xlwings - 报表自动换算、汇总
文章目录
- 需求
- 现状
- 解决方案
- 环境 & 工具
- 主函数代码流程图
- 代码
- 代码打包
- 注意事项
- Q/A
需求
excel报表自动汇总。
现状
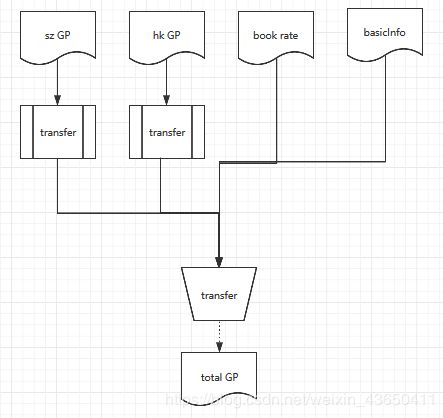
解决方案
1.基于Python的xlwings包,完成报表数据转换、换算、汇总。
2.使用PyInstaller将代码打包,降低使用门坎。
环境 & 工具
Win7
Excel
Anaconda3
- xlwings 0.16.0
- pandas 0.23.3
- PyInstaller 3.6
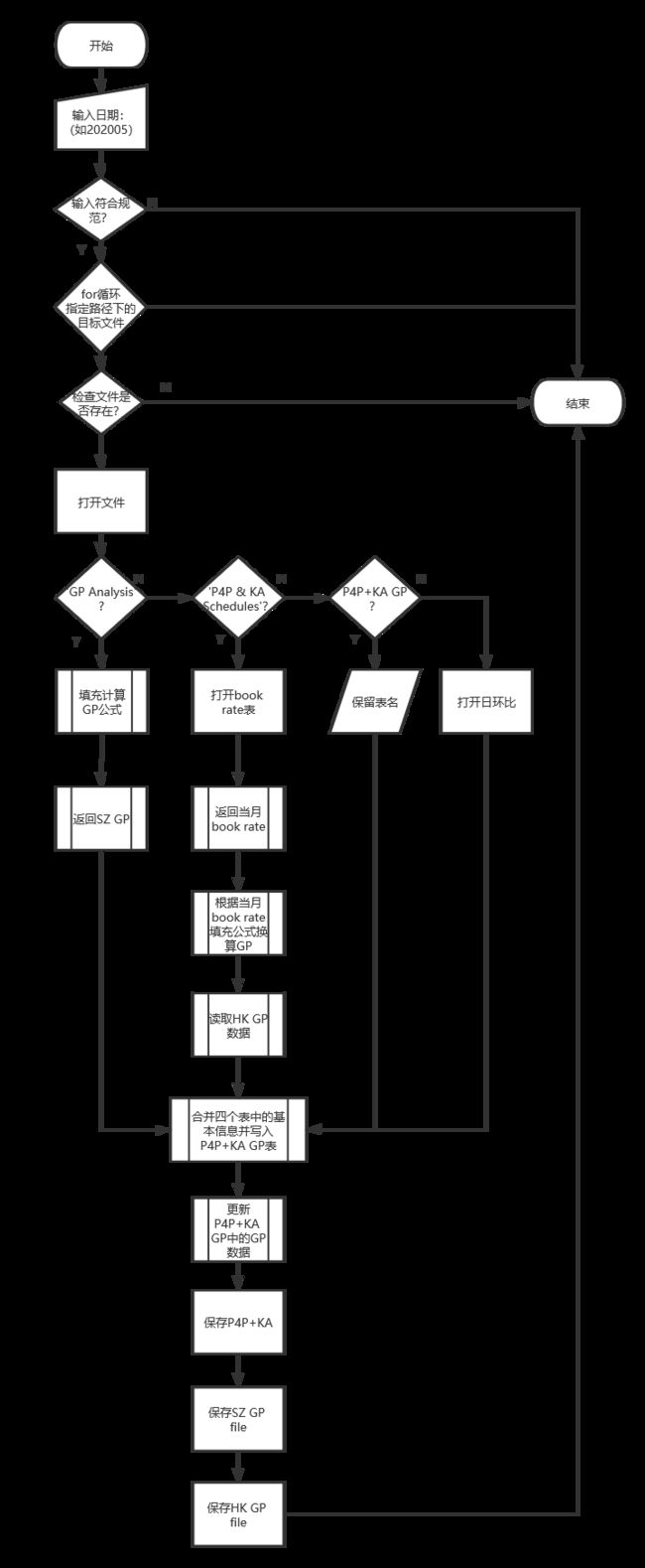
主函数代码流程图
代码
# -*- conding: utf-8 _*_
'''
autoGP.py
/ 假设Metrics为模版输出
'''
from xlwings import constants
import xlwings as xw
import pandas as pd
import datetime
import time
import os
now = lambda: time.perf_counter()
PATH = os.path.join(os.path.expanduser('~'),r'Desktop\Metrics')
def check(strDat):
try:
# 检查输入为整数
int(strDat)
# 检查输入是否为:年月
datetime.datetime.strptime(strDat, '%Y%m')
except (TypeError, ValueError):
raise Exception('请按要求输入,如当前为5月,则输入:202005')
else:
return strDat
def getM(dat):
return datetime.datetime.strptime(dat, '%Y%m').strftime('%b')
def getFil(dat):
# gp sz+hk
lis = [f for f in os.listdir(PATH)
if 'P4P+KA GP_' + dat == f.split('.')[0]]
## 检查
if len(lis) == 0 or (len(lis) == 1 and 'P4P+KA GP' not in lis[0]):
raise FileNotFoundError('指定路径下:"P4P+KA GP_%s.xlsx"文件不存在\
\n补充文件后重新运行。' % dat)
# gp sz, hk
fil = [f for l in os.walk(PATH) for f in l[2]
if 'GP Analysis-' + dat == f.split('.')[0]
or 'P4P & KA Schedules ' + dat + ' - Janice' == f.split('.')[0]]
## check
if len(fil) < 2:
raise FileNotFoundError('指定路径下:"GP Analysis-%s.xlsx"\
或"P4P & KA Schedules %s"文件不存在\
\n补充文件后重新运行。' % (dat,dat))
##
lis += fil
# book rate
cnt = 0
while not (('Ex rate '
+ (datetime.datetime.strptime(dat, '%Y%m')
+ datetime.timedelta(cnt)).strftime('%m-%Y')
