[网络模型]在Object detection api上复现SSD_Mobilenetv3(一)
如何在Objection detection api上使用SSD_Mobilenetv3——第一部分
Object detection api是tensorflow官方提供的目标检测库,其中包含许多经典的目标检测论文代码,例如faster_rcnn_inception_resnet_v2、SSD、ssd_inception_v2、ssd_mobilenetv1/v2等,读者可以根据官方教程,训练自己的目标检测任务模型。这里推荐一篇博客:如何使用Google Object detection API訓練自己的模型。这篇博客主要介绍如何在该API上实现SSD-Mobilenetv3,因此上述内容不再赘述。
Mobilenetv3【论文地址:Searching for MobileNetV3】,该论文由谷歌研究院于2019年5月6日发表,是Mobilenet系列的第三版本,主要贡献有以下四点:
(1)用NAS搜索整体的网络架构;
(2)用NetAdapt搜索合适的网络宽度;
(3)引入注意力机制的SE模块;
(4)引入h-swish激活函数;
最终得到了Mobilenetv3_large和Mobilenetv3_small两个网络模型,可根据需求进行模型选取。但是,从论文发表直到现在,官方还未提供开源的代码,网上有一些大佬贡献的基于pytorch和tensorflow的代码,但是也只能用于分类任务,完全无法满足我的需求(哈哈)。因此,本文尝试将v3与SSD结合在一起,实现和Object detection api上一样的目标检测功能,采用与官方教程同样的流程便可以实现特定的目标检测任务。参考链接
MobileNetV3与V2模型结构差异:
宏观差异:
两者之间宏观的差异在于整体的网络框架,V2一共21层(第1层、第19层、第21层为传统卷积层;第20层为全局平局池化层,其余层均为bottleneck层);V3采用了NAS和NetAdapt技术搜索得到了Large/Small两个模型架构,以Small为例(第1层、第15层、第16层为普通卷积层,第14层为全局池化层,第12层为带有SE模块的卷积层,其余均为bottleneck层),而且,在V3已经不再局限于使用33卷积,出现了大量的55卷积核。
如下图所示(左侧为V2分类模型,右侧为V3-Small分类模型):
![[网络模型]在Object detection api上复现SSD_Mobilenetv3(一)_第1张图片](http://img.e-com-net.com/image/info8/8487d103d83f42868c035cf35c6d8069.jpg)
微观差异:
两者之间微观的差异体现在三个部分:
(1)bottleneck的结构不同:
V3中,作者引入了当前深度学习网络模型中像shortcut一样火的Squeeze-and-Excitation Networks注意力结构,对depthwise后的特征图进行分通道全局池化,并通过全连接层对池化后的特征图进行通道重要性评估,并将权重系数应用于特征图的每个通道,以此来分配给不同的特征图通道不同的比重。下图为V3中的bottleneck:
![[网络模型]在Object detection api上复现SSD_Mobilenetv3(一)_第2张图片](http://img.e-com-net.com/image/info8/37c84d9bb17646a6b49d41e64a7028e1.jpg)
图中,黄色区域便是V3与V2 bottleneck结构的差异。
(2)网络末尾结构调整:
V3中,作者除了采用NAD/NetAdapt进行模型搜索,还有一定的人工参与。在网络的最后一个阶段,原始的模型如下图所示:
![[网络模型]在Object detection api上复现SSD_Mobilenetv3(一)_第3张图片](http://img.e-com-net.com/image/info8/234ab231321c48eb9d0b8a856494d7aa.jpg)
作者将全局平局池化层提前,并且去掉了Depthwise特征提取层、1*1通道收缩层,发现这样操作不仅大幅度提升了模型的效率,还不会丢失准确度。更改后的模型末端如下图所示:
![[网络模型]在Object detection api上复现SSD_Mobilenetv3(一)_第4张图片](http://img.e-com-net.com/image/info8/b6dfc51a6f1343459c96223ff37b0720.jpg)
(3)h-swish激活函数:
在之前的工作中,也是谷歌团队采用搜索的方式,得到了一个比Relu6效果更好的激活函数(x﹡σ(βx)),被称为Swish,其中σ(βx)为sigmoid函数,但是在硬件部署中,sigmoid的指数运算麻烦且不易实现,因此需要采用一种易于实现的函数与拟合它,因此作者在V3中提出了hard-swish,将分段函数Relu6通过线性变换拟合sigmoid函数,
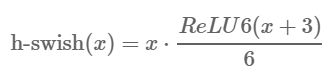
两者的曲线如下图所示,可以看到,十分的接近:
![[网络模型]在Object detection api上复现SSD_Mobilenetv3(一)_第5张图片](http://img.e-com-net.com/image/info8/47da10ff36c041beb6d8ac2b51863bdb.jpg)
到这里,v3与v2的模型差异已经讲的很清楚了,接下来就是如何去实现这个网络,并可以在Object detection api中直接调用。
SSD_Mobilenetv3的Object detection api实现:
在Object detection api中如何创建自己的模型可以参考So you want to create a new model!
