KDD 2017 参会报告
本次参会报告由技术发展部黑屏;阿里云飞天一部杰铭、布晓、吴双;阿里妈妈产品技术部永叔、怀人;集团安全部裕宏等同学一起撰写。希望大家积极交流,踊跃发表看法。
一 背景:(杰铭)
KDD的全称是ACM SIGKDD Conference on Knowledge Discovery and Data Mining。SIGKDD是ACM在数据挖掘领域的顶级学术会议,每年都吸引着超过2000位来自世界各地的顶级数据挖掘学者,以及知名企业代表前来参加。然而,大会的论文接收每年却仅约200篇,接收率不超过15%。
今年的KDD大会刚刚于加拿大新斯科舍省的首府哈利法克斯(Halifax)落下帷幕。哈利法克斯是位于加拿大东部大西洋畔的一个城市,市区人口414400(2014年)。这已经可以算是近些年来大型会议举办城市中规模最小的了。据KDD会议主席介绍,之所以选择哈利法克斯来举办有一个原因是“一直锲而不舍的申请”。所以这次大会对于这个小城市来说是一件大事情。市长不仅亲自来站台,并且还发表了一段热情洋溢的讲话。本次大会比较有特点的地方是主会场在冰球体育馆内。尽管该城市已经是倾囊而出了,然而这么个小城市一下子涌进了这么多的参会人员,整个城市从旅馆到飞机的压力就严重超出负荷了。导致有的同学路上耽误了两天。
二 概述:(杰铭)
有来自51个国家的1656人注册了会议,是美国之外人数最多的一次。

注册人来源占比图
考虑到美、加两国也有大量华人注册,所以和其他AI会议一样,华人研究学者一直都是主角。本次会议有创记录的总共1143篇投稿,其中研究型747篇,64篇oral(8.6%)和66篇poster(8.8%)。应用数据科学类390篇投稿,36篇oral (9.2%)和50篇poster(12.8%)。
三 会议交流 (黑屏)
会议中阿里的站台是最受关注的展台之一,很多著名学者来交流。大家对机器学习算法在阿里的实际应用很感兴趣,反映了KDD对算法在工业应用中的偏好。
KDD 2017大会主席Shipeng Yu在阿里展台 (右二),左一为微软的郑宇
KDD 2017大会主席Stan Matwin在阿里展台
杨强教授在阿里展台
下届KDD会议主席林智仁教授、熊辉教授在阿里展台
除了上述学者,伯克利大学的郁彬教授、今日头条的李磊博士等也和我们进行了深入的交流。
四 有监督学习(杰铭)
- AnnexML: Approximate nearest neighbor search for extreme multi-label classification
背景:极多标签分类最近受到了很大的关注。
比如一个例子是通过使用最相关的维基百科类的子集,用极多标签分类器学习来标记新的维基百科文章(图一)。另一个例子是考虑到用户的网页浏览历史和搜索关键字,构建一个分类器给网络用户显示在线广告。这两个例子都出现了优化极多标签分类器的需求。在这些案例中,标签数量从万到百万不等。第一个例子如下图所示:
训练过程如下:
- 每一个点代表一个训练样本。具有相似标签向量的样本被连接起来组成下面的向量图
- 训练中学习出的超平面被分成K个子图,并且让这个结构尽可能的多
- 特征空间经过学习被分成不同的子空间并且在嵌入式的子空间中更接近地分配连接样本

预测过程如下:
1.使用训练得到的超平面,决定测试样本属于哪一个区间
2.使用矩阵把测试点置于嵌入空间
3.这样就能得到嵌入空间中的K最近相邻点
4.经验上的K最近相邻分布的结果可以因此得到为:

对于精确预测:
1)用近似KNN(KNNG)作为弱分类方式来学习区域数据点
2)学习嵌入空间时,把这个问题转化为排序问题
对于快速预测:
通过高效的在嵌入空间中穿越学到的KNNG来使用一个近似KNN搜索技术
从而得到下面图示的嵌入空间
下图显示了实验结果:
该论文有效地利用近似最近邻搜索方法有效地探索嵌入空间中学习的KNN邻图。通过对几个大规模的真实世界数据集进行了评估,并将提供的方法与最近的最新方法进行了比较。论文提供的实验结果表明, Annexml可以显著提高预测精度,特别是在有较大的标签空间数据集。此外,Annexml提高了预测的时间和精度之间的权衡。在同级别的精确度,Annexml预测的时间比著名的SLEEC速度高达58次。
- Similarity Forests
随机森林由于其非凡的精度和有效性成为被经常使用的最成功的方法之一。然而它的使用主要局限于多维数据集。在本文中,作者提出了一个扩展的随机森林方法突破这个局限。只需要计算数据对象之间的相似性,此外,在计算复杂性上,也从 降低到 的一部分。
