前言
Solr在Lucene之上开发了很多Cache功能,目前提供的Cache类型有:
(1) filterCache
(2) documentCache
(3) fieldvalueCache
(4) queryresultCache
一、Cache的生命周期
Solr查询的核心类是SolrIndexSearcher,每个core通常在同一时刻只由当前的SolrIndexSearcher供上层的handler使用(但当切换SolrIndexSearcher时可能会有两个同时提供服务),Solr的各种Cache正是依附于SolrIndexSearcher的,SolrIndexSearcher在则Cache生,SolrIndexSearcher亡则Cache被清空close掉。
从上面前言中可知,Solr中的应用Cache有filterCache、queryResultCache、documentCache等,这些Cache都是SolrCache的实现类,并且是SolrIndexSearcher的成员变量,各自有着不同的逻辑和使命,后面分别予以介绍和分析。
二、Cache的配置介绍
要使用Solr的四种Cache,只需要在SolrConfig中配置如下内容即可:
... // 是否能使用到filtercache关键配置 true // queryresult的结果集控制20 // 是否启用懒加载fieldtrue ...
三、Solr Cache的命中监控
当启动Solr后,可通过Solr Admin来查看Solr中每个Cache的命中情况。
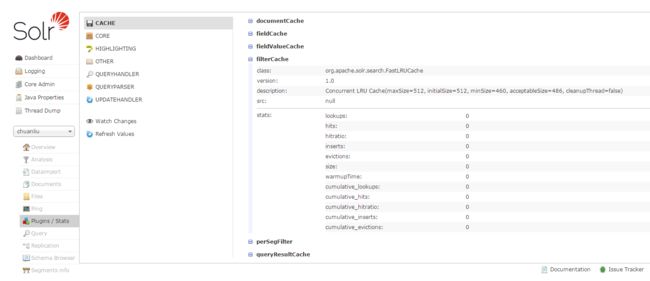
其中 lookups 为当前cache 查询数, hitratio 为当前cache命中率,inserts为当前cache插入数,evictions为从cache中踢出来的数据个数,size 为当前cache缓存数, warmuptime为当前cache预热所消耗时间,而cumulative都为该类型Cache累计的查询,命中,命中率,插入、踢出的数目。
四、Solr Cache接口实现类
1、Solr提供了两种SolrCache接口实现类:solr.search.LRUCache和solr.search.FastLRUCache。FastLRUCache是1.4版本中引入的,其速度在普遍意义上要比LRUCache更快些。
下面是对SolrCache接口主要方法的注释:
public interface SolrCache {
/**
* Solr在解析配置文件构造SolrConfig实例时会初始化配置中的各种CacheConfig,
* 在构造SolrIndexSearcher时通过SolrConfig实例来newInstance SolrCache,
* 这会调用init方法。参数args就是和具体实现(LRUCache和FastLRUCache)相关的
* 参数Map,参数persistence是个全局的东西,LRUCache和FastLRUCache用其来统计
* cache访问情况(因为cache是和SolrIndexSearcher绑定的,所以这种统计就需要个
* 全局的注入参数),参数regenerator是autowarm时如何重新加载cache,
* CacheRegenerator接口只有一个被SolrCache warm方法回调的方法:
* boolean regenerateItem(SolrIndexSearcher newSearcher,
* SolrCache newCache, SolrCache oldCache, Object oldKey, Object oldVal)
*/
public Object init(Map args, Object persistence, CacheRegenerator regenerator);
/** :TODO: copy from Map */
public int size();
/** :TODO: copy from Map */
public Object put(Object key, Object value);
/** :TODO: copy from Map */
public Object get(Object key);
/** :TODO: copy from Map */
public void clear();
/**
* 新创建的SolrIndexSearcher autowarm方法,该方法的实现就是遍历已有cache中合适的
* 范围(因为通常不会把旧cache中的所有项都重新加载一遍),对每一项调用regenerator的
* regenerateItem方法来对searcher加载新cache项。
*/
void warm(SolrIndexSearcher searcher, SolrCache old) throws IOException;
/** Frees any non-memory resources */
public void close();
LRUCache可配置参数如下:
1)size:cache中可保存的最大的项数,默认是1024
2)initialSize:cache初始化时的大小,默认是1024。
3)autowarmCount:当切换SolrIndexSearcher时,可以对新生成的SolrIndexSearcher做autowarm(预热)处理。autowarmCount表示从旧的SolrIndexSearcher中取多少项来在新的SolrIndexSearcher中被重新生成,如何重新生成由CacheRegenerator实现。
查看Solr源码可以发现,在实现上,LRUCache直接使用LinkedHashMap来缓存数据,由initialSize来限定cache的大小,淘汰策略也是使用LinkedHashMap的内置的LRU方式,读写操作都是对map的全局锁,所以并发性效果方面稍差。
1.2、solr.search.FastLRUCache
在配置方面,FastLRUCache除了需要LRUCache的参数,还可有选择性的指定下面的参数:
1)minSize:当cache达到它的最大数,淘汰策略使其降到minSize大小,默认是0.9*size。该值的大小应该至少等于我们使用的过滤字段的大小。举个例子说明:如果在某个时间内,你的应用程序使用了2000个查询参数,则minimum的大小应该最小设为2000。
