sort_values(by,ascending=True,inplace=False)
by:字符串或者list<字符串>,单列排序或者多列排序
ascending:bool或者List,升序还是降序,如果是list对应by的多列
inplace:是否修改原始DataFrame

 df[“aqi”].sort.values(asccnding = True)
df[“aqi”].sort.values(asccnding = True)

df.sort_values(by = “aqi”)

df.sort_values(by = [“aqiLeve”,“bWendu”],ascending = [True,False])

Pandas对字符串的处理
前面使用过的:
df.loc[:,“bWendu”] = df[“bWendu”].str.replace(“℃”,"").astype(“int32”)
Pandas的字符串处理:
1.使用方法:先获取Series的str属性,然后再属性上调用。
2.只能再字符串列上使用,不能数字列上使用。
3.Dataframe上没有str属性和处理方法。
4.Series.str不是Python的原生字符串,而实自己的一套方法,不过大部分和原生str相似。



df[“bWendu”].str #Series的str是series的一个类型
![]()

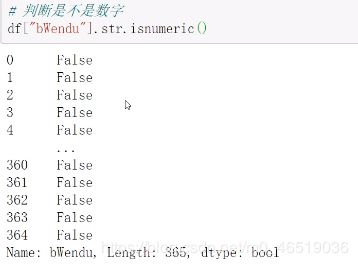
使用str的startwith,contains得到bool的Series可以做条件查询

需要处理多次str处理的链式操作
怎样提取201803这样的数字月份?
先将日期2018-03-31替换成20180331的形式
提取月份字符串201803
df[“ydm”].str.replace("-","")



使用正则表达式的处理:
添加一列中文日期:
def get_nianyueri(x):
year,month,dat = x[“ymd”].split("-")
return “f{year}年{month}月{day}日”
df[“中文日期”] = df.apply(get_nianyueri,axsi = 1)

如果想把年月日字符去除。有两种方法,1.使用replace,2.Series.str默认就开启了正则表达式模式
1.
df[“中文日期”].str.replace(“年”,"").str.replace(“月”,"").str.repalce(“日”,"")
2.
df[“中文日期”].str.replace("[年月日]","") #只要遇到了年月日三个字符的任意一种,都算匹配成功,替换成空字符串
Pandas的axis参数
axis = 0 or axis = “index”
如果是单行操作,指的就是某一行、
如果是聚合操作,指的就是跨行cross rows
axis = 1 or aixs = “cloumns”
如果是单列操作,值得就是某一列
如果是聚合操作,值得就是跨列cross columns
Pandas的索引index用途
把数据存储到columns中也可以进行数据查询,那使用index有什么好处呢:
1.更方便的数据查询
2.使用index可以获得性能提升
3.自动的数据对齐功能
4.更多更强大的数据结构支持
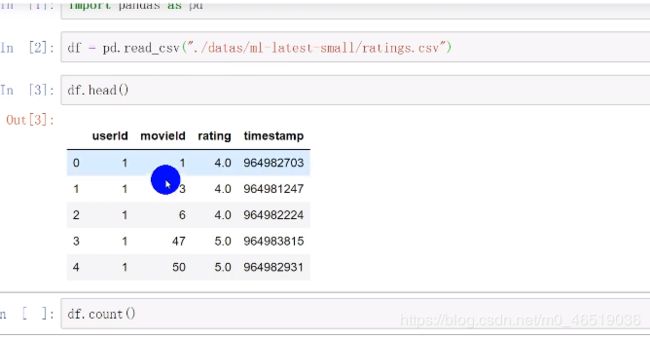
导入一个数据集,包含:用户id,电影id,评分,时间
这个数据的索引是自动生成的索引,我们可以使用set_inedx修改索引,把索引修改为我们有意义的数据列,比如uerID。
df.set_index(“userID”,inplace = True,drop = False) #drop的意思:是否将作为索引列的userID删除,True为删除,False为保留
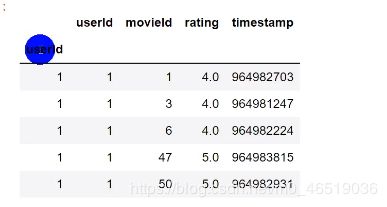
使用index的查询方法:
df.loc[500].head(5) #查询用户ID等于500的用户的评分记录
df.loc[df[“userID”] == 500].head() #是用列查会比较麻烦
使用index会提升查询性能