本论文主要的贡献在于:
- 设计了一种利用相似值来计算而不是多维特征计算的随机森林的方法
- 相似值的计算复杂度大概是
- 可以用于缺失值和有噪音的数据集
- 可以被应用于当全维度的表示是可能的时候:提供一个有竞争力的或者较传统的随机森林方法有轻微表现优势的方法
SimForest 算法细节为:
训练:利用已经取样的点的对构建森林的每一棵树并且利用相似值进行拆分:当每一个叶子节点有100%准确度的情况下构建树
测试:对于每一个测试样例,仅仅使用测试点和训练点之间的相似值来遍历树:预测叶子节点的显著属性。
相似值的计算公式为:
经过简化以后成为:
下面两张表显示了SimForest 和SVM 在两种情况下的对比,显示出SimForest的性能优势。
固定噪音系数下的准确率(α=2.5)
15% 的相似值丢失的情况下的准确率
五 推荐部分(永叔)
- Unsupervised P2P Rental Recommendations via Integer Programming
这篇来自于密苏里科技大学的文章针对如Airbnb、FlipKey以及HomeAway等P2P应用系统中的推荐问题做了很有意思的研究,游客在外旅游很重要的事情便是住和行,而这类item的推荐很难用有监督学习基于大量数据来训练,这与我们之前参与飞猪旅行相关推荐问题的研究类似。选择住处每个人都有不同的喜好,但对于房间的选择条件确是我们可以抽象出来的,Yanjie Fu这里提出了一种基于整数规划的推荐系统,他将风险和收益都集中在一个目标函数中进行评估。民宿与酒店不同,你很难将其标准化进行评估,同时有很多信息是比较难获取的;游客在这种状况下除了要关心住处的各项舒适指标,还要特别关注社区的安全问题,毕竟人身安全也很重要。整数规划是众所周知的难解问题,最常用的方法便是分支定界,而穷尽搜索的方法效率地下,这篇文章提出了learning to BB的思路,即引入分支选择变量去模拟学习分支定界的算法行为,这显著改善了算法性能。作者的实验是在纽约市做的,结果是性能和效果上都达到了还不错的效果。
住宿选择有利/有风险的feature集合
问题的抽象定义:
- Meta-Graph Based Recommendation Fusion over Heterogeneous Information Networks
这篇文章来自于香港科技大学,主要介绍了meta-graph在异构信息网络推荐中的应用研究。HIN异构信息网络对于淘宝的电商推荐建模非常有用,用户和商品是典型的两部图,而它们之间会发生多种类型的关联,如点击、收藏、加购、购买、评论、退货以及推荐等等。基于HIN的推荐主要面临两类问题,首先是如何表达推荐的高层语义信息,其次是如何融合异构的信息来进行item推荐。作者分别通过引入meta-graph概念以及采用MF(矩阵分解)+FM(因子分解机)方法尝试解决了这两个问题,文中在亚马逊(类淘宝)和Yelp(类点评)两个数据集上做了实验,与传统的异构信息网络算法及FM算法做了比较,作者新提出的思路明显优于当前水平。我觉得这篇文章的工作还是比较接地气的,没有非常花哨的变形和复杂的模型,针对当前企业级推荐的复杂性和局限性进行了卓有成效的研究工作。
上图是文中异构网络的例子及基于meta-graph训练user-item隐空间向量的定义。
- Recurrent Poisson Factorization for Temporal Recommendation
这篇文章来自伊朗德黑兰的Sharif University of Technology,用到的因子分解机方法变种我之前并不熟悉,即泊松分解。文章中对于研究这个问题的动机描述很打动我,用户在淘宝上逛推荐场景时,有的人喜欢商品找相似,有的人喜欢寻找新奇特,重口难调,而只是基于统计众数的行为日志做协同过滤会导致长尾用户或者长尾需求很难得到满足;但如果我们基于规则脚本又很难穷举出用户的兴趣偏好,特别是这些偏好还是随着时间变化的。这篇文章提出的再生泊松分解算法比较系统的将时间类因素引入到泊松分解算法中去,为我们解决推荐系统目前面临的长尾优化问题提供了一条很值得尝试的思路,文中实验部分不算非常solid,这点我们可以在这个基础上做进一步的研究。下图是RPF再生泊松分解算法的图示:
- Bridging Collaborative Filtering and Semi-Supervised Learning: A Neural Approach for POI Recommendation
