YOLO源码学习(一)
在学习完YOLOv1论文后,我比较想了解为什么通过这样的网络就能预测出来一张图片里物体的位置坐标,带着好奇的目的我开始了我YOLO源码的学习。
大家都知道YOLO训练所要求的数据格式是PASCAL VOC或者COCO等标准数据集格式,而我们通常对图片标注后产生的xml文件,我们要将其转化为txt格式,而Darknet为我们提供了转换文件为voc_label.py。现在我们开始学习该程序,为我们下一步获取训练集的数据集做准备。在此我将一句一句进行理解,做解析。
1 获取VOC2012数据集
首先获取VOC2012数据集,YOLO官网为我们提供了路径:
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar2 VOC2012数据集分析
VOC数据集包括训练集、测试集,包含20个种类。
数据集的组成架构分为:Annotations,ImageSets,JPEGImages,SegmentationClass,SegmentationObject五个文件夹,分别对5个文件夹进行解析。文件夹如图所示:
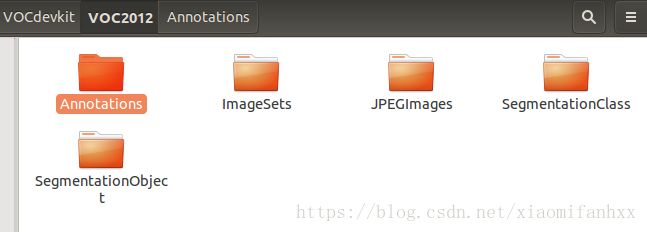
2.1 Annotations文件夹解析
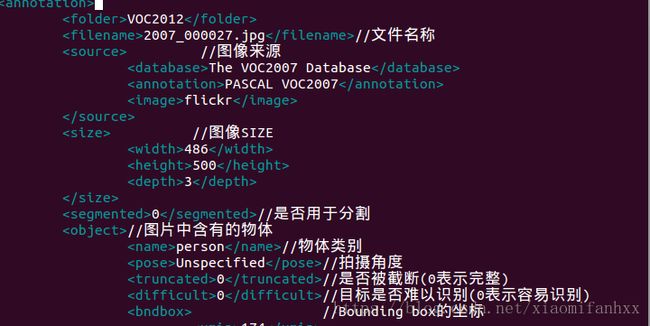
Annotations文件夹包含着所有图片信息的.xml信息,每个.xml文件代表着每一张图片。.xml文件的格式如图所示。后面讲述代码会分析.xml文件内容,读取.xml文件并将其转化为txt格式(YOLO可以使用的txt文档)
2.2 ImageSets
ImageSets下有4个文件夹,我将对这4个文件夹的内容进行解析。4个文件夹如图所示:

Action文件夹中是包含着人的的动作(如jumping,walking,riding等)
Layout文件夹中是包含着具体人的部位的数据(如人的head,feet等)
Main文件夹中是图像是图像识别的数据,总共分为20类
Segmentation文件夹中是可用于分割的数据
2.3 JPEGImages
JPEGImages就是存放着我们的所有数据集的图片.
2.4 SegmentationClass
这里面包含了2913张图片,图片的像素有20种,即代表了20个种类。
2.5 SegmentationObject
这里面包含了2913张图片,与SegmentationClass不同之处在于该是针对Object的,即一张图片中出现多个相同物体用不同的颜色来表示。
3 YOLO数据格式
前面博文已经讲述Darknet有专门的py文件来将.xml文件转为.txt文件。即voc_label.py文件,现在我要将该py文件进行解析。
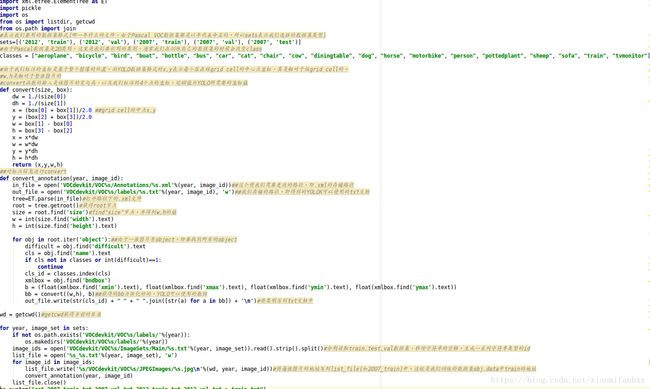
总结:通过voc_label.py文件我们将xml文件的数据转化为YOLO所要求的.txt文档,并且得到我们在训练时的obj.data中训练集,测试集的位置的txt,便于我们实验用,但有时候我们标注完产生的不是xml文件而是txt文件,我们怎么做,我遇到过这种问题,下篇博客我为大家讲述出现这种情况我们的代码解析,以及实际训练结果.
参考博客:https://blog.csdn.net/zhangjunbob/article/details/52769381