实验1:完全随机的顺序查询
from sklearn.untils import shuffle
df_shuffle = shuffle(df)
df_shuffle.index.is_monotonic_increasing #判断索引是否递增,如果是返回True,pandas就会使用二分查询,不是返回False
df_shuffle.index.is_unique #判断是否使用哈希查询

实验2:将index排序后的查询
df_sort = df_shuffle.sort_index()
df_sort.index.is_monotonic_increasin

使用index能自动对齐数据
包括serise和dataframe


Pandas的merge
Pandas怎样实现DataFrame的Merge
pandas的merge相当于sql的join,将不同的表按key关联到一个表。
merge的语法:pd.merge(left,right,how = “inner”,on = None,left_on = None,right_on = None,lift_index = False,right_index = False,sort = True,suffixex = ("_x","_y"),copy = True,indicator = False,validata = None)

电影数据集的join实例
这个数据集包含3个文件:
1.用户对电影的评分数据 raings.dat
2.用户本身的信息数据user.dat
3.电影的数据movles.dat

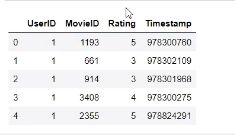


df_rating_users = pd.merge(df_ratings,df_users,left_on = “UesrID”,right_on = “UserID”,how = “inner”) #inner:两边都有的数据才会保留
df_rating_user_movies = pd.merge(df_tating_users,df_movies,left_on = “MovieID”,right_on = “MovieID”,how = “inner”)
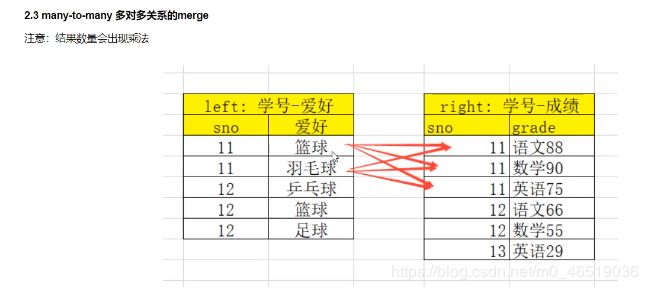
merge时数量的对齐关系

1对1

1对多

多对多:

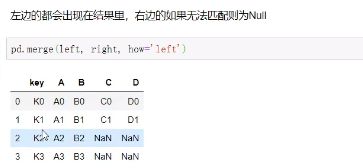
理解left join,right join,inner join,outer join的区别


inner join:

left join:
right join:

out join:

如果出现非key字段重名:

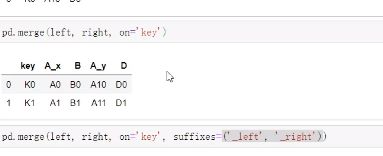
会把重复的key字段标记_x,_y,也可以使用suffixes自己修改。
Pandas数据合并(concat)
使用某种合并方式(inner或者outer)
沿着某个轴向(axis = 0/1)
把多个Pandas对象(dataframe或者series)合并成一个。
使用场景:合并相同格式的Excel,给DataFrame添加行或者列
concat语法:pandas.concat(objs,axis = 0,join=“outer” ignore_index = False)

append语法:dataframe.append(other,ignoer_index = False)

df1 = DataFrame{“A”:[“A0”,“A1”,“A2”,“A3”]
“B”:[“B0”,“B1”,“B2”,“B3”]
“C”:[“C0”,“C1”,“C2”,“C3”]
“D”:[“D0”,“D1”,“D2”,“D3”]
“E”:[“E0”,“E1”,“E2”,“E3”]
}
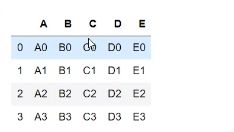
df1 = DataFrame{“A”:[“A4”,“A5”,“A6”,“A7”]
“B”:[“B4”,“B5”,“B6”,“B7”]
“C”:[“C4”,“C5”,“C6”,“C7”]
“D”:[“D4”,“D5”,“D6”,“D7”]
“F”:[“F4”,“F5”,“F6”,“F7”]
}