+ '_book rate.xlsx') in os.listdir(list(os.walk(PATH))[1][0])):
cnt += 20
## 检查
if cnt == 200:
raise FileNotFoundError("指定路径下没找到 'book rate' 文件.\
补充文件后重新运行。")
name = ('Ex rate '
+ (datetime.datetime.strptime(dat, '%Y%m')
+ datetime.timedelta(cnt)).strftime('%m-%Y')
+ '_book rate.xlsx')
lis.append(name)
# daily ring ratio
lis_1 = [f for f in os.listdir(list(os.walk(PATH))[1][0])
if '日环比' in f and '~' not in f]
## 检查
if len(lis_1) == 0:
raise FileNotFoundError('指定路径下没找到 *日环比* 文件.\
补充文件后重新运行')
lis_1 = sorted(lis_1
, key=lambda x: os.path.getmtime(os.path.join(
list(os.walk(PATH))[1][0], x))
, reverse=True)
lis.append(lis_1[0])
return lis
def getSZ(wb, dat):
sht = wb.sheets[dat]
cntR = sht[0, 0].current_region.rows.count
# 参数检查
if '账户名称' not in sht['A1:AV1'].value:
wb.close()
raise ValueError('SZ GP表中 *账户名称* 不存在或错误,\
请检查excel后重新运行。')
#
df = pd.DataFrame(sht['A2:AV' + str(cntR)].value
, columns=sht['A1:AV1'].value)
# 去重
df = df.groupby(['账户名称']).sum()
df.reset_index(inplace=True)
return df
def getHK(wb, dat):
sht = wb.sheets['P4P ' + dat]
cntR = sht[4, 0].current_region.rows.count
cntC = sht[4, 0].current_region.columns.count
# 参数检查
if '用户名' not in sht[4, :cntC].value:
wb.close()
raise ValueError("HK GP表中 *用户名* 不存在,请检查excel后重新动行。")
#
df1 = pd.DataFrame(sht[5:cntR+4, :cntC].value
, columns=sht[4, :cntC].value)
# 去重
df1 = df1.groupby(['用户名']).sum()
df1.reset_index(inplace=True)
return df1
def result(sz, hk, f, strDat):
'''
将sz, hk的gp汇总写入指定表单P4P
Parameters
----------
sz : TYPE
DESCRIPTION.
hk : TYPE
DESCRIPTION.
f : TYPE
DESCRIPTION.
strDat : TYPE
DESCRIPTION.
