Gradient Boosting(GBM) 调参指南
译文:Complete Guide to Parameter Tuning in Gradient Boosting (GBM) in Python
简介
这边文章帮助大家去看看GBM的是如何真正工作的。原文受启发于 NYC Data Science Academy 与bagging 在模型中只控制高方差不同的是,Boosting 算法善于处理偏差(bias)方差(variance)问题(trade-off),且比bagging更有效。
这篇文章将会揭露GBM背后的科学原理,且教会你如何进行参数调优从而获得可靠的结果。
How boosting works?
Boosting 是一个以融合原则工作的序列技术,将一系列的弱学习器进行组合从而提升预测的准确率。模型第t次迭代的结果,是基于前t-1次的结果进行赋权。如果样本被正确预测了将会被富裕较低的权重,反之,预测错误的样本将会被赋予较高的权重。
如下例所示:

- 图一:输出第一个弱分类器
- 一开始所有的样本权重一样(取决于样本的大小)
- 决策边界正确预测了2个正样本和5个负样本
图二:输出第二个弱分类器
- 在图一中被正确分类的样本被赋予较低的权重,错误分类的样本将被赋予较高的权重
- 模型现在专注于高权重的样本且能将其正确分类,但是其他样本被错误分类了
与图二类似的变化将会在图三中看到,这种情况将会迭代多次,直到模型给样本的权重取决于模型的准确率,最终生成一个合并的结果
以下几篇文章可以参考:
Learn Gradient Boosting Algorithm for better predictions (with codes in R)
Quick Introduction to Boosting Algorithms in Machine Learning
Getting smart with Machine Learning – AdaBoost and Gradient Boost
GBM 参数
GBM的所有参数可以划分成以下3种类型:
1. Tree-Specific Parameters:这类参数影响模型中的每一颗树;
2. Boosting Parameters:这类参数影响模型boosting的操作;
3. Miscellaneous Parameters:其他影响整体功能的参数
- overall functioning
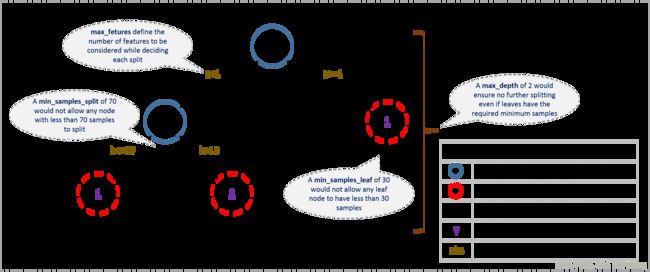
用于描述树的参数如下:
- min_samples_split
- 定义:用于定义一个节点可分裂的最少的样本数量;
- 作用:控制过拟合,值越小越容易过拟合,值太大会容易欠拟合
- 调参方式:CV
- min_samples_leaf
- 定义:叶子节点最少的样本数量
- 作用:控制过拟合,
- 调参方式: 不平衡样本需要设置较小的值,因为少数样本为一类的叶子样本量会偏小
- min_weight_fraction_leaf
- 定义:与min_samples_leaf类似,但是是一个关于整体样本量的一个分数而不是整数
- Only one of #2 and #3 should be defined.
- max_depth
- 定义:树的深度
- 作用:控制过拟合
- 调参方式: CV
- max_leaf_nodes
- 定义:最终的数的叶子节点的最多数量
- 与max_depth能相互替代,如果被定义了,max_depth将被忽视
- max_features
- 定义:当寻找最优分裂点时,考虑的随机选择的特征的数目
- 经验原则:特征数目的平方根很好用,但是这个数目应该有总特征数目的30%-40%以上
- 调参:高max_features会产生过拟合问题,但取决于具体的案例
以下是GBM2分类算法的伪算法:
1. Initialize the outcome
2. Iterate from 1 to total number of trees
2.1 Update the weights for targets based on previous run (higher for the ones mis-classified)
2.2 Fit the model on selected subsample of data
2.3 Make predictions on the full set of observations
2.4 Update the output with current results taking into account the learning rate
3. Return the final output.2.Boosting Parameters
Boosting Parameters 主要影响以上伪代码的2.2建模部分,各参数如下:
+ learning_rate:
- learning_rate:
- c此参数影响每棵树最终的输出结果(step 2.4), GBM通过设置一个初始的参数估计量并通过树的输出结果进行更新,本参数控制的是估计量变化的幅度
- 较小的值通常更受偏好,因为其使得模型对一些特定的特征的更具有鲁棒性
- 较小的值需要更多数量的树去训练所有的关系,将产生高昂的计算消耗
- n_estimators
- 建模的树的数量
- 虽然GBM对于大额n_estimators值具有较强的鲁棒性但是在某些点的时候依然会产生过拟合问题,因此需要通过CV在特定的learning_rate下进行调参
- subsample
- 每棵树的样本数量,随机选择
- 值小于1能通过降低模型的方差增强模型的鲁棒性;
- 常用的值范围[0,0.8],也可以调高点
3.Miscellaneous Parameters
- loss
- 定义:只每次进行节点分裂时的loss function
- 可以有多个选择,通常情况下,默认参数工作较好,其他的参数也可以被使用,前提是你要了解他们对模型的影响
- init
- 这个参数影响模型的初步输出
- 如果有其他模型的输出结果可以使用其他模型的输出结果作为GBM初始值
- random_state
- 这个是随机种子,固定随机种子后,模型里面的随机化过程将会被重复
- 这个参数对于模型调优非常重要,如果不固定,将很难进行模型调优,无法对比模型结果的好坏
- 本参数有可能导致过拟合问题,可以为模型设置不同的随机参数,但通常不会这么做
- verbose
- 当模型拟合选择输出的模型的类型,不同的值具有以下的含义:
- 0: no output generated (default)
- 1: output generated for trees in certain intervals
- >1: output generated for all trees
- 当模型拟合选择输出的模型的类型,不同的值具有以下的含义:
- warm_start
- 如果使用得当,这个参数将会有很大的帮助
- 通过这个参数,我们可以将新树添加到旧有的模型上。可帮助节省大量的时间。(嗯,这个参数可以好好研究研究)
- presort
- 用于选择是否需要对数据进行预分类从而加快分裂的速度
- 会通过默认值使得选择自动化
作者提供了他的giuhub相关链接:
GitHub repository
参数调整实例
作者使用了 Data Hackathon 3.x AV hackathon的比赛实例,比赛的题目[ competition page](competition page),可以在这里下载数据,作者的数据预处理过程如下:
1.City variable dropped because of too many categories
2.DOB converted to Age | DOB dropped
3.EMI_Loan_Submitted_Missing created which is 1 if EMI_Loan_Submitted was missing else 0 | Original variable EMI_Loan_Submitted dropped
4.EmployerName dropped because of too many categories
5.Existing_EMI imputed with 0 (median) since only 111 values were missing
6.Interest_Rate_Missing created which is 1 if Interest_Rate was missing else 0 | Original variable Interest_Rate dropped
7.Lead_Creation_Date dropped because made little intuitive impact on outcome
8.Loan_Amount_Applied, Loan_Tenure_Applied imputed with median values
9.Loan_Amount_Submitted_Missing created which is 1 if Loan_Amount_Submitted was missing else 0 | Original variable Loan_Amount_Submitted dropped
10.Loan_Tenure_Submitted_Missing created which is 1 if Loan_Tenure_Submitted was missing else 0 | Original variable Loan_Tenure_Submitted dropped
11.LoggedIn, Salary_Account dropped
12.Processing_Fee_Missing created which is 1 if Processing_Fee was missing else 0 | Original variable Processing_Fee dropped
13.Source – top 2 kept as is and all others combined into different category
14.Numerical and One-Hot-Coding performed
通常情况下使用默认参数作为调参的基准
from sklearn.ensemble import GradientBoostingClassifier #GBM algorithm
#Choose all predictors except target & IDcols
predictors = [x for x in train.columns if x not in [target, IDcol]]
gbm0 = GradientBoostingClassifier(random_state=10)
modelfit(gbm0, train, predictors)#作者自己编写的用于输出想要结果的函数通常的参数调优的方法
通过使用默认参数,获得了一个baseline,调参的预期效果期望好于baseline,通常调参就是以上提及的两种参数类型,其中learning rate的策略是取小值(如果我们有足够数目的树训练)。
当树的数目增加的时候,GBM对过拟合是鲁棒的,但是一个大的学习率会导致过拟合问题,我们可以通过减小learning rate增加数的数目来加以改善,导致的结果是计算量大需要花很多的时间。
据上,我们可以采取以下的策略:
1. 选择一个相对大的learning rate,通常设置为0.1,有些时候[0.05,0.2]在有些时候也可以考虑
2. 根据选定的learning rate决定最优的树的数目。通常的范围为[40-70]。应该选一个能够让你的系统工作较快的范围
3. 调整tree-specific parameters :对于确定的学习率和树的个数,进行tree-specific parameters 的调整,作者给了一个例子,见下一个标题
4. 在以上的基础上降低学习率增加树的数量会获得更好鲁棒的模型
Fix learning rate and number of estimators for tuning tree-based parameters
为了获得最优的参数,我们先设定一些初始值,如下:
+ min_samples_split = 500:这个值得设定通常在样本量的0.5-1%之间,但如果是不平衡样本,值可以在设置的低一些
+ min_samples_leaf = 50 :可根据直觉设置,这个参数的目的是用于防止过拟合,但是遇到不平衡数据时,可以考虑设置较低一些的值
+ max_depth = 8 : 可以基于样本量和特征量设置在(5-8)左右
+ max_features = ‘sqrt’ :随意吧
+ subsample = 0.8 : 这个是通常初始化的值
以上均是初始化的值,默认learning_rate=0.1,据此可以grid search搜索[20,80]步长为10的最优的树的数目,下面将进行调参:
#Choose all predictors except target & IDcols
predictors = [x for x in train.columns if x not in [target, IDcol]]
param_test1 = {'n_estimators':range(20,81,10)}
gsearch1 = GridSearchCV(estimator = GradientBoostingClassifier(learning_rate=0.1, min_samples_split=500,min_samples_leaf=50,max_depth=8,max_features='sqrt',subsample=0.8,random_state=10),
param_grid = param_test1, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch1.fit(train[predictors],train[target])调参的结果可以像下面这样查看:
gsearch1.grid_scores_, gsearch1.best_params_, gsearch1.best_score_
以上结果可以看出,最优的树的数目是60,但是如果我们获得的最优的树的数目过大或者过小怎么办?