pd.concat([df1,df2]) #默认axis = 0.join = outer,ignore_index = False
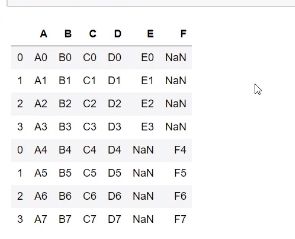
pd.concat([df1,df2],ignore_index = True)
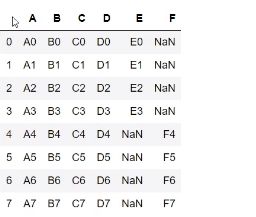
使用join = inner过滤吊不匹配的列
pd.concat([df1,df2],ignore = True,join = “inner”)

axis = 1详单与添加新的列

添加一列新列series
s1 = pd.Series(lise(range(4)),name = “F”)
pd.concat([df1,s1],axis = 1)

append:
df = pd.DataFrame([[1,2],[3,4]],columns=list(“AB”))

df2 = pd.DataFrame([[5,6],[7,8]],columns = list(“AB”))

1.可以给1个dataframe添加另一个dataframe
df1.append(df2)
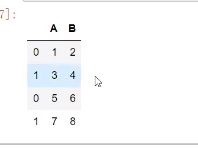
df1.append(df2,ignore_index = True)

可以一行一行的给DataFrame添加数据
#一个空的df
df = pd.DataFrame(columns = [“A”])
![]()


Pandas批量差分和和合并Excel文件
将一个打Excel拆分成多个excel
使用df.iloc,将一个大的dataframe拆分成多个小dataframe
将使用dataframe.to_excel保存每个小excel
1.计算拆分后每个excel的行数
user_names = [“xiaoshuai”,“xiaowang”,“xiaoming”,“xiaolei”,“xiaobo”,“xiaohong”]

2.拆分成多个dataframe
将每个dtaframe存入excel

合并多个小excel到大的excel
1.遍历文件夹,得到要合并的excel文件列表
2.分别读取dataframe,给每个df添加一列用于标记来源
3.使用pd.concat进行df批量合并
4.将合并后的dataframe输出到excel




Pandas怎样实现grouby分组统计
groupby: 转换函数
演示:1,分组使用聚合函数做数据统计
2,遍历groupby的结果理解实行流程
3,实例分组探索天气数据


1.分组使用聚合函数做数据统计:
单个groupby,查询所有数据列的统计
df.groupby(“A”).sum()

我们看到,groupby中的A变成了索引列,因为要统计sum,但B列不是数字,所以被自动忽略。
2.多个列groupby,查询所有数据列的统计
df.groupby([“A”],[“B”]).mean()
我们看到,(“A”,“B”)变 成了二级索引

df.groupby(“A”.as_index = False).mean()
3.同时查看多种数据统计
df.groupby(“A”).agg([np.sum,np.mean,np.std])

4.查看单列的数据结果统计
df.groupby(“A”)[“C”].agg([np.sum,np.mean,np.std]) #取出C的sum,mean和std

5.不同列使用不同的聚合函数
df.groupby(“A”).agg(“C”:np.sum,“D”:np.mean)

遍历groupby的结果理解执行流程
for循环可以直接遍历每个groupby
g = df.groupby(“A”)
for name,group in g:
print(name)
print(group)
print()
可以获取单个分组的数据
g.get_group(“bar”)
Pandas的分层索引Multindex

