R语言简单爬取网页信息并作出时序图
本文是学习R语言过程中的学习笔记
#抓取中南财经政法大学2013-2018年金融工程的历年招生信息
#所有信息来自于中南财经政法大学研究生院官网
install.packages("rvest")
library(rvest)
library(xml2)
#抓取中南财经政法大学2013-2018年金融工程的历年招生信息
#所有信息来自于中南财经政法大学研究生院官网
u<-read_html("http://yzb.zuel.edu.cn/2018/0523/c4637a192449/page.htm",encoding="UTF-8")
t2018<-u%>%
html_nodes("tr:nth-child(40) td")%>%
html_text()
u1<-read_html("http://yzb.zuel.edu.cn/2017/0622/c4637a169727/page.htm",encoding="UTF-8")
t2017<-u1%>%
html_nodes("tr:nth-child(42) td")%>%
html_text
u2<-read_html("http://yzb.zuel.edu.cn/2016/0624/c4637a155509/page.htm",encoding<-"UTF-8")
t2016<-u2%>%
html_nodes("tr:nth-child(38) p")%>%
html_text()
u3<-read_html("http://yzb.zuel.edu.cn/2015/0706/c4637a155508/page.htm",encoding<-"UTF-8")
t2015<-u3%>%
html_nodes("tr:nth-child(41) p")%>%
html_text()
u4<-read_html("http://yzb.zuel.edu.cn/2014/0818/c4637a155507/page.htm",encoding<-"UTF-8")
t2014<-u4%>%
html_nodes("tr:nth-child(41) p")%>%
html_text()
u5<-read_html("http://yzb.zuel.edu.cn/2013/0704/c4637a155506/page.htm",encoding<-"UTF-8")
t2013<-u5%>%
html_nodes("tr:nth-child(41) td")%>%
html_text()
考录统计<-data.frame(年份=c("2013年","2014年","2015年","2016年","2017年","2018年"),
专业=c(t2013[2],t2014[2],t2015[2],t2016[2],t2017[3],t2018[3]),
复试线=c(t2013[4],t2014[4],t2015[4],t2016[5],t2017[8],t2018[8]),
报考人数=c(t2013[5],t2014[5],t2015[5],t2016[6],t2017[5],t2018[5]),
录取数=c(t2013[6],t2014[6],t2015[6],t2016[7],t2017[6],t2018[6]),
保研数=c(t2013[7],t2014[7],t2015[7],t2016[8],t2017[7],t2018[7]))
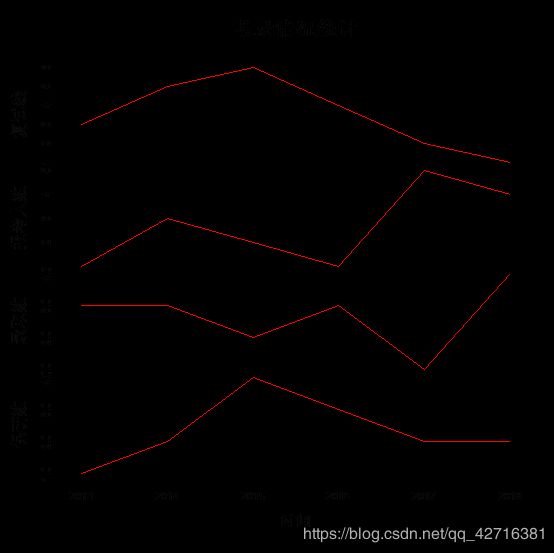
上述代码可得到的结果如下:

接下来绘制简单的时序图,进行可视化展示:
#绘制时序图
a=考录统计[,-c(1,2)]
c=ts(a,frequency=1,start=2013,end=2018)
plot(c,bty="l",col="red",main="考录情况统计",xlab="时间")
将数据数据写出成excel 文件:
#写出数据
write.csv(考录统计,row.names = FALSE,quote =FALSE,
file="中南财经政法大学2013-2018年金融工程硕士研究生招生情况统计表.xls")
写出的效果如下:
