剖析Memcached分布式内存对象缓存系统的工作原理
Memcached是一种C/S模式,在服务器端启动服务守护进程,此时可以指定监听的IP地址、端口号以及使用多少内存来处理客户端的请求等几个关键参数。服务器端的服务启动后就一直处于等待处理客户端的连接状态。Memcached是由C语言来实现的,采用的是异步I/O,其实现方式是基于事件的单进程和单线程的。使用libevent作为事件通知机制,多个服务器端可以协同工作,但这些服务器端之间没有任何通信关系,每个服务器端只对自己的数据进行管理。客户端通过指定服务器的IP地址和端口进行通信。
需要被缓存的对象或数据以key/value对的形式保存在服务器端,每个被缓存的对象或数据都有唯一的标识符key,存取操作通过这个key进行。保存到Memcached中的对象或数据放置在内存中,并不会作为文件存储在磁盘上,所以存取速度非常快。由于没有对这些对象进行持久性存储,因此在服务器端的服务重启之后存储在内存中的这些数据就会消失。而且当存储的容量达到启动时设定的值时,就自动使用LRU算法删除不用的缓存。Memcached是为缓存而设计的服务器,因此在设计之初并没有过多考虑数据的永久性问题。Memcached支持各种语言编写的客户端API,目前包括Perl、PHP、Python、Ruby、Java、C#和C等。
Slab Allocation的工作机制
Memcached利用Slab Allocation机制来分配和管理内存。传统的内存管理方式是:使用完通过malloc分配的内存后通过free来回收内存。这种方式容易产生内存碎片并降低操作系统对内存的管理效率。Slab Allocation机制不存在这样的问题,它按照预先规定的大小,将分配的内存分割成特定长度的内存块,再把尺寸相同的内存块分成组,这些内存块不会释
放,可以重复利用。
Memcached服务器端保存着一个空闲的内存块列表,当有数据存入时根据接收到的数据大小,分配一个能存下这个数据的最小内存块。这种方式有时会造成内存浪费,例如:将一个200字节的数据存入一个300字节的内存块中,会有100字节内存被浪费掉,不能使用。避免浪费内存的办法是,预先计算出应用存入的数据大小,或把同一业务类型的数据存入一个Memcached服务器中,确保存入的数据大小相对均匀,这样就可以减少对内存的浪费。还有一种办法是,在启动时指定“-f"参数,能在某种程度上控制内存组之间的大小差异。在应用中使用Memcached时,通常可以不重新设置这个参数,使用默认值1.25进行部
署。如果想优化Memcached对内存的使用,可以考虑重新计算数据的预期平均长度,调整这个参数来获得合适的设置值。
Memcached的删除机制
上一节已经介绍过,Memcached不会释放已分配的内存窒间,在数据过期后,客户端不能通过key取出它的值,其存储空间被重新利用。
Memcached使用的是一种Lazy Expiration策略,自己不会监控存入的key/value对是否过期,而是在获取key值时查看记录的时间戳,检查kcy/value对空间是否过期。这种策略不会在过期检测上浪费CPU资源。
Memcached在分配空间时,优先使用已经过期的key/value对空间,当空间占满时,Memcached就会使用LRU算法来分配空间,删除最近最少使用的key/value对,将其空间分配给新的key/value对。在某些情况下,如果不想使用LRU算法,那么可以通过“-M”参数来启动Memcached,这样,Memcached在内存耗尽时,会返回一个报错信息。
Memcached的分布式算法
前面已经介绍过,Memcached的分布式是通过客户端的程序库来实现的。下面举例描述其工作过程。
假设有nodel、node2、node2三台Mcmcached服务器,应用程序要实现保存名为“tokyo”、“tokyol”、“toky02”、“toky03”的数据,如图3-2所示。
图3-2 向Memcached中存人数据的初始状态

向Memcached中存入“tokyo”,将“tokyo”传给客户端程序后,客户端实现的算法就会根据这个“键”来决定保存数据的Memcached服务器,选定服务器后,就命令该服务器保存“tokyo”及其值,如图3-3所示。
同样,存入“tokyol”、“toky02”和“toky03”的过程都是先通过客户端的算法选择服务器再保存数据。
接下来获取保存的数据。获取保存的key/value对时也要将要获取的键“tokyo”传递给函数库。函数库通过与存取数据操作相同的算法,根据“键”来选择服务器。只要使用的算法相同,就能确定存入在哪一台服务器上,然后发送get命令。只要数据没有因为某些原因被删除,就能获得保存的值,如图3-4所示。
图3-3 向Memcached中存入“tokyo”

图3-4 向Memcached获取“tokyo”的过程

将不同的键保存到不同的服务器上,就实现了Memcached的分布式算法。部署多台Memcached服务器时,将键分散保存到这些服务器上,当某一台Memcached服务器发生故障无法连接时,只有分散到这台服务器上的key/values对不能访问,其他key/value对不受影响。
目前有两种分布式算法使用得最多,一种是根据余数来计算分布,另一种是根据一致性散列算法来计算分布。根据余数分布式算法先求得键的整数散列值,再除以服务器台数,根据余数来选择将键存放到哪一台服务器上。这种方法虽然计算简单,效率很高,但在服务器增加或减少时,会导致几乎所有的缓存失效,所以在大规模部署中,很少使用这种方法。一致性散列的原理如图3-5所示,先算出Memcached服务器(节点)的散列值,并将其分散到O到2的32次方的圆上,然后用同样的方法算出存储数据的键的散列值并映射到圆上,最后从数据映射到的位置开始顺时针查找,将数据保存到查找到的第一个服务器上。如果超过2的32次方仍然找不到服务器,就会将数据保存到第一台Memcached服务器上。
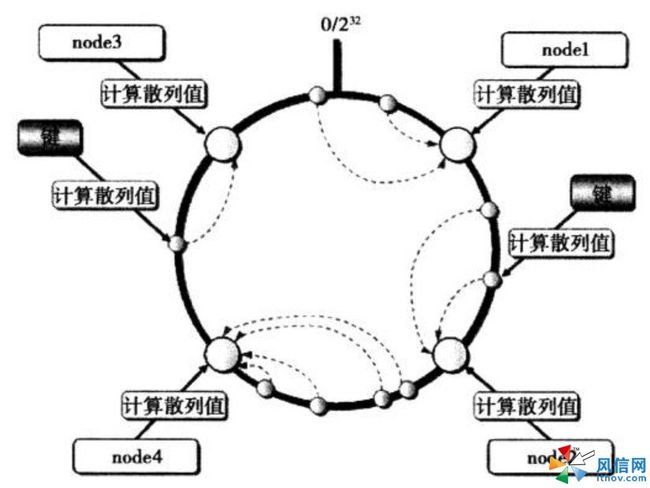
图3-5 一致性散列算法的原理
当需要添加一台Memcached眼务器时,由于保存键的服务器的个数发生了变化,因此余数分布式算法的余数结果也会发生巨大变化,几乎所有的键都找不到之前存入的服务器,导致所有的缓存失效。但在采用一致性散列算法时,添加服务器后,只有在圆上增加服务器地点的逆时针方向的第一台服务器上的键会受到影响,如图3-6所示。
一致性散列算法对数据的存储是不均匀的,但可以最大限度地减少缓存的失效量。在大规模部署Memcached时,容灾和扩容一定要使用一致性散列算法,以确保在出现故障或容量问题时减小对数据库的影响。

图3-6 在使用一致性散列算法时增加一台新服务器