Raises
------
ValueError
DESCRIPTION.检查表头是否符合规范
Returns
-------
None.
'''
try:
wb = xw.books(f)
sht = wb.sheets['P4P']
cntR = sht[1, 0].current_region.rows.count
cntC = sht[1, 0].current_region.columns.count
# 获取表头
lis = sht[1, :cntC].value
col = lis.index('用户名') + 1
# target file
df2 = pd.DataFrame(sht[2:cntR, :col].value
, columns=sht[1, :col].value)
# merge sz
df3 = pd.merge(df2, sz[['账户名称', 'p4p spending /1.06', 'GP_']]
, left_on='用户名', right_on='账户名称', how='left')
# merge hk
df4 = pd.merge(df3, hk[['用户名', "+HK Sales(RMB)", 'HK GP(RMB)']]
, on='用户名', how='left')
df4.fillna(0, inplace=True)
# write to
## 参数检查 (表头)
header = ['Revenue ' + getM(strDat) + ' HK',
'Revenue ' + getM(strDat) + ' SZ',
'GP ' + getM(strDat) + ' HK',
'GP ' + getM(strDat) + ' SZ']
if header[0] not in lis:
raise ValueError('检查[%s]表头应为: %s' % (wb.name, header[0]))
if header[1] not in lis:
raise ValueError('检查[%s]表头应为: %s' % (wb.name, header[1]))
if header[2] not in lis:
raise ValueError('检查[%s]表头应为: %s' % (wb.name, header[2]))
if header[3] not in lis:
raise ValueError('检查[%s]表头应为: %s' % (wb.name, header[3]))
## 赋值
sht[2, lis.index('Revenue ' + getM(strDat) + ' HK')
].options(transpose=True).value = df4['+HK Sales(RMB)'].values
sht[2, lis.index('Revenue ' + getM(strDat) + ' SZ')
].options(transpose=True).value = df4['p4p spending /1.06'].values
sht[2, lis.index('GP ' + getM(strDat) + ' HK')
].options(transpose=True).value = df4['HK GP(RMB)'].values
sht[2, lis.index('GP ' + getM(strDat) + ' SZ')
].options(transpose=True).value = df4['GP_'].values
# region
num_region = len(sht['A2:' +
sht['A2'].end(
'down').get_address(False, False)].value) + 1
num_user = len(sht['C2:' +
sht['C2'].end(
'down').get_address(False, False)]) + 1
for r in range(1, num_user - num_region + 1):
if 'cny' in sht['A' + str(num_region + r)].offset(0, 2).value:
sht['A' + str(num_region + r)].value = 'SZ'
else:
sht['A' + str(num_region + r)].value = 'HK'
# save
wb.save()
except ValueError:
wb.close()
raise
def calc_sz(wb, strDat):
'''
填充公式计算SZ消费 & GP
# [p4p spending /1.06]
= ([Total P4P Spending(Inc 6%VAT)]
+[ 新产品消费(Inc 6%VAT)]
+ [点击调整(Inc 6%VAT) ]
+[ 原生总消费])/1.06
# GP_ = ([p4p spending/1.06]*1.06
-([Cost(Inc 6% VAT)]
+[原生信息流Cost(Inc 6% VAT)]
+[ 原生信息流Rebate&赠送(Inc 6% VAT)]
+[Rebate&赠送(Inc 6% VAT)]
+[V Cost(Inc 6% VAT)])/1.06
Parameters
----------
wb : TYPE
SZ GP excel表
strDat : TYPE
输入的目标月度。如2月,即202002
Raises
------
ValueError
参数检查
表头值是否符合规范
Returns
-------
TYPE
DESCRIPTION.