这篇文章来自于KDD经典paper大户—UIUC的Han Jiawei老师实验室,论文中的方法和实验都比较solid,主要尝试用神经网络模型来结合协同过滤与半监督学习,然后进行POI(兴趣点)的推荐。文章中的思路不算特别新颖,对数据问题的建模属于今年Deep Learning for Recommendation的标准配置。下图是文中设计的NN网络结构
Embedding-based News Recommendation for Millions of Users
这篇文章来自于Yahoo日本,主要介绍了日本首页上的新闻推荐,比较标准的基于DL的一个工作,新意不多,因此大会也并没有将这篇文章选入做oral presentation。文中分为三个主要步骤,首先基于一个去噪自动编码器生成新闻的分布式表达;然后以用户浏览历史作为输入基于RNN模型生成用户表达;最后用user-item内积排序做top-k推荐。作者在Yahoo日本首页上线实验了他们的算法,ctr有10%-23%的提升,我们在手淘首页猜你喜欢的视频瀑布流推荐中也尝试了类似的方法,ctr有20%的提升,这是在item本身属性挖掘比较困难的前提下一种折中方法,整体效果还是不错的。
- Dynamic Attention Deep Model for Article Recommendation by Learning Human Editors’ Demonstration
这篇文章来自于上海交通大学,值得注意的是来自UCL的Weinan Zhang,今年UCL的Jun Wang老师实验室在推荐、IR领域非常活跃。文中提到的motivation对电商推荐还是很有启发的,传统的新闻门户网站选择上头版的模式都是编辑选稿,而这样的方式是劳力密集型,算法冲进去试图去捕获编辑的选稿过程,进而可以把这个工作自动化掉,还能做到supervised,挺有意思的工作。手淘的产品一直在提社会化选品、达人选品其实就是这个路子,人的大脑判断并不是只基于一些热点词汇或者图片展示等浅层特征,而attention model可以在一定程度上刻画选品感觉这个东西,这篇适合做推荐的同学泛读。
- Online Ranking with Constraints: A Primal-Dual Algorithm and Applications to Web Traffic-Shaping
这篇文章来自于Yahoo研究院,本着他们出品必出精品的原则拜读了一下,企业研究院搞的问题就是接地气,文章中着手解决的问题对于处理推荐流量上非商品item、广告以及自然流量item之间的关系非常有用,其提出的指标矩阵体系也很实用。下面是几张现场拍的问题分析ppt部分截图,感性的同学可以去详细读下文章。
六 表征学习(裕宏)
表征学习旨在自动抽取特征,用以取代(专家)特征工程所花费的时间。带着强大的自动特征抽取的能力,表征学习在传统机器学习一直无法突破的领域,取得了非常惊人的优异表现。今年KDD的表征学习会场总共包含了5篇文章。除了第一篇“EmbedJoin: Efficient Edit Similarity Joins via Embeddings”是采用数据库的思路对高维数据进行embedding外,其余四篇paper都跟神经网络相关。最近representation learning, embedding方面的文章非常多,大有“全民embedding, everything to vector“之势。
- EmbedJoin: Efficient Edit Similarity Joins via Embeddings
Edit similarity join是数据库系统的一个主要操作,在数据清理\集成,生物信息学,协同过滤,自然语言处理等领域有着广泛的应用。Edit distance中文又叫编辑距离,i.e., ED(x,y)指将字符串x转为字符串y所需的最少编辑次数,常见的编辑方式有插入、删除、替换。给定一堆字符串,一个阈值K, edit similarity join将会返回所有edit distance小于K的字符串组合。例如,给定字符串ACCAT,CCAAT,GCCCT,CACGA,AACGG, 假设K=2,edit similarity join将会返回(ACCAT,CCAAT),(ACCAT,GCCCT),(CACGA,AACGG)。
