GPU 编程入门到精通(二)之 运行第一个程序
博主由于工作当中的需要,开始学习 GPU 上面的编程,主要涉及到的是基于 GPU 的深度学习方面的知识,鉴于之前没有接触过 GPU 编程,因此在这里特地学习一下 GPU 上面的编程。有志同道合的小伙伴,欢迎一起交流和学习,我的邮箱: [email protected] 。使用的是自己的老古董笔记本上面的 Geforce 103m 显卡,虽然显卡相对于现在主流的系列已经非常的弱,但是对于学习来说,还是可以用的。本系列博文也遵从由简单到复杂,记录自己学习的过程。
0. 目录
- GPU 编程入门到精通(一)之 CUDA 环境安装
- GPU 编程入门到精通(二)之 运行第一个程序
- GPU 编程入门到精通(三)之 第一个 GPU 程序
- GPU 编程入门到精通(四)之 GPU 程序优化
- GPU 编程入门到精通(五)之 GPU 程序优化进阶
1. CUDA 初始化函数
由于是使用 Runtime API, 所以在文件开头要加入 cuda_runtime.h 头文件。
初始化函数包括一下几个步骤:
1.1. 获取 CUDA 设备数
可以通过 cudaGetDeviceCount 函数获取 CUDA 的设备数,具体用法,如下所示:
// get the cuda device count
cudaGetDeviceCount(&count);
if (count == 0) {
fprintf(stderr, "There is no device.\n");
return false;
}
函数通过引用传递 count 值,获取当前支持的 CUDA 设备数。
1.2. 获取 CUDA 设备属性
可以通过 cudaGetDeviceProperties 函数获取 CUDA 设备的属性,具体用法,如下所示:
// find the device >= 1.X
int i;
for (i = 0; i < count; ++i) {
cudaDeviceProp prop;
if (cudaGetDeviceProperties(&prop, i) == cudaSuccess) {
if (prop.major >= 1) {
printDeviceProp(prop);
break;
}
}
}
// if can't find the device
if (i == count) {
fprintf(stderr, "There is no device supporting CUDA 1.x.\n");
return false;
}
函数通过引用传递 prop 关于属性的结构体,并且列出主设备号大于 1 的设备属性,其中设备属性通过函数 printDeviceProp 打印。打印函数如下所示:
// function printDeviceProp
void printDeviceProp(const cudaDeviceProp &prop)
{
printf("Device Name : %s.\n", prop.name);
printf("totalGlobalMem : %d.\n", prop.totalGlobalMem);
printf("sharedMemPerBlock : %d.\n", prop.sharedMemPerBlock);
printf("regsPerBlock : %d.\n", prop.regsPerBlock);
printf("warpSize : %d.\n", prop.warpSize);
printf("memPitch : %d.\n", prop.memPitch);
printf("maxThreadsPerBlock : %d.\n", prop.maxThreadsPerBlock);
printf("maxThreadsDim[0 - 2] : %d %d %d.\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2]);
printf("maxGridSize[0 - 2] : %d %d %d.\n", prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]);
printf("totalConstMem : %d.\n", prop.totalConstMem);
printf("major.minor : %d.%d.\n", prop.major, prop.minor);
printf("clockRate : %d.\n", prop.clockRate);
printf("textureAlignment : %d.\n", prop.textureAlignment);
printf("deviceOverlap : %d.\n", prop.deviceOverlap);
printf("multiProcessorCount : %d.\n", prop.multiProcessorCount);
}
1.3. 设置 CUDA 设备
通过函数 cudaSetDevice 就可以设置 CUDA 设备了,具体用法,如下所示:
// set cuda device
cudaSetDevice(i);
1.4. CUDA 初始化完整代码
/* *******************************************************************