2)acceptableSize:当淘汰数据时,期望能降到minSize,但可能会做不到,则可勉为其难的降到acceptableSize,默认是0.95*size,也可以这么理解,如果没有设置minSize,那么改值会替代之。
3)cleanupThread:相比LRUCache是在put操作中同步进行淘汰工作,FastLRUCache可选择由独立的线程来做,也就是配置cleanupThread的时候。当cache大小很大时,每一次的淘汰数据就可能会花费较长时间,这对于提供查询请求的线程来说就不太合适,由独立的后台线程来做就很有必要。
实现上,FastLRUCache内部使用了ConcurrentLRUCache来缓存数据,它是个加了LRU淘汰策略的ConcurrentHashMap,所以其并发性要好很多,这也是多数Java版Cache的极典型实现。
2、filterCache
2.1 概述:
filterCachef中存储了无序的lucene document id集合,即FilterCache存储了一些无序的文档标识号(ID),这些ID并不是我们在schema.xml里配置的unique key,而是solr内部的一个文档标识。
该cache有3种用途:
1)filterCache存储了filter queries(“fq”参数)得到的document id集合结果 Solr中的query参数有两种,即q和fq。如果fq存在,Solr是先查询fq(因为fq可以多个,所以多个fq查询是个取结果交集的过程),之后将fq结果和q结果取并。在这一过程中,filterCache就是key为单个fq(类型为Query),value为document id集合(类型为DocSet)的cache。从后面的分析你将会看到对于fq为range query来说,filterCache将表现出其更有价值的一面。
2)filterCache还可用于facet查询
facet查询中各facet的计数是通过对满足query条件的document id集合(可涉及到filterCache)的处理得到的。因为统计各facet计数可能会涉及到所有的doc id,所以filterCache的大小需要能容下索引的文档数。
3)如果solfconfig.xml中配置了
对于是否使用filterCache及如何配置filterCache大小,需要根据应用特点、统计、效果、经验等各方面来评估。对于使用fq、facet的应用,对filterCache的调优是很有必要的。
2.2 有效的使用filterCache
光有上面的配置是不够的,我们还需要让查询能够使用它,如下面的例子:
q=name:solr+AND+category:ksiazka+AND+section:ksiazki
初看起来,查询语句是正确的。但是有个问题:它并没有用到filterCache。所有的请求将会绑定到queryResultCache中并创建一个单独的条目。如果修改为:
q=name:solr&fq=category:ksiazka&fq=section:ksiazki
有什么变化呢?在这个例子中,一个条目会写入到queryResultCache中;另外,还会有两个条目会写入到filterCache中。现在看一下下面的语句:
q=name:lucene&fq=category:ksiazka&fq=section:ksiazki
这个查询会创建一个条目到queryResultCache中,但是会使用filterCache中两个已经存在的条目。这样查询的执行时间会降低,IO的使用也会节省。 然而,对于下面的查询:
q=name:lucene+AND+category:ksiazka+AND+section:ksiazki
solr不能使用任何cache并且需要从lucene索引中收集所有的信息。
小结:
就像你所看到的,配置cache 的正确方法不是如何保证solr能够使用它【因为默认都会有solrconfig.xml的配置】,而是如何构建查询语句来提升性能。
2.3、filterCached的实例分析
从上面的分析可以看出,solr应用中为了提高查询速度有可以利用几种cache来优化查询速度,分别是fieldValueCache,queryResultCache,documentCache,filtercache,在日常使用中最为立竿见影,最有效的应属filtercache。谈到filterCache的作用,可以从一段Solr的查询日志开始说起,下面是截取的其中一段Solr的查询日志:
[search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A2+AND+class_id%3A1&sort=index_sort_order+desc&start=0&rows=5,queryTime_is ==> 2 [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A1+AND+class_id%3A1+AND+%28group_id%3A411%29&sort=gmt_create+desc&start=0&rows=20,queryTime_is ==> 2 [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A2+AND+class_id%3A1&sort=index_sort_order+desc&start=0&rows=5,queryTime_is ==> 2 [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A1+AND+class_id%3A1+AND+%28group_id%3A8059%29&sort=gmt_create+desc&start=0&rows=20,queryTime_is ==> 0 [search4alive-0] Request_is ==> debugQuery=on&group=true&group.field=group_id&group.ngroups=true&group.sort=gmt_create+desc&q=status%3A0++AND+biz_type%3A1+AND+class_id%3A1+AND+ha [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A2+AND+class_id%3A1&sort=index_sort_order+desc&start=30&rows=30,queryTime_is ==> 4 [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A2+AND+class_id%3A1&sort=index_sort_order+desc&start=0&rows=5,queryTime_is ==> 1 [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A1+AND+class_id%3A1+AND+%28group_id%3A375%29&sort=gmt_create+desc&start=0&rows=20,queryTime_is ==> 3 [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A2+AND+class_id%3A1&sort=index_sort_order+desc&start=0&rows=5,queryTime_is ==> 1 [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A2+AND+class_id%3A1&sort=index_sort_order+desc&start=0&rows=30,queryTime_is ==> 4 [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A2+AND+class_id%3A1&sort=index_sort_order+desc&start=0&rows=5,queryTime_is ==> 1 [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A2+AND+class_id%3A1&sort=index_sort_order+desc&start=0&rows=30,queryTime_is ==> 4 [search4alive-0] Request_is ==> q=status%3A0++AND+biz_type%3A2+AND+class_id%3A1&sort=index_sort_order+desc&start=0&rows=30,queryTime_is ==> 3
看到这段查询日志之后,我们开始考虑如何提升查询的rt(查询速度),因为在参数q中的查询是要有磁盘IO开销的,很自然的思路是将整个查询的参数q作为key,对应的结果作为value,这样做是可以的,但是查询的命中率会很低,会占用大量内存空间。
分析日志可知:查询参数q基本上每次都会出现status,biz_type,class_id 对于这样的查询,可以把整个查询条件分成两部分:一部分是以status,biz_type,class_id 这几个条件组成的子查询条件,另外一部分是除这三个条件之外的子查询。在进程查询的时候,先将status,biz_type,class_id 条件组成的条件作为key,对应的结果作为value进行缓存,然后再和另外一部分查询的结果进行求交运算。
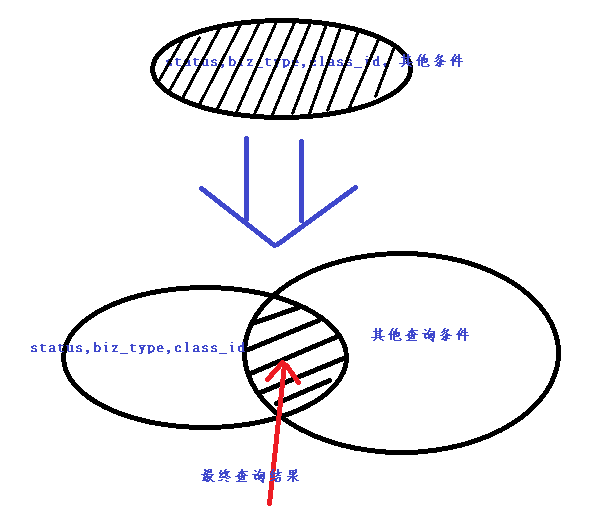
通过上面这幅图明白了filtercache的意义是,将原先一个普通查询分割成两个组合查询的与运算,两个子查询至少有一个使用缓存,这样既减少了查询过程的IO操作,又控制了缓存的容量不会消耗过多的内存。
客户端API调用:
下面是原先的客户端端查询代码:
SolrQuery query = new SolrQuery();
query.setQuery("status:0 AND biz_type:1 AND class_id:1 AND xxx:123");
QueryResponse response = qyeryServer.query(query);
使用filterQuery之后的查询代码:
SolrQuery query = new SolrQuery();
query.addFilterQuery("status:0 AND biz_type:1 AND class_id:1");
query.setQuery("xxx:123");
QueryResponse response = qyeryServer.query(query);
经过测试这样优化之后,查询的RT会明显减小,QPS会有明显提升。
使用filterquery过程中需要注意点:
1)不能在filterQuery 上重复出现query中的查询参数,如果上面的filterquery调用方法如下所示:
query.addFilterQuery("status:0 AND biz_type:1 AND class_id:1 AND xxx:123");
query.setQuery("xxx:123");如上,条件xxx:123 在filterQuery和query上都出现了,这样的写法非但起不到查询优化的目的,而且还会增加查询的性能开销。
2) 尽量减少调用addFilterQuery方法的次数
query.addFilterQuery("status:0 ");
query.addFilterQuery("biz_type:1 ");
query.addFilterQuery("class_id:1 ");
query.setQuery("xxx:123");如上,将status:0 AND biz_type:1 AND class_id:1 这个组合查询条件,分三次调用filterQuery方法来完成,这样的调用方法虽然是正确的,并且能起到性能优化的效果,优化性能没有调用一次addFilterQuery方法来得高,原因是多调用了两次addFilterQuery,就意味着最后需要多进行两次结果集的求交运算,虽然结果集求交运算速度很快,但毕竟是有性能损耗的。
不过从内存开销的角度来说,调用三次addfilterQuery方法这样可以有效降低内存的使用量,这个是肯定的。所以在是否调用多次addFilterQuery方法的原则是,在内存开销允许的前提下,将量将所有filterQuery条件,通过调用有限次数的addFilterQuery方法来完成。
2.3、queryResultCache