跟常见的距离度量方式,e.g., Hamming distance、 Cosine、Jaccard,Edit distance可以很好的保留待比字符串中字符的顺序。这些在某些特定的应用场景下至关重要。然而,Hamming distance、 Cosine、Jaccard等距离度量方法只需要O(n)进行计算,edit distance需要O(n^2)的时间复杂度,n为待比字符串的长度。
针对这个问题,当前已有大量的优化算法被提出。但目前所有的技术方案均不能很好地解决较长待比字符串的大阈值问题。在实际使用场景中,较长的字符串往往需要使用较大的阈值才能够找到合适的匹配。根据最新的文献报告,当K=0.25*n,目前的技术都会有性能的瓶颈。
针对上述问题,这篇文章提出了名为“EmbedJoin”的解决方案。与目前大部分的优化算法直接计算原始字符串的edit distance不一样,EmbedJoin包含两步: i), 将待比字符串从Edit space映射到Hamming space,映射的方法已被证明能够提供距离的bound;ii),利用hamming space上LSH对字符串进行过滤。
EmbedJoin使用到的主要技术包括以下两个(感兴趣的同学可以具体去看paper)
a).CGK embedding
b).LSH for hamming distance (bit sampling)
EmbedJoin的效果:
i). 牺牲一点召回, e.g., 95%-99% recall, 100% precision,大幅降低response time和memory usage
ii).能够handle大阈值的edit similarity join, e.g., 20% * n
- Collaboratively Improving Topic Discovery and Word Embedding by Coordinating Global and Local Contexts
一个文本语料库一般都包含两部分的信息:全局上下文(global context)和局部上下文(local context)。
i). 全局上下文: 主要指的是文档级别的共现信息,一般可用于对文档进行topic modeling。常见的topic models算法,例如LDA和PLSA,都是基于“each document is composed of a mixture of latent topics, each of which is a multinomial distribution over words”的假设。
ii).局部上下文: 主要指的是词级别上下文信息,包含了词的semantic和syntactic信息,一般可用于对词进行embedding。常见的word embedding models,例如NPLM和Skip-Gram都采用了以下假设, i.e., ”words occurring in similar local contents tend to have similar semantic and syntactic properties”。
其中全局上下文用document-word矩阵描述,矩阵上下文用word co-occurrence矩阵刻画。
两种类型的信息互为补充,可协同使用。
基于上述想法,作者提出了一个统一语言模型。该语言模型采用了以下三个假设:
i). Global: 每篇文档集中在很一小部分的topics,每个topics包含一小部分概率较高的词。
ii).Local: 经常出现在一起的词趋于用于同样的syntactic和semantic特性,因此在embedding空间里面应该离得比较近。![]()
iii). Collaboration: 在embedding space里面离得比较近的词趋于拥有同样的topic distribution, 反之亦然。 ![]()
最后使用协同矩阵分解来discover topic structures和learn word embedding。
联合embedding的效果: topic coherence,document classification, word similarity, word analogy等任务上都比现有的方法有所提高。
- Metapath2vec: Scalable Representation Learning for Heterogeneous Networks
Network embedding已被广泛研究,与deepwalk,node2vec有所不同,