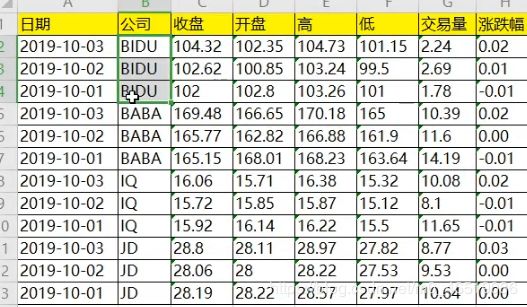
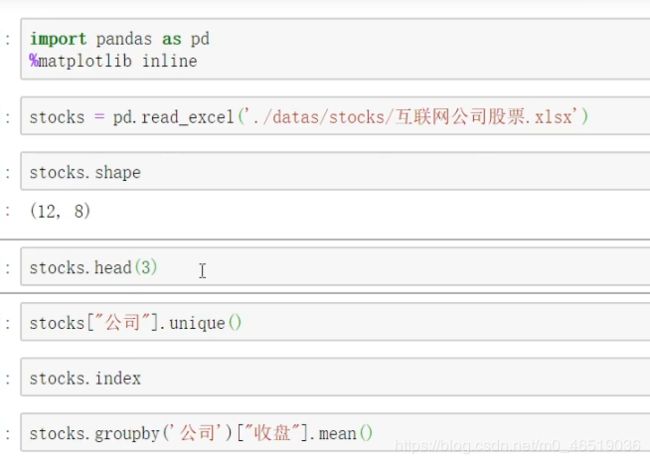
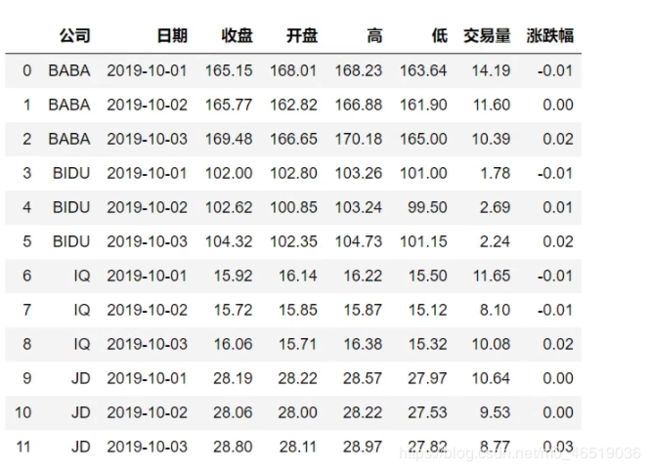
stocks[“公司”],unique()
BAIDU,BABA,IQ,JD
stocks.groupby(“公司”)[“收盘”].mean #看这三家公司的收盘价格
1.Series的分层索引Multindex
ser = stocks.groupby(“公司”,“日期”)[“收盘”].mean()
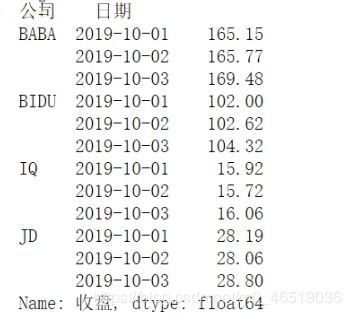
我们可以看到这个series有两个索引,一个是日期,一个是公司名称,多维索引中,空白的意思是使用上面的值
可以使用方法unstack把二级索引变为一个列
ser.unstack()
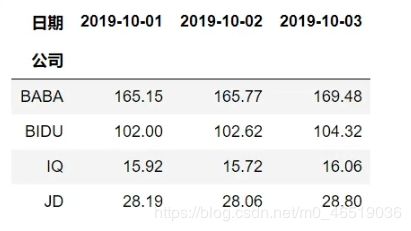
这时候,series就变成了一个df。
还有一种方法,reset_index(),可以把索引都变成普通的列
ser.reset_index()

Series有多层索引MultiIndex筛选数据
ser.loc[“百度”]
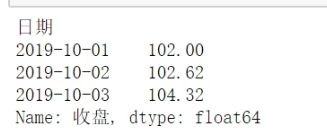
set.loc[(“BAIDU”,“2019-10-02”)]
![]()
set.loc[(:,“2019-10-02”)]