1.如果结果值在20左右,需要适当降低学习率(如改成0.05),重新run网格搜索程序
2.如果结果值太大到了100左右,最快的方式是调大学习率
Tuning tree-specific parameters
调参的步骤:
1. max_depth and num_samples_split
2. min_samples_leaf
3. max_features
调参的顺序需要被谨慎的考虑,应该先调整对结果影响较大的参数。
作者的举例如下:
- 首次按调max_depth ,范围[5-15],步长2;min_samples_split ,范围[200,1000],步长200
param_test2 = {'max_depth':range(5,16,2), 'min_samples_split':range(200,1001,200)}
gsearch2 = GridSearchCV(estimator = GradientBoostingClassifier(learning_rate=0.1, n_estimators=60, max_features='sqrt', subsample=0.8, random_state=10),
param_grid = param_test2, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch2.fit(train[predictors],train[target])
gsearch2.grid_scores_, gsearch2.best_params_, gsearch2.best_score_作者调优后的结果 max_depth=9,min_samples_split=1000,此时min_samples_split为设置的阈值上界,所有有必要进一步扩大上界进行二次调优(可选择,当max_depth=9,score差异不大时可以不调)。
- 调整min_samples_leaf,范围[30,70],步长10,根据上一步,设置一个较大的min_samples_split,范围[1000,2100],步长200
param_test3 = {'min_samples_split':range(1000,2100,200), 'min_samples_leaf':range(30,71,10)}
gsearch3 = GridSearchCV(estimator = GradientBoostingClassifier(learning_rate=0.1, n_estimators=60,max_depth=9,max_features='sqrt', subsample=0.8, random_state=10),
param_grid = param_test3, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch3.fit(train[predictors],train[target])
gsearch3.grid_scores_, gsearch3.best_params_, gsearch3.best_score_调完参数后,可以看一下特征的重要性,并将现在的特征重要性与之前的baseline模型的特征重要性进行对比,可以发现,我们能从更多的特征中获取更多的信息
接下来,调整最后一个树参数,max_features,范围[7,19],步长为2
param_test4 = {'max_features':range(7,20,2)}
gsearch4 = GridSearchCV(estimator = GradientBoostingClassifier(learning_rate=0.1, n_estimators=60,max_depth=9, min_samples_split=1200, min_samples_leaf=60, subsample=0.8, random_state=10),
param_grid = param_test4, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch4.fit(train[predictors],train[target])
gsearch4.grid_scores_, gsearch4.best_params_, gsearch4.best_score_以上步骤完成之后,就获得了所有调参的结果
为了进一步调整模型,下一步就是对模型的subsample 进行进一步调整,范围[0.6,0.9],步长0.05
param_test5 = {'subsample':[0.6,0.7,0.75,0.8,0.85,0.9]}
gsearch5 = GridSearchCV(estimator = GradientBoostingClassifier(learning_rate=0.1, n_estimators=60,max_depth=9,min_samples_split=1200, min_samples_leaf=60, subsample=0.8, random_state=10,max_features=7),
param_grid = param_test5, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch5.fit(train[predictors],train[target])
gsearch5.grid_scores_, gsearch5.best_params_, gsearch5.best_score_以上步骤完成之后,作者获得了最优的模型结果0.85,并获得了所有的最优的参数值。现在,需要降低学习率并增加树的数量。
随着树的数目的增加,通过CV进行计算的时间将会快速增长,作者将学习率设置成0.05,并将树的数目double了一下(然后不断的将学习率除以2,树的数目double)
predictors = [x for x in train.columns if x not in [target, IDcol]]
gbm_tuned_1 = GradientBoostingClassifier(learning_rate=0.05, n_estimators=120,max_depth=9, min_samples_split=1200,min_samples_leaf=60, subsample=0.85, random_state=10, max_features=7)
modelfit(gbm_tuned_1, train, predictors)另外一个调参的黑马是warm_start。可以用来慢慢增加数的数目而不需要总是重新开始训练。作者未对这个参数做进一步的描述