来自微软与其他机构合作的这篇文章主要研究异构网络的embedding。
异构网络的embedding主要有以下三点挑战:
基于这些挑战,作者给出的solution是: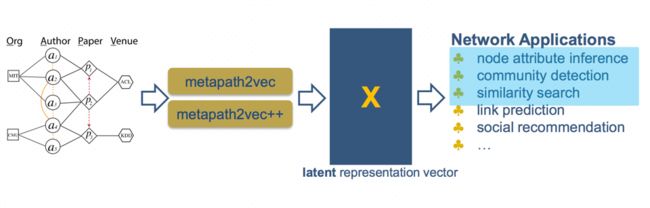
其中mmetapath2vec与metapath2vec++都是采用了meta-path-based random walks.与一般的random walk不同的地方在于每一walk都会依旧现有的scheme有bias. Metapath2vec与metapath2vec++在于embedding使用的模型。Metapath2vec采用skip-gram, 而metapath2vec++采用的是heterogeneous skip-gram。两者的主要区别在于计算softmax的过程中是否考虑node type。
Deepwalk/node2vec,PTE,metapath2vec,metapath2vec++得到的node embedding的可视化展示:

- Struc2vec: Learning Node Representations from Structural Identity
Deep walk,node2vec以及刚才介绍的metapath2vec都是利用一个node的context information对一个node进行embedding。这些方法在分类与预测任务上取得了不错的表现。然而这种就node context information进行embedding的方法也有不足之处。例如,下图中的u和v在结构上非常相似,但是由于两者之间离得非常远,没有任何share的node,之前的embedding方式并不能捕捉到他们之间结构上的相似性。

这篇文章提出了一个较为灵活的框架,i.e., struc2vec,对图中的节点进行embedding,以期能够捕捉node在结构上的相似度。
Struc2Vec主要包含以下三步:
i). 衡量node之间的structural similarity
ii). 基于node的structural similarity,构建context graph
iii).产生每个node的context
iv). Node embedding
struc2vec在barbell graph上的效果展示:
七 Workshop-AdKDD&TargetAD (怀人)
这是两个computational advertising领域的workshop,KDD2017两者合在一起召开。其中TargetAD较新,今年是第3期;AdKDD则相对历史悠久,从2007年至今已经举办过10期。很多ad领域的经典工作,如2013年Facebook的GBDT+LR,今年Google的Deep & Cross Network,均是发表在AdKdd上的,总体来说,这个workshop能够较好地反映这个行业的巨头们在ad方向上的关注和研发重点,发表的工作实用性很强。在KDD2017的现场,这个workshop几乎是我见到的最火爆的一个,不仅座无虚席,几乎能落脚的地方都有人席地而坐;下午的talk我来晚了点,只能站在门口听完,工业界topic的影响力和人气可见一斑。
- AdKDD&TargetAD 2017的outline
这是一个full day的workshop,分为两类talk,穿插进行。
1)invited talk
今年邀请了四位大牛,Amazon的Alex Smola,Cornell 的Thorsten Joachims,Netflix的Randall Lewis,Stanford的Susan Athey, 阵容还是蛮强大的。前两位大家应该更为熟悉一些,他们的talk集中在更好地针对工业数据进行建模,后两位集中讨论了广告的效果归因,采用的方法是Causal Inference,这是今年KDD上一个讨论和关注得较多的一个流派。
slides的地址见:https://adkdd17.wixsite.com/adkddtargetad2017/copy-of-alex-smola。不过还有两位迟迟没有提交,感兴趣的同学只能自己发信去索要了。
2)accepted paper report
一共12篇工作被接收,且全部进行了oral宣讲。今年比较好的是,全部的slides都公布在网站上了,地址:https://adkdd17.wixsite.com/adkddtargetad2017/accepted-papers。