DataFrame的多层索引MulitIndex
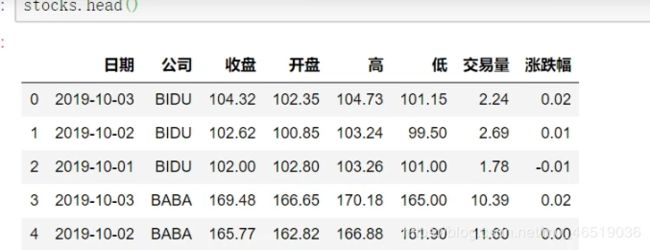
stock.set_index([“公司”,“日期”],inplace = True)
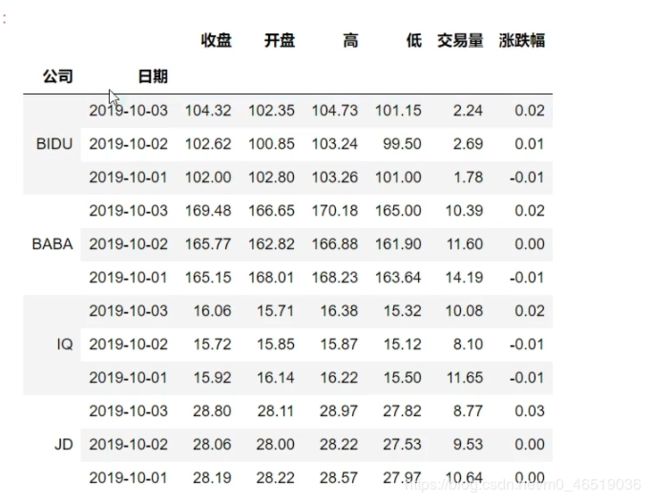
DataFrame有多层索引MultiIndex筛选数据
重要指示:在选择数据时:
元组(key1,key2)代表筛选多层索引,其中key1是索引的第一级,key2是第二级,比如key1 = JD,key2 = 2019-10-02
列表[key1,key2]代表同一层的多个key,key1和key2是同级关系,比如key1 = JD
key2 = BAIDU
stock.loc[“BAIDU”]
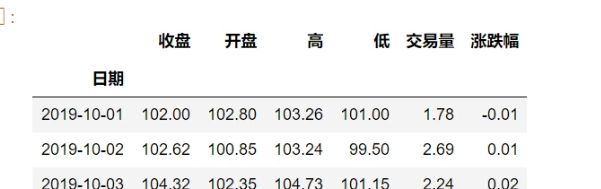
stock.loc[(“BAIDU”,“2019-10-02”),"]
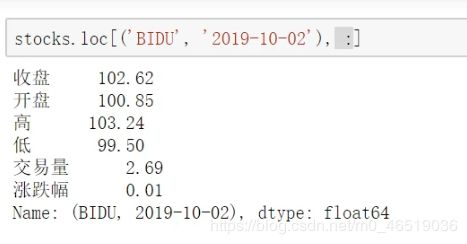
stock.loc[(“BAIDU”,“2019-10-02”),“开盘”]
100.85
stock.loc[[“BAIDU”,“JD”],"]

stock.loc[([“JD”,“BAIDU”],2019-10-03),:]
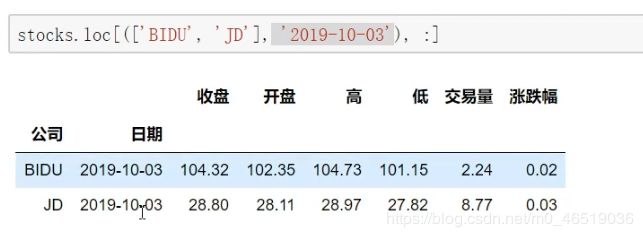
stock.reset_index() #reset_index方法可以把索引都变成普通的列
Pandas的数据转换函数 map,apply,applymap
数据转换函数对比:map。apply,applymap
1.map:只用于Series,实现每个值-》值的映射
2.apply:用于Series实现每个值的处理,用于DataFrame实现某个轴的Series的处理
3.applymap:只能用于Dataframe。用于处理DataFrame的每个元素
1.map用于Series值的转换
实例:将股票代码英文转换成中文