'''
def getAddress(header, value):
return sht[1, header.index(value)].get_address(False, False)
# 先清除筛选
sht = wb.sheets[strDat]
sht.api.AutoFilterMode = False
# p4p spending /1.06
header = sht['A1:AT1'].value
# check 表头值
lis = ['Total P4P Spending(Inc 6%VAT)',
'新产品消费(Inc 6%VAT)',
'点击调整(Inc 6%VAT)',
'原生总消费',
'Cost(Inc 6% VAT)',
'原生信息流Cost(Inc 6% VAT)',
'原生信息流Rebate&赠送(Inc 6% VAT)',
'Rebate&赠送(Inc 6% VAT)',
'V Cost(Inc 6% VAT)']
##
if (lis[0] not in header):
raise ValueError('请检查excel表头值: %s' % lis[0])
if (lis[1] not in header):
raise ValueError('请检查excel表头值: %s' % lis[1])
if (lis[2] not in header):
raise ValueError('请检查excel表头值: %s' % lis[2])
if (lis[3] not in header):
raise ValueError('请检查excel表头值: %s' % lis[3])
if (lis[4] not in header):
raise ValueError('请检查excel表头值: %s' % lis[4])
if (lis[5] not in header):
raise ValueError('请检查excel表头值: %s' % lis[5])
if (lis[6] not in header):
raise ValueError('请检查excel表头值: %s' % lis[6])
if (lis[7] not in header):
raise ValueError('请检查excel表头值: %s' % lis[7])
if (lis[8] not in header):
raise ValueError('请检查excel表头值: %s' % lis[8])
# 换算
sht[0, len(header)].value = 'p4p spending /1.06'
sht[1, len(header)].formula = ('=(' +
getAddress(header,
'Total P4P Spending(Inc 6%VAT)')
+ '+' + getAddress(header,
'新产品消费(Inc 6%VAT)')
+ '+' + getAddress(header,
'点击调整(Inc 6%VAT)')
+ '+' + getAddress(header, '原生总消费')
+ ')/1.06')
# GP
sht[0, len(header) + 1].value = 'GP_'
sht[1, len(header) + 1].formula = ('=(' +
sht[1, len(header)
].get_address(False, False) +
'*1.06-(' +
getAddress(header, 'Cost(Inc 6% VAT)')
+ '+' +
getAddress(header,
'原生信息流Cost(Inc 6% VAT)')
+ '+' +
getAddress(header,
'原生信息流Rebate&赠送(Inc 6% VAT)')
+ '+' +
getAddress(header,
'Rebate&赠送(Inc 6% VAT)')
+ '+' +
getAddress(header,
'V Cost(Inc 6% VAT)')
+ '))/1.06')
# 填充
## 剔除KA
cntR = sht['A1'].current_region.rows.count
lis = [i for i in sht[1:cntR, 0].value if isinstance(i, float)]
sht[1, len(header):len(header)+2].api.AutoFill(
sht[1:len(lis) + 1, len(header):len(header)+2].api
, constants.AutoFillType.xlFillCopy)
# 计算
wb.app.calculate()
def calc_hk(wb, strDat, rate='1.2'):
'''
填充公式,计算HK GP
Parameters
----------
wb : TYPE
DESCRIPTION.
strDat : TYPE
DESCRIPTION.
rate : TYPE, optional
DESCRIPTION. The default is '1.2'.
Raises
------
ValueError
参数检查
检查表头值是否符合规范。
Returns
-------
None.