- 重点方向一览
1)市场保留价
本次workshop有两篇相关的工作,分别来自linkedin和yahoo,带着非常浓厚的工业风。其中yahoo这篇工作的所有作者均加入了阿里,感兴趣的同学可以直接找作者们交流细节。
相关论文如下:
Data-Driven Reserve Prices for Social Advertising Auctions at LinkedIn,来自LinkedIn
Optimal Reserve Price for Online Ads Trading Based on Inventory Identification,来自Yahoo
2)预估模型
这是成熟的ad公司关注和研究的焦点。本次workshop中有四篇相关的工作,其中google的DCN(deep & cross network)我做了重点跟踪,是对google wide&deep learning工作的后续拓展,延续了google ads一贯的对人工交叉特征的坚持作风,巧妙地通过多层神经网络构造了多项式阶交叉特征,感兴趣的同学可以读一读。
相关论文如下:
Deep & Cross Network for Ad Click Predictions,来自Google
An Ensemble-based Approach to Click-Through Rate Prediction for Promoted Listings,来自Etsy,作者之一是微博上比较火的技术网红洪亮劼。
A Practical Framework of Conversion Rate Prediction for Online Display Advertising,来自Yahoo&Alibaba
Ranking and Calibrating Click-Attributed Purchases in Performance Display Advertising,来自A9.com
3)市场度量和优化机制。
这方面的工作比较杂,来自多家公司,从中也可以看到ad这个领域不同的角色其关注和优化角度百家争鸣。
相关论文如下:
Blacklisting the Blacklist in Digital Advertising,来自Dstillery
MM2RTB: Bringing Multimedia Metrics to Real-Time Bidding,来自National University of Singapore,这是唯一一篇纯学术界的工作
Profit Maximization for Online Advertising Demand-Side Platforms,来自adobe&yahoo
Anti-Ad Blocking Strategy: Measuring its True Impact,来自adobe
Cost-sensitive Learning for Utility Optimization in Online Advertising Auctions,来自facebook,Criteo和google。
Attribution Modeling Increases Efficiency of Bidding in Display Advertising,来自Criteo
八KDD cup
- 背景:
关于智慧交通领域的经验积累,阿里云早在2015年已经开始有所沉淀。浙江省交通运输厅于15年4月公布了一项新的试点项目,将高速公路历史数据、实时数据与路网状况结合,基于阿里云大数据平台,预测未来一小时内的路况。结果是,实时路况监测成本下降了 90%,未来路况预测准确率在 91%以上。
2016年9 月,在云栖大会上发布的“杭州城市大脑”的交通模块在萧山区市心路投入使用,其首要目的是解决城市发展中的交通问题。试验数据显示:通过智能调节红绿灯,道路车辆通行速度平均提升了 3% 至 5%,在部分路段有 11% 的提升。正如发布时王坚博士所言:世界上最远的距离是红绿灯与交通监控摄像头之间的距离,他们虽然在同一根杆子上,但是从来没有通过数据被连接过。因此,打通数据并在海量、实时数据分析处理的基础上做出智能决策,是城市大脑的基本定位。

- 赛题:
基于以上阿里云在城市大脑、智慧交通中的丰富积累,在今年的KDD CUP赛题设置中,阿里云选择了交通领域中高速公路收费站相关问题作为任务:
Task 1: To estimate the average travel timefrom designated intersections to tollgates(预测车辆从路口到收费站的平均用时)