##### File Name: first_cuda.cu
##### File Func: initial CUDA device and print device prop
##### Author: Caijinping
##### E-mail: [email protected]
##### Create Time: 2014-4-21
* ********************************************************************/
#include 2. Runtime API 函数解析
2.1. cudaGetDeviceCount
cudaGetDeviceCount
返回具有计算能力的设备的数量
函数原型:
cudaError_t cudaGetDeviceCount( int* count )
函数说明:
以 *count 形式返回可用于执行的计算能力大于等于 1.0 的设备数量。如果不存在此类设备,将返回 1
返回值:
cudaSuccess,注意,如果之前是异步启动,该函数可能返回错误码。
2.2. cudaGetDeviceProperties
cudaGetDeviceProperties
返回关于计算设备的信息
函数原型:
cudaError_t cudaGetDeviceProperties( struct cudaDeviceProp* prop,int dev )
函数说明:
以*prop形式返回设备dev的属性。
返回值:
cudaSuccess、cudaErrorInvalidDevice,注,如果之前是异步启动,该函数可能返回错误码。
另外 cudaDeviceProp 结构定义如下:
struct cudaDeviceProp {
char name [256];
size_t totalGlobalMem;
size_t sharedMemPerBlock;
int regsPerBlock;
int warpSize;
size_t memPitch;
int maxThreadsPerBlock;
int maxThreadsDim [3];
int maxGridSize [3];
size_t totalConstMem;
int major;
int minor;
int clockRate;
size_t textureAlignment;
int deviceOverlap;
int multiProcessorCount;
}
cudaDeviceProp 结构中的各个变量意义如下:
name
用于标识设备的ASCII字符串;
totalGlobalMem
设备上可用的全局存储器的总量,以字节为单位;
sharedMemPerBlock
线程块可以使用的共享存储器的最大值,以字节为单位;多处理器上的所有线程块可以同时共享这些存储器;
regsPerBlock
线程块可以使用的32位寄存器的最大值;多处理器上的所有线程块可以同时共享这些寄存器;
warpSize
按线程计算的warp块大小;
memPitch
允许通过cudaMallocPitch()为包含存储器区域的存储器复制函数分配的最大间距(pitch),以字节为单位;
maxThreadsPerBlock
每个块中的最大线程数
maxThreadsDim[3]
块各个维度的最大值:
maxGridSize[3]
网格各个维度的最大值;
totalConstMem
设备上可用的不变存储器总量,以字节为单位;
major,minor
定义设备计算能力的主要修订号和次要修订号;
clockRate
以千赫为单位的时钟频率;
textureAlignment
对齐要求;与textureAlignment字节对齐的纹理基址无需对纹理取样应用偏移;
deviceOverlap
如果设备可在主机和设备之间并发复制存储器,同时又能执行内核,则此值为 1;否则此值为 0;
multiProcessorCount
设备上多处理器的数量。
2.3. cudaGetDeviceCount
cudaSetDevice
设置设备以供GPU执行使用
函数原型:
cudaError_t cudaSetDevice(int dev)
函数说明:
将dev记录为活动主线程将执行设备码的设备。
返回值:
cudaSuccess、cudaErrorInvalidDevice,注,如果之前是异步启动,该函数可能返回错误码。
3. nvcc 编译代码
nvcc 是 CUDA 的编译工具,它可以将 .cu 文件解析出在 GPU 和 host 上执行的部分,也就是说,它会帮忙把 GPU 上执行和主机上执行的代码区分开来,不许要我们手动去做了。在 GPU 执行的部分会通过 NVIDIA 提供的 编译器编译成中介码,主机执行的部分则调用 gcc 编译。
通过如下命令,可以编译之前写的 first_cuda.cu 程序:
nvcc -o first_cuda first_cuda.cu
通过上述编译,生成可执行文件 first_cuda
运行结果如下所示:
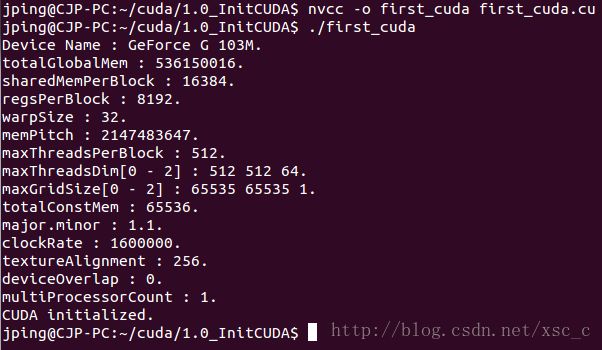
这一篇博文介绍了如何通过 runtime API 建立自己的第一个 CUDA 程序。通过这个程序,可以学会使用 CUDA 的一般流程。下一部分,将介绍 CUDA 如何进行 GPU 编程。
欢迎大家和我一起讨论和学习 GPU 编程。
[email protected]
http://blog.csdn.net/xsc_c