python实现Trie 树+朴素匹配字符串+RK算法匹配字符串+kmp算法匹配字符串
一.trie树应用:
常用于搜索提示,如当输入一个网址,可以自动搜索出可能的选择。当没有完全匹配的搜索结果,可以返回前缀最相似的可能。
例如三个单词app, apple, add,我们按照以下规则创建了一颗Trie树.对于从树的根结点走到黑色结点的路径上的字母依次组合起来就是一个完整的单词. 
class Trie:
# word_end = -1
def __init__(self):
"""
Initialize your data structure here.
"""
self.root = {}
self.word_end = -1
def insert(self, word):
"""
Inserts a word into the trie.
:type word: str
:rtype: void
"""
curNode = self.root
for c in word:
if not c in curNode:
curNode[c] = {}
curNode = curNode[c]
curNode[self.word_end] = True
def search(self, word):
"""
Returns if the word is in the trie.
:type word: str
:rtype: bool
"""
curNode = self.root
for c in word:
if not c in curNode:
return False
curNode = curNode[c]
# Doesn't end here
if self.word_end not in curNode:
return False
return True
def startsWith(self, prefix):
"""
Returns if there is any word in the trie that starts with the given prefix.
:type prefix: str
:rtype: bool
"""
curNode = self.root
for c in prefix:
if not c in curNode:
return False
curNode = curNode[c]
return True
# Your Trie object will be instantiated and called as such:
word = 'apple'
prefix = 'ad'
obj = Trie()
obj.insert(word='apple')
obj.insert(word='add')
obj.insert(word='app')
print('tree:',obj.root)
param_2 = obj.search(word)
print('search res:',param_2)
param_3 = obj.startsWith(prefix)
print('prefix find:',param_3)

二.字符串匹配算法
1.朴素匹配算法
暴力解法,时间复杂度是O(m*n) 。
t = 'aabaabaabab'
p = 'abc'
print(nmatching(t,p))
def match_string(t,p):
n=len(t)
m=len(p)
i=j=0
while i2.RK算法
采用字符串的hash值进行匹配,时复杂度O(n),最差情况退化到朴素匹配,时间复杂度也为O(m*n)
def compute_hash(str_):
"""a的hash值是0,其它依次加1"""
hash_code = 0
for i in range(len(str_)):
# print('str_[i]', str_[i])
hash_code += ord(str_[i])-ord('a')
return hash_code
#RK算法
def RK(main_str,pattern_str):
"""通过比较字符串的hash值 从而找到子串 时间复杂度O(n),遇见复杂情况就退化为了O(mn))"""
pattern_hash_code = compute_hash(pattern_str)
pattern_len = len(pattern_str)
print('==模式串hash_code', pattern_hash_code)
str_hash_code = compute_hash(main_str[:pattern_len])
print('==子串_hash_code', str_hash_code)
for i in range(len(main_str)-len(pattern_str)+1):
if str_hash_code == pattern_hash_code and main_str[i:i+len(pattern_str)] == pattern_str:
return i
else:
str_hash_code -= ord(main_str[i]) - ord('a')
str_hash_code += ord(main_str[i + len(pattern_str)]) - ord('a')
# hash_code = compute_hash('ab')
# print('hash_code:', hash_code)
# main_str = 'ad'
# pattern_str = 'ad'
main_str = 'aacdesadsdfer'
pattern_str = 'adsd'
index = RK(main_str, pattern_str)
print('子串的位置在:', index)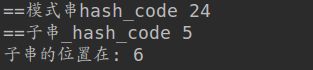
3.KMP算法
记录最长公共前后缀,然后字符串匹配按照这个来,时间复杂度O(n)
最长公共前后缀计算:

示意:

代码:
#最长公共前后缀
def pefix_table(pattern):
"""字符串最长公共前后缀
思路:通过遍历字符串来寻找公共部分,当出现不一样的时候 需要回退直到比较首字符"""
""" 'ababcabaa' """
# """ 'ababa' """
# 'aa'
i = 0
prefix = [0]*len(pattern)
for j in range(1, len(pattern)):
while(pattern[j]!=pattern[i] and i>0):#循环判断如果发现没有相等就一直回退直到i==0也就是首字符
i = prefix[i-1]
if pattern[j] == pattern[i]:#相等的話就记录相等的长度
i += 1
prefix[j] = i
else:
prefix[j] = 0#不相等的話就长度长公共前后缀记录为0
return prefix
def move_prefix(prefix):
""""""
real_prefix = [-1]*len(prefix)
for i in range(len(prefix)-1):
real_prefix[i+1]=prefix[i]
return real_prefix
str_ = 'ababcabaa'
# str_ = 'ababa'
prefix = pefix_table(str_)
print('==prefix:', prefix)![]()
kmp匹配开始:

按照b的下标移动,会发现前面相似的不需要比对:
#最长公共前后缀
def pefix_table(pattern):
"""字符串最长公共前后缀
思路:通过遍历字符串来寻找公共部分,当出现不一样的时候 需要回退直到比较首字符"""
""" 'ababcabaa' """
# """ 'ababa' """
# 'aa'
i = 0
prefix = [0]*len(pattern)
for j in range(1, len(pattern)):
while(pattern[j]!=pattern[i] and i>0):#循环判断如果发现没有相等就一直回退直到i==0也就是首字符
i = prefix[i-1]
if pattern[j] == pattern[i]:#相等的話就记录相等的长度
i += 1
prefix[j] = i
else:
prefix[j] = 0#不相等的話就长度长公共前后缀记录为0
return prefix
def move_prefix(prefix):
""""""
real_prefix = [-1]*len(prefix)
for i in range(len(prefix)-1):
real_prefix[i+1]=prefix[i]
return real_prefix
# str_ = 'ababcabaa'
# # str_ = 'ababa'
# prefix = pefix_table(str_)
# print('==prefix:', prefix)
# prefix = move_prefix(prefix)
# print('==prefix:', prefix)
def kmp(main_str,pattern_str):
"""kmp比对"""
i = 0
j = 0
n = len(pattern_str)
while i < len(main_str):
if j == n-1 and main_str[i] == pattern_str[j]:
print('find pattern at {}'.format(i-j))
j = prefix[j]
if main_str[i] == pattern_str[j]:
i += 1
j += 1
else:
j = prefix[j]
if j == -1:#找到边界都向右移动一位
i += 1
j += 1
pattern_str ='ababcabaa'
main_str = 'abababcabaabababab'
prefix = pefix_table(pattern_str)
# print('==prefix:', prefix)
prefix = move_prefix(prefix)
print('==prefix:', prefix)
kmp(main_str, pattern_str)
参考:
https://blog.csdn.net/weixin_42698229/article/details/90321230
https://blog.csdn.net/weixin_39561100/article/details/80822208
https://www.bilibili.com/video/BV1hW411a7ys/?spm_id_from=trigger_reload