Task 2: To predict average tollgate trafficvolume(高速收费站车流量预测)
这两个任务是基于智慧交通信号灯,其逻辑如下:

根据以上步骤,预测效果如下:

- 赛况
当中国拥堵问题出现在国际顶赛中,吸引了全世界的数据算法专家纷纷来参赛。据悉,本次KDD CUP一共有3582支队伍参赛,覆盖全球48个国家,731座高校,参赛队伍有来自微软、因特尔等知名互联网企业,也有来自清华大学、波士顿大学等高等学府。对此KDD CUP Chair表示不可思议,这是KDD CUP史上规模最大的比赛,他表示这次的比赛很成功,来自世界各地的选手能够通过这次的比赛了解中国的交通问题,整个比赛running的很顺利,同时也感谢阿里云天池平台的平台支持。

在KDD CUP公布获奖名单时,让人意外的是,本届大会获奖名单被中国选手包圆,更有一个名为Convolution的团队取得双料冠军。在现场采访到为什么可以取得如此成绩的时候,其队长表示团队成员都是从事机器学习工作,有技术积累,日常的工作与学习就是与比赛相似的内容,此外团队合作很默契,从开始就讨论列出来这类问题可能有突破的点,分工逐步实验,后面又能比较快提出应对具体问题的方案,最后团队有着丰富的参赛经验。
2017的KDD CUP,有收获也有喜悦,阿里云天池不仅在国际舞台上show了一把中国的交通难题,更是向全世界展示了中国技术的力量。
最后看看阿里云组织者的英姿:

九 城市计算研究
- 城市计算研究的提出
随着可移动感知设备和云计算的普及,人类可以实时感知城市活动和状态并进行存储。在这样的背景下,学术界提出了城市计算的概念并将其定位于致力从计算机和数据科学的角度理解和解决城市问题。2014年的综述研究介绍城市计算包括数据获取和存储、数据聚合、多源数据融合和算法模型设计四个阶段;同时研究指出城市计算旨在解决交通拥堵、能源消耗、环境污染和其他有关城市规划、社会经济发展及安全等方面的问题。在2017年KDD会议上,城市计算Tutorial环节详细介绍了学术界如何探索利用大数据和人工智能技术反哺城市建设。下面,我们将通过几个典型研究示例城市计算的研究思路和方法。
综述研究:
https://www.microsoft.com/en-us/research/publication/urban-computing-concepts-methodologies-and-applications/
Tutorial:http://uctutorial.chinacloudsites.cn/
- 城市计算研究示例
2.1 基于共享单车轨迹的自行车道规划
Planning Bike Lanes based on Sharing-Bikes’ Trajectories : https://www.microsoft.com/en-us/research/wp-content/uploads/2017/06/main.pdf
(1) 研究问题
随着共享单车在城市的大量投放,在短距离出行时人们越来越多选择骑车出行,但中国城市自行车道规划不足,大多数时间自行车和机动车同时行驶在一条干道上,有时自行车甚至会占据人行专用道,不仅带来了出行安全隐患而且导致了严重的交通管理问题。所以作者期望从单车出行轨迹中挖掘出和需求高度契合的自行车道规划路径,推动和优化规划工作。
那作者是如何将这个规划问题算法化的呢?
(2) 算法设计
作者将城市抽象成一个图结构,每条路段构成图的边,每两条边之间的节点为图的顶点,所需规划的自行车道就是图中满足出行需求和规划限制条件的边的集合。
出行需求被设计为体现在两个方面
1. 出行次数需求:计算通过边的轨迹数量。轨迹数量越多,规划价值越高。
2. 出行体验需求:单车能够连续通过被规划为自行车道边的长度总和。总和越长,规划价值越高。
规划限制条件文中考虑有两点:
1. 施工点的数量限制:一般政府仅允许在k个不相连的区域同时翻新车道。
2. 成本限制:财政拨款限制。每条路段翻新为自行车道的成本各不相同,决定于地理属性。
所以自行车道规划问题就被定义为图搜索问题,搜索目标是在满足规划限制条件下搜索能够带来最大规划价值边的集合。具体的公式请参见原文。
(3) 算法求解
但这个搜索问题是个NP-hard问题,所以作者设计了一套启发式贪婪算法:
Step 1. 对历时一个月的3971辆共享单车轨迹数据进行聚类,挑选具有最高价值的边为搜索起点。
