Tesseract OCR论文笔记及使用说明
1.Tesseract介绍
Tesseract是惠普布里斯托实验室在1985到1995年间开发的一一个开源的OCR引擎,曾经在1995 UNLV精确度测试中名列前茅。但1996年后基本停止了开发。2005年,惠普将其对外开源,2006 由Google对Tesseract进行改进、消除Bug、优化工作。目前项目地址为: https://github.com/tesseract-ocr/tesseract。
它与Leptonica图片处理库结合,可以读取各种格式的图像并将它们转化成超过60种语言的文本,我们还可以不断训练自己的库,使图像转换文本的能力不断增强。
Tesseract 4增加了LSTM,主要用来进行线识别,下面有说到文本线。
总的来说Tesseract 是基于字符方面的识别,尤其是多边形近似法,识别步骤是step by step的。
下面内容基本是Ray Smith《An Overview of the Tesseract OCR Engine》翻译总结的。
1.1 Tesseract结构
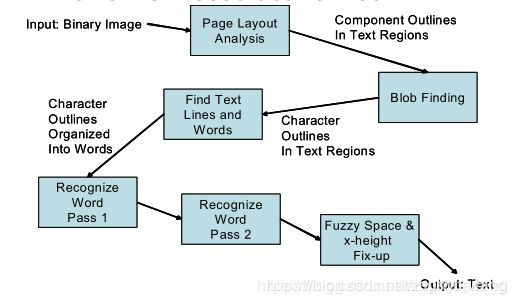
1.连通区域分析,检测出字符区域区域(轮廓外形),以及子轮廓。在此阶段轮廓线集成为块区域。
2.由字符轮廓和块区域得出文本线(text lines)。有两种分析文本线的方法,一种是固定场景,一种是按比例场景。固定场景通过字符单元分割出单个字符,而按比例场景(Proportional text)通过清楚的空格和模糊间隔(fuzzy spaces)来分割。
(1)下图是固定场景,单词间隔固定。
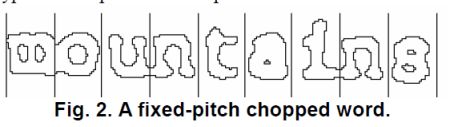
(2)下面非固定场景,或者说按比例场景。靠空格区分。但是空格的宽度又不太相同,所以引入的模糊间隔的的场景,针对模糊间隔会在文字识别后再进一步处理。
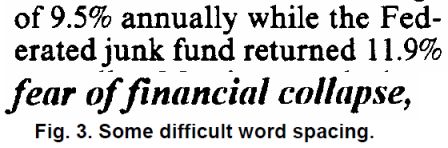
3.依次对每个单词进行分析,采用自适应分类器,分类器有学习能力,先分析且满足条件的单词也作为训练样本,所以后面的字符( 比如页尾)识别更准确:此时,页首的字符识别比较不准确,所以tesseract会再次对识别不太好的字符识别是其精度得到提高。故这个地方有两次处理。
4.最后,解决含糊不清的空格,和检查x-height,定位(small-cap)的文本,大小写处理。
1.2 文本线和文字定位
主要是基于已经进行了页面分析,基本知道了哪部分是文字区域,然后对这些blob处理,生成文本线。基本线采用了平方样条方法,也许采用立方样条方法更好。