'''
# 先清除筛选
sht = wb.sheets['P4P ' + strDat]
sht.api.AutoFilterMode = False
## 总行数
cntR = sht[4, 1].current_region.rows.count + 4
cntC = sht[4, 1].current_region.columns.count
# 检查表头
header = sht[4, :cntC].value
if header[2] != '用户名':
raise ValueError("检查[%s]表头: %s" % (wb.name, header[2]))
if header[3] != 'HK Sales':
raise ValueError("检查[%s]表头: %s" % (wb.name, header[3]))
if header[4] != 'HK Service':
raise ValueError("检查[%s]表头: %s" % (wb.name, header[4]))
if header[5] != 'HK Media Cost':
raise ValueError("检查[%s]表头: %s" % (wb.name, header[5]))
if header[6] == 'HK Client Rebate ' or header[6] == 'HK Client Rebate':
pass
else:
raise ValueError("检查[%s]表头: %s" % (wb.name, header[6]))
## 插入列
sht.api.Columns(5).Insert()
sht.api.Columns(5).Insert()
## +HK Sales
sht[4, 4].value = '+HK Sales'
sht[5, 4].formula = '=-' + sht[5, 3].get_address(False, False)
## +HK Sales(RMB)
sht[4, 5].value = '+HK Sales(RMB)'
sht[5, 5].formula = '=' + sht[5, 4].get_address(False, False) + '/' + rate
sht[5, 4:6].api.AutoFill(sht[5:cntR, 4:6].api
, constants.AutoFillType.xlFillCopy)
## HK Client Rebate
cntC = sht[4, 1].current_region.columns.count
##
sht[4, cntC].value = 'Client Rebate(RMB)'
sht[5, cntC].formula = '=' + sht[5, cntC-1].get_address(False, False
) + '/' + rate
## HK GP
header = tuple(map(lambda x: x.strip(), sht[4, :cntC + 1].value))
sht[4, cntC + 1].value = 'HK GP'
sht[5, cntC + 1].formula = ('=' + sht[5, header.index('+HK Sales')
].get_address(False, False) + '-'
+ sht[5, header.index('HK Media Cost')
].get_address(False, False) + '-'
+ sht[5, header.index('HK Client Rebate')
].get_address(False, False))
## HK GP(RMB)
sht[4, cntC + 2].value = 'HK GP(RMB)'
sht[5, cntC + 2].formula = ('=' + sht[5, cntC + 1
].get_address(False, False)
+ '/' + rate)
## 向下填充
sht[5, cntC:cntC + 3].api.AutoFill(sht[5:cntR, cntC:cntC + 3].api,
constants.AutoFillType.xlFillCopy)
## 字体
sht[4, cntC:cntC + 3].api.Font.Size = sht[4, cntC - 1].api.Font.Size
sht[4, cntC:cntC + 3].api.Font.Bold = True
sht[4, cntC:cntC + 3].api.Borders(9).LineStyle = 1
sht[4, cntC:cntC + 3].api.Borders(9).Weight = 3
sht.autofit()
# 计算
wb.app.calculate()
def getRate(wb, strDat):
'''
获取指定月度book rate值
Parameters
----------
wb : TYPE
DESCRIPTION.
strDat : TYPE
DESCRIPTION.
Returns
-------
TYPE
DESCRIPTION.
'''
# 锁定表
# 锁定目标值位置、取值
def getValue(shtName):
sht = wb.sheets[shtName]
cntR = sht[3, 1].current_region.rows.count
for n, j in enumerate(sht[3:cntR+3, 1].value):
if isinstance(j, datetime.datetime):
j = j.strftime('%Y%m')
if strDat == j:
return str(sht[3 + n, 2].value)
listTable = [i.name for i in wb.sheets]
# 从最近9个月查找
for i in range(1, 1000):
if strDat in listTable:
return getValue(strDat)
else:
intDat = int(strDat)
intDat += i
if str(intDat) in listTable:
return getValue(str(intDat))
else:
intDat = int(strDat)
intDat -= i
if str(intDat) in listTable:
return getValue(str(intDat))
def writeTo(strDat):
'''
更新汇总表单中的P4P基本信息
Parameters
----------
strDat : TYPE
DESCRIPTION.
Returns
-------
TYPE
DESCRIPTION.