Step 2. 从和搜索起点地理相连的路段中挑选在本次搜索中提升区域整体单成本价值最高的路段加入到最优边集合中。
Step 3. 迭代直至最优边集合中所有的成本达到财政拨款的额度。
小结:
本研究从数据出发,探索利用单车轨迹数据挖掘城市自行车道规划方案,具有很强的前瞻性。但其现实可应用性有待打磨,从数据中挖掘的路径可能并不适合设置自行车道,因为道路的宽度可能不足,也可能因为道路在城市交通运输中作为主要干道,需要保证机动车通行和减少安全风险,这些软性的因素都可以被加入到算法模型中,求得一个更符合实际的可行解。
2.2 危险品运输对城市安全影响评估
- No Longer Sleeping with a Bomb: A Duet System for Protecting
Urban Safety from Dangerous Goods: http://www.kdd.org/kdd2017/papers/view/no-longer-sleeping-with-a-bomb-a-duet-system-for-protecting-urban-safety-fr
受启发于天津港危险品仓库爆炸事件,作者基于城市危险品运输车轨迹和人群密度量化每个小区的风险值,挖掘常发性风险小区集合,并基于运输车行驶方向找到高风险小区路径,支持政府安全防控策略的制定。研究的主要步骤如下图所示,详细内容请参看原文。
最后作者提到,北京政府基于本文的研究结果决定改造北京美食街危险品运输管道,因为美食街是火锅店和人群都很密集的地方,安全风险值很高。
2.3 城市小区划分
- Segmentation of Urban Areas Using Road Networks: https://www.microsoft.com/en-us/research/publication/segmentation-of-urban-areas-using-road-networks/
2.2研究中的作者将路网划分成大小相等的网格,这样的划分虽然便于学术研究,却无法体现小区实际的功能意义,所以有研究学者利用图像处理中形态学处理方法对路网位图进行除噪和平滑处理,从而将道路相交组成的区域划分为小区,和现实世界的意义更贴近。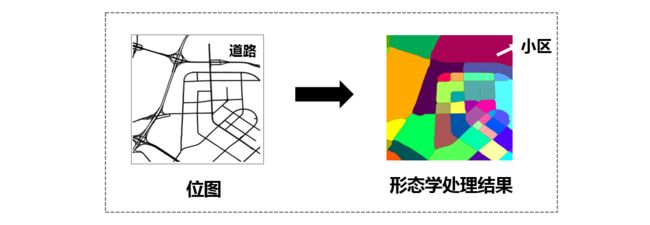
- 城市计算Workshop单元研究集锦
- Workshop专场: http://urbcomp.ist.psu.edu/2017/accept.html
KDD2017举办了城市计算的Workshop专场,所有的研究均可免费下载,有兴趣的同学可以深入挖掘下。其中有篇文章已经尝试将深度强化学习引入到区域信号灯协同控制领域,研究方向和实际应用需求完全相符,但作者过于简化动作空间,同时假设用于表示状态空间的信息输入是现实可收集的,最后基于简单的路口结构和模拟的OD矩阵用模拟器训练模型,和实际应用还有较大的差距,但随着模型设计更加符合路口实际结构,视频残采集数据更完全,相信深度反馈学习在信号控制领域也可以取得突破。
- 总结
我们生活的城市每天在产出大量的数据:人群移动轨迹、社交媒体舆论、公共出行记录和环境检测指标等,云存储和云计算使得我们可以实时记录、分析城市运行状态,解决城市在快速发展中遇到的问题。城市计算研究领域给我们提供了一个很好的思路,但由于各行业数据粒度(时间和空间)不同、数据处理方式不同、业务需求也不相同,所以很难有一个统一的解决方案,而且这些解决方案在最后真正落地时需要和业务进行深入的沟通:哪些信息可以来源于数据,哪些信息则需要管理经验及策略的指导。
十 KDD China (杰铭)
KDD 2017的首日下午,大会特别为SIGKDD China举行了中国数据挖掘会议(Data Science @China),吸引了众多听众参与。这是SIGKDD继2016年后第二次举办中国专场。也是现场除了印度专场之外,另外一家完全为了一个国家举办的专场会议。会议在KDD China秘书长、微软亚洲研究院研究员郑宇博士的主持下进行。香港科技大学的杨强,罗格斯大学的熊辉,微软亚洲研究院的郑宇,今日头条AI实验室的李磊,滴滴出行研究院的副院长叶杰平,西蒙弗雷泽大学的裴健,以及清华大学的唐杰和崔鹏分别分享了各自最新的研究成果。
罗格斯大学教授、百度高级顾问熊辉:AI人才的机遇与挑战
熊辉教授在本场演讲中为我们描述了AI人才当下面临的机遇与挑战。他指出,传统工作环境中任劳任怨、按部就班的“员工”在当前AI发展中会被一步步淘汰,即便是极具领域知