顾名思义,queryResultCache是对查询结果的缓存(SolrIndexSearcher中的cache缓存的都是document id set),这个结果就是针对查询条件的完全有序的结果。缓存的key是个什么结构呢?就是下面的类(key的hashcode就是QueryResultKey的成员变量hc):
public QueryResultKey(Query query, List filters, Sort sort, int nc_flags) {
this.query = query;
this.sort = sort;
this.filters = filters;
this.nc_flags = nc_flags;
int h = query.hashCode();
if (filters != null) h ^= filters.hashCode();
sfields = (this.sort !=null) ? this.sort.getSort() : defaultSort;
for (SortField sf : sfields) {
// mix the bits so that sortFields are position dependent
// so that a,b won't hash to the same value as b,a
h ^= (h << 8) | (h >>> 25); // reversible hash
if (sf.getField() != null) h += sf.getField().hashCode();
h += sf.getType();
if (sf.getReverse()) h=~h;
if (sf.getLocale()!=null) h+=sf.getLocale().hashCode();
if (sf.getFactory()!=null) h+=sf.getFactory().hashCode();
}
hc = h;
}
因为查询参数是有start和rows的,所以某个QueryResultKey可能命中了cache,但start和rows却不在cache的document id set范围内。当然,document id set是越大命中的概率越大,但这也会很浪费内存,这就需要个参数:queryResultWindowSize来指定document id set的大小。Solr5.x中默认取值为20,可配置,WIKI上的解释很深简单明了:
50
相比filterCache来说,queryResultCache内存使用上要更少一些,但它的效果如何就很难说。就索引数据来说,通常我们只是在索引上存储应用主键id,再从数据库等数据源获取其他需要的字段。这使得查询过程变成,首先通过solr得到document id set,再由Solr得到应用id集合,最后从外部数据源得到完成的查询结果。如果对查询结果正确性没有苛刻的要求,可以在Solr之外独立的缓存完整的查询结果(定时作废),这时queryResultCache就不是很有必要,否则可以考虑使用queryResultCache。当然,如果发现在queryResultCache生命周期内,query重合度很低,也不是很有必要开着它。
2.4、 documentCache
又顾名思义,documentCache用来保存
2.5、 User/Generic Caches
Solr支持自定义Cache,只需要实现自定义的regenerator即可,下面是配置示例:
2.6、 The Lucene FieldCache
lucene中有相对低级别的FieldCache,Solr并不对它做管理,所以,lucene的FieldCache还是由lucene的IndexSearcher来搞。
2.7、 autowarm
上面有提到autowarm,autowarm触发的时机有两个,一个是创建第一个Searcher时(firstSearcher),一个是创建个新Searcher(newSearcher)来代替当前的Searcher。在Searcher提供请求服务前,Searcher中的各个Cache可以做warm处理,处理的地方通常是SolrCache的init方法,而不同cache的warm策略也不一样。
1)filterCache:filterCache注册了下面的CacheRegenerator,就是由旧的key查询索引得到新值put到新cache中。
solrConfig.filterCacheConfig.setRegenerator(
new CacheRegenerator() {
public boolean regenerateItem(SolrIndexSearcher newSearcher, SolrCache newCache, SolrCache oldCache, Object oldKey, Object oldVal) throws IOException {
newSearcher.cacheDocSet((Query)oldKey, null, false);
return true;
}
}
);
2)queryResultCache:queryResultCache的autowarm不在SolrCache的init(也就是说,不是去遍历已有的queryResultCache中的query key执行查询),而是通过SolrEventListener接口的void newSearcher(SolrIndexSearcher newSearcher, SolrIndexSearcher currentSearcher)方法,来执行配置中特定的query查询,达到显示的预热lucene FieldCache的效果。
queryResultCache的配置示例如下:
anything name desc price desc populartiy desc
anything name desc, price desc, populartiy desc
anything
category
inStock:true
price:[0 TO 100]
3)documentCache:因为新索引的document id和索引文档的对应关系发生变化,所以documentCache没有warm的过程。尽管autowarm很好,也要注意autowarm带来的开销,这需要在实际中检验其warm的开销,也要注意Searcher的切换频率,避免因为warm和切换影响Searcher提供正常的查询服务。