stocks[“公司”].unique()
dict_company_names = {
“baidu” :“百度”,
“baba”:“阿里巴巴”,
"iq::“爱奇艺”,
“jd”:“京东”
}
方法1:Series.map(dict)
stoks[“公司中文1”] = stock[“公司”].str.lowr().map(dict_company_names) #取stock的公司列,使用str的lowr方法把大写转换成小写,在这个字典中取出key和value。赋值给公司中文1
方法2:Series,map(function)
function的参数是Series的每个元素的值
stocks[“公司中文2”] = stock[“公司”].map(lamba x : dict_company_names[x.lower()])
apply用于series和DataFrame的转换
Series.apply(function),函数的参数是每个值
DataFrame.apply(function),函数的参数是Series
Series.apply(function):
stocks[“公司中文3”] = stocks[“公司”].apply(lambda x : doct_complay_names[x.lower()])
DataFrame.apply(function)所有值的转换(function的参数是对应轴的Series)
stocks[“公司中文4”] = stocks[“公司”].apply(lambda x:dict_company_names[x[“公司”].low()],axis = 1)
applymap用于DataFrame所有值的转换
sub_df = stocks[[“收盘”,“开盘”,“高”,“低”,“交易量”]]
sub_df.applymap(lambda x : int(x)) #作用所有元素的值
stocks.loc[:,[“收盘”,“开盘”,“高”,“低”,“交易量”]] = sub_df.applymap(lambda x :int(x)) #直接修改原df的这几列
Pandas怎样对每个分组应用apply函数
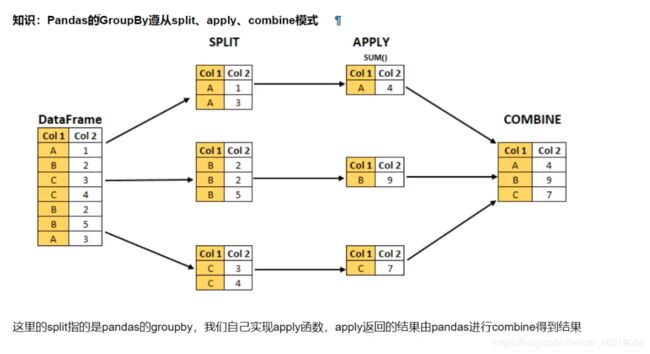
pandas的groupby遵从split,apply,combine模式
Groupby.apply(function)
function的第一个参数是dataframe
function的返回结果,可是dataframe,series,单个值甚至和输入dataframe完全没关系
本次实例演示:
1.怎样对数值案列分组的归一化
2.怎样取每个分组的topn数据
1.怎样对数值列按分组的归一化:

归一化 = (当前值-最小值)/(最大值-最小值)

min_value = df[“Rating”].min()
max_value = df[“Rating”].max() #获取最大值和最小值,分别赋值。
df[“Rating_norm”] = df[“Rating”].apply(lambda x :(x-min_value)/(max_value-min_value)) #对Rating_norm进行归一化
提取每个分组的TOPN数据
获取2018年每个月温度最高的两天数据

df.loc[:,“bWendu”] = df[“bWendu”].str.replace(“℃”,"").astype(“int32”)
df.loc[:,“yWendu”] = df[“yWendu”].str.replace(“℃”,"").astype(“int32”)
df[“month”] = df[“ymd”.str[:7]]# 新增一列为月份
def getWendutopN(df,topn):
return df.sort_value(by = “bWendu”)[[“ymd”,"bWendu”][-topn:]
df.groupby(month).apply(getWenduTopN,topn2),head()
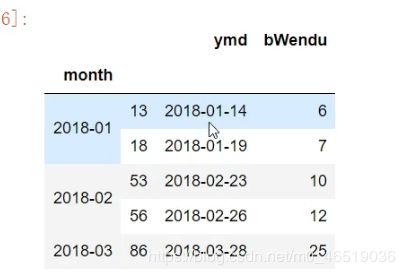
可以看到,grouby的apply函数返回的dataframe和原来的dataframe完全不一样
Pandas使用stack和pivot实现数据透视
将列式数据变成而为交叉形式,便于分析,叫做重塑或者透视
1.经过统计得到多维度指标数据
2.使用unstack实现数据二位透视
3.使用pivot简化透视
4.stack,unstack,pivot的语法
1.经过统计得到多维度指标数据
非常场景的统计场景,指定多个维度,计算聚合后的指标
实例:统计得到电影评分数据集,每个月份的每个分数被评分多少次

