数据库的并发一致性问题
声明:本文内容基本从https://github.com/CyC2018/Interview-Notebook这个GitHub上整理而来。
1.修改丢失问题
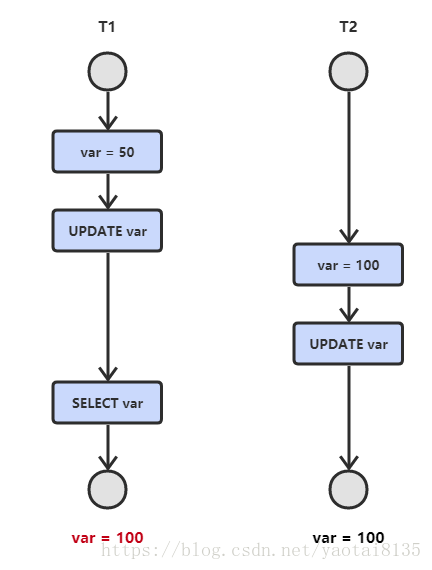
2.读脏数据
T1修改了数据,但随后T1撤销了修改,T2读的是脏数据。
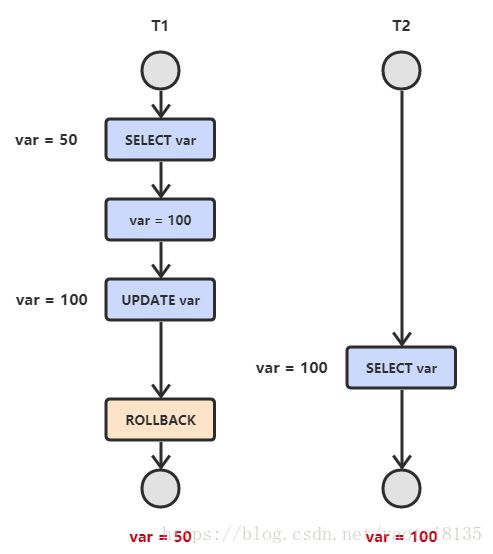
3.不可重复读
T2 读取一个数据,T1 对该数据做了修改。如果 T2 再次读取这个数据,此时读取的结果和和第一次读取的结果不同。
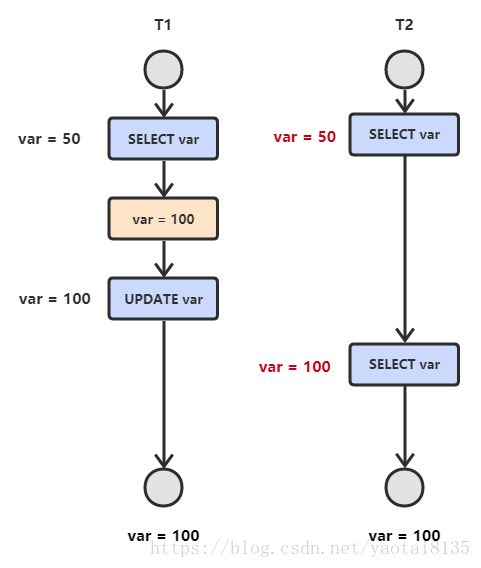
4.幻影读
T1 读取某个范围的数据,T2 在这个范围内插入新的数据,T1 再次读取这个范围的数据,此时读取的结果和和第一次读取的结果不同。
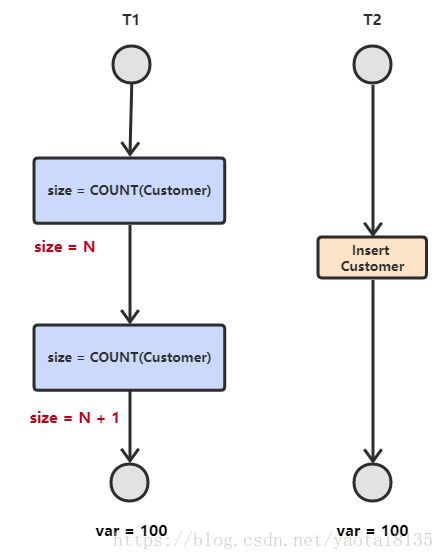
上述四种问题的特点:
丢失修改:T1,T2都进行修改提交
读脏数据:T1先修改 T2随后读取 ,T1再修改。
不可重复度:T2读 T1修改 T2再读
幻影读:T1读 T2修改 T1再读
这里,似乎不可重复读和幻影读是一致的,那么它们的区别是什么呢?
从控制的角度来讲,不可重复读只需要锁住满足条件的记录,而幻影读要锁住满足条件的及其相近的记录。所以,避免幻读,必须锁住表,避免不可重复读,只需要锁住行。
不可重复读和幻读最大的区别在于,如何通过锁的机制来解决它们产生的问题。
可以采用悲观锁的机制来处理问题,悲观锁大多数情况下依靠数据库的锁机制实现,以保证操作最大程度的独占性。但随之而来的就是数据库性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。所以出于性能的考虑,成熟的数据库使用了以乐观锁为理论基础的MVCC(多版本并发控制)来避免上述两种问题。
乐观锁,大多是基于数据版本记录机制实现的。
1.SELECT : 当开始新一个事务时,该事务的版本号肯定会大于当前所有数据行快照的创建版本号。
2.INSERT : 将当前系统版本号作为数据行快照的创建版本号。
3.DELETE : 将当前系统版本号作为数据行快照的删除版本号。
4.UPDATE : 可以理解为先执行 DELETE 后执行 INSERT。
上述四种问题产生的原因主要是并发不一致的问题导致破坏了事物四大特性——原子性,隔离性,一致性,持久性之一的隔离性。如果不采取措施的话,那么在并发的环境中,一个事物所做的修改再最终提交前,其他事物对其也是可见的,并且是可修改的。
我们采用并发控制的技术,让事物的执行结果和某一个串行执行的结果相同,就认为事物满足隔离性要求。
一个直观的想法是用户获取对并发控制的所有权力,封锁操作需要用户自己控制,相当复杂。数据库管理系统提供了事物的隔离级别,让用户以一种更轻松的方式处理并发一致性问题。比如MySQL提供了行级锁和表级锁。但是,加锁的行为不可避免的会带来开销,所以需要在所开销和并发程度上做出权衡。
针对上述4种问题,有以下几种封锁类型:
排它锁:对数据对象 A 加了 排它锁,就可以对 A 进行读取和更新。加锁期间其它事务不能对 A 加任何锁。
共享锁:对数据对象 A 加了 共享锁,可以对 A 进行读取操作,但是不能进行更新操作。加锁期间其它事务能对 A 加 共享锁,但是不能加 排它锁。
三级封锁协议
一级封锁协议:解决修改丢失问题

二级封锁协议
在一级的基础上,要求读取数据 A 时必须加 S 锁,读取完马上释放 S 锁。
可以解决读脏数据问题,因为如果一个事务在对数据 A 进行修改,根据 1 级封锁协议,会加 X 锁,那么就不能再加 S 锁了,也就是不会读入数据。

三级封锁协议
在二级的基础上,要求读取数据 A 时必须加 S 锁,直到事务结束了才能释放 S 锁。
可以解决不可重复读的问题,因为读 A 时,其它事务不能对 A 加 X 锁,从而避免了在读的期间数据发生改变。