'''
def getBasicInfo():
# 获取账户基本信
daily_ = [f for f in getFil(strDat) if '日环比' in f]
wb = xw.books(daily_[0].split('.')[0])
sht = wb.sheets['P4P消费']
cntC = sht['A1'].current_region.columns.count
cntR = sht['A1'].current_region.rows.count
lis = sht[0, :cntC].value
# region, user
region = sht[9:cntR, lis.index('区域')].value
user = sht[9:cntR, lis.index('用户名')].value
port = sht[9:cntR, lis.index('端口')].value
return region, user, port
def getFilName(region):
lis_fil = [f for f in getFil(strDat) if region in f]
wb = xw.books(lis_fil[0].split('.')[0])
return wb
def dropDuplicates_1():
# 准备数据
#
## sz
wb_sz = getFilName('GP Analysis')
df_sz = getSZ(wb_sz, strDat)
### Series
s_sz = df_sz.loc[(df_sz['p4p spending /1.06']+df_sz['GP_'])!=0
, '账户名称']
#
## hk
wb_hk = getFilName('P4P & KA')
df_hk = getHK(wb_hk, strDat)
### Series
s_hk = df_hk.loc[(df_hk['+HK Sales(RMB)']+df_hk['HK GP(RMB)'])!=0
, '用户名']
#
b_user = pd.Series(getBasicInfo()[1])
b_user = b_user.append(s_sz).append(s_hk)
b_user.drop_duplicates(inplace=True)
return b_user.values
def addNull(dic):
# 补空值
max_ = max([len(v) for k, v in dic.items()])
for k, v in dic.items():
if len(v) < max_:
dic[k] = v + [None] * (max_ - len(v))
wb = xw.books('P4P+KA GP_' + strDat)
sht = wb.sheets['P4P']
cntC = sht['A2'].current_region.columns.count
cntR = sht['A2'].current_region.rows.count
header = sht[1, :cntC].value
# region
# 已有数据
old_data = pd.DataFrame(sht[2:cntR, header.index('区域'):
header.index('用户名')+1].value
, columns=['区域', '端口', '用户名'])
# 新增
dic = {'区域': getBasicInfo()[0],
'端口': getBasicInfo()[2],
'用户名': dropDuplicates_1()}
addNull(dic)
# 合并,去重
old_data = old_data.append(pd.DataFrame(dic)).drop_duplicates('用户名')
sht['A3'].value = old_data.values
def main():
'''
主程序
Raises
------
Exception
DESCRIPTION.
Returns
-------
None.
'''
try:
# 输入,检查
strDat = check(input('输入目标月度(如当前为5月: 202005)'))
#
for n, f in enumerate(getFil(strDat)):
print(n, f)
if n == 0:
if os.path.exists(os.path.join(list(os.walk(PATH))[0][0], f)):
xw.Book(os.path.join(list(os.walk(PATH))[0][0], f))
else:
raise FileNotFoundError('文件不存在: %s' % f)
else:
if os.path.exists(os.path.join(list(os.walk(PATH))[1][0], f)):
xw.Book(os.path.join(list(os.walk(PATH))[1][0], f))
else:
raise FileNotFoundError('文件不存在: %s' % f)
#
if 'GP Analysis' in f:
wb1 = xw.books(f)
calc_sz(wb1, strDat)
#
data_sz = getSZ(wb1, strDat)
elif 'P4P & KA Schedules' in f:
wb = xw.books(f)
# rate
## open book rate file
bookRate = list(filter(lambda x: 'book rate' in x
, getFil(strDat)))[0]
xw.Book(os.path.join(list(os.walk(PATH))[1][0], bookRate))
rate = getRate(xw.books(bookRate.split('.')[0]), strDat)
# 换算hk gp
calc_hk(wb, strDat, rate)
#
data_hk = getHK(wb, strDat)
elif 'P4P+KA' in f:
target = f
# update basicInfo
writeTo(strDat)
# update spending
result(data_sz, data_hk, target, strDat)
except ValueError:
wb.close()
wb1.close()
raise
except Exception as e:
print(e)
else:
wb.save()
wb1.save()
if __name__ == '__main__':
st = now()
main()
print("程序运行结束,耗时: %s" %(now() - st))
time.sleep(60)
代码打包
# Anaconda Prompt
# 打包为单个可执行文件
PyInstaller -F autoGP.py
注意事项
1.所有输入excel必须按模版要求进行整理;
2.要提前对所有输入的参数进行检查,以便出现异常时给出友好的提示;
3.准备操作流程指南:

Q/A
# 获取本地用户路径
# os.path.expanduser('~')
#
PATH = os.path.join(os.path.expanduser('~'),r'Desktop\Metrics')