df[“pdate”] = pd.to_datatime(df[“Timestamp”],unti = “s”)
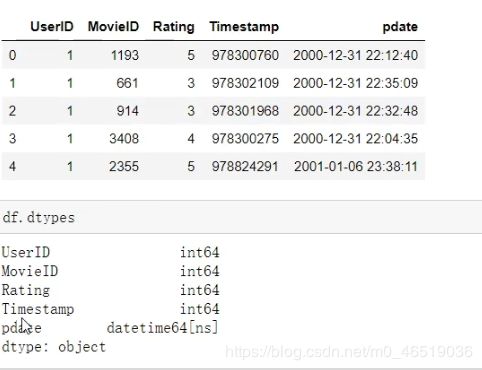
df_group = df.groupby([df[“pdate”].dt/month.“Rating”])[“UserID”].agg(pv = np.sum)
使用unstack实现数据二维透视
df_stack = df_group.unstack()
df_stack.plot()

Pandas实现对日期的快速处理
Pandas日期处理的作用:
将2018-10-02或者1/1/2018等多种日期格式映射成统一的格式对象,几个概念:
1.pd.to_datatime:pandas的一个函数,能将子豆腐串,列表,series变成日期形式
2.Timestamp:pandas表示日期的对象行使
3.DatatimeIndex:pandas表示日期的对象行使列表

实例:怎么统计每周,每月,每季度最高温度
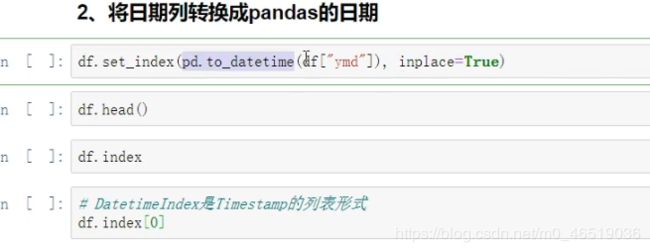
把日期列变为pandas对象的形式的好处:
方便对DatatimeIndex进行查询




方便获取周,月,季度

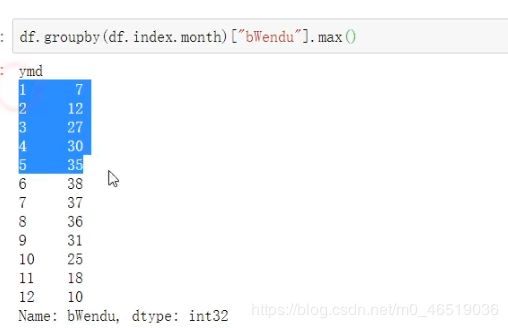
统计每周,每月,每季度的最高温度
df.groupby(df.index.week)[“bWendu”].max()

统计每个月的数据
df.groupby(df.index,month)[“bWendu”].max()
Pandas处理日期索引的缺失
按照日期统计的数据,缺失了某天,导致数据不全该怎么补充日期?
2中方法可以实现:
1.DataFrame.reinde,调整dataframe的索引以适应新的索引
2.DataFrame.resample,可以对时间序列重采样,支持补充缺失值

方法1,使用pandas.reindex方法
1.将df的索引变成日期索引
df_data = df.set_index(“pdata”)
df_data = df_data.set_index(pd.to_datatime(df_data.index))

使用pandas.reindex填充缺失的索引
pdates = pd.date_range(start = “2019-12-01”,end = “2019-12-05”)