如上图,包括基本线、下降线、平均线、上升线,他们都是平行的,带有稍微的弯曲。上升线是上图青色的线。
1.3 文字识别
本部分主要是描述在非固定宽度的文本识别。
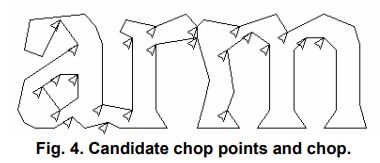
1.3.1分割连接的字符
当从一个完整的单词识别出来的结果不太满意时,tesseract通过字符级别的分割blob来改善结果。多边形轮廓的一些凹的顶点是作为候选的分割点,以及相反方向的凹点或者线段。这3部分可以成功的分割连接的字符。
如下图所示,箭头代表了一系列分割的点。在r与m字母间的分割是线段。
1.3.2联合破碎的字符
当潜在的分割点已用完,还是不能满足要求,文字识别不好时,就用到了联合器(associator)。Associator会尝试最优先搜索,把分割的blob最大可能的联合成候选字符。
Fully-chop-then-associate 方法也许不是有效的,可能丢失重要的分割片段。但是chop-then-associate 可以简化数据结构,可以保持完整的分割图谱。
下面的单词就可以用此方法简单的识别出来。
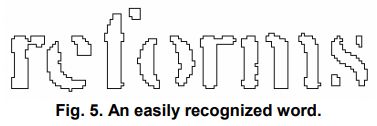
1.4 静态字符分类
1.4.1 特征
不是使用拓扑形的特征,而是使用多边形近似法。这种方法对于损坏的字符也不是健壮的。
不过找到一个好的解决方法,就是未知的特征不需要和训练的特征保持一样。
如下图,短粗线表示未知的特征,他们是小的,固定长度的特征;细长线表示多边形近似的聚合片段。用小的特征去匹配大的原型是容易进行损坏图片的识别。只是需要大量的计算。
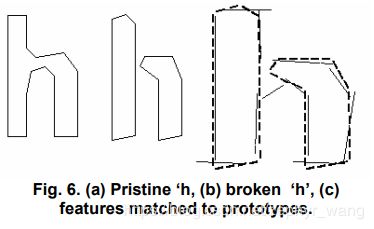
1.4.2 分类
分类处理包含两步。第一步是,创建未识别部分的字符分类最终候选集。第二步就是计算上一步的候选集和原型的最好结合距离。
1.5 语音学分析
Tesseract有少许语言学分析,比如采用经常出现的单词等等。
每一个字符分类会生成两个数字,一个数字是负的标准化距离,该值越大代表越好;另一个值是rating,等于原型的标准距离乘以未知字符的整个轮廓长度。
1.6 适配性分类
因为静态分类擅长于对任何字体的一般化处理,但对于字符与非字符是区别对待的。
静态分类和适配性分类的区别是,适配性分类采用各向同性的baseline/x-height 标准化处理,而静态分类采用形心式标准化处理。
baseline/x-height方法容易识别大小写字符。
下图是两种方法的展示。

1.7 总结
Tesseract的特点是它特征的不同寻常的处理方式。他的缺点也正是多边形近似法的使用,而不是粗略的轮廓。
2.下载安装
下载安装文件
Windows可以直接下载exe文件,安装就行。
下载地址:https://tesseract-ocr.github.io/tessdoc/Home.html
下载字库
比如中文字库地址:
https://raw.githubusercontent.com/tesseract-ocr/tessdata/master/chi_sim.traineddata
3.配置环境变量
Path 环境变量
在“我的电脑”右键,选择“属性-高级系统设置-环境变量”,在path中添加环境变量,如下。

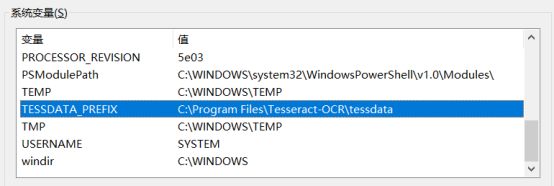
TESSDATA_PREFIX环境变录
错误:
Please make sure the TESSDATA_PREFIX environment variable is set to your “tessdata” directory.

解决办法,继续添加环境变量TESSDATA_PREFIX如下:
4.运行测试
命令格式:tesseract imagename outputbase [-l lang] [–oem ocrenginemode] [–psm pagesegmode] [configfiles…]
示例:tesseract t1.jpg result.txt -l chi_sim+eng
参数说明:
chi_sim:表示中文语言包
eng:表示英文语言包。
–psm NUM Specify page segmentation mode.
–oem NUM Specify OCR Engine mode.
NOTE: These options must occur before any configfile.
Page segmentation modes:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
OCR Engine modes:
0 Legacy engine only.
1 Neural nets LSTM engine only.
2 Legacy + LSTM engines.
3 Default, based on what is available.


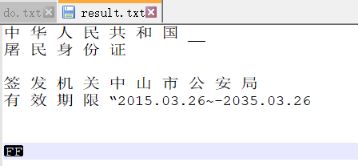
总结,效果还凑合吧,速度也快。不够感觉精度还是不够准确。尤其是背景复杂的图片。