整体思路就是:建立Mbolinet_v3主网络→SSD调用该网络实现多尺度目标检测
整个代码文件结构:
research/object_detection/models/ssd_mobilenet_v3_feature_extractor.py
research/object_detection/builders/model_builder.py
research/nets/mobilenet/mobilenet_v3.py
research/nets/mobilenet/conv_blocks_v3.py
(1)SSD调用该网络实现多尺度目标检测:
首先我们想要创建一个SSD Feature Extractor,进入到目录object_detection/models/,创建ssd_mobilenet_v3_feature_extractor.py文件,我们可以将ssd_mobilenet_v2_feature_extractor.py中的代码复制过来,在此基础上进行部分修改:
#调用ssd——mata_arch,表示该特征提取文件属于ssd解析器(区别于faster_rcnn解析器)
from object_detection.meta_architectures import ssd_meta_arch
#26行 from nets.mobilenet import mobilenet_v3
#将其中的“SSDMobileNetV2FeatureExtractor”全部改为“SSDMobileNetV3FeatureExtractor”,共两处
#31行
class SSDMobileNetV3FeatureExtractor(ssd_meta_arch.SSDFeatureExtractor):
"""SSD Feature Extractor using MobilenetV2 features."""
#66行
super(SSDMobileNetV3FeatureExtractor, self).__init__(
is_training=is_training,
depth_multiplier=depth_multiplier,
min_depth=min_depth,
pad_to_multiple=pad_to_multiple,
conv_hyperparams_fn=conv_hyperparams_fn,
reuse_weights=reuse_weights,
use_explicit_padding=use_explicit_padding,
use_depthwise=use_depthwise,
override_base_feature_extractor_hyperparams=
override_base_feature_extractor_hyperparams)
#将文件中所有mobilenet_v2替换为mobilenet_v3,共两处
#122行
mobilenet_v3.training_scope(is_training=None, bn_decay=0.9997)), \
#128行
_, image_features = mobilenet_v3.mobilenet_base(
然后,进入目录object_detection/builders/model_builder.py,
#在第50行加入下面语句,添加自己创建的特征提取网络
from object_detection.models.ssd_mobilenet_v3_feature_extractor import SSDMobileNetV3FeatureExtractor
#在第67行加入下面语句
'ssd_mobilenet_v3': SSDMobileNetV3FeatureExtractor,
# 这样我们在pipeline_config文件中,
feature_extractor {
type: 'ssd_mobilenet_v3'#此处,直接输入“ssd_mobilenet_v3”,便可以调用我们设计的ssd_mobilenet_v3网络模型
min_depth: 16
depth_multiplier: 1.0
use_depthwise: true
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.9997,
epsilon: 0.001,
}
}
}
(2)设计Mobilenet_v3主网络:
经过上面两个步骤,我们已经实现了从config文件去调取我们的模型结构,接下来就是设计我们的V3模型,这一部分内容较多,放多下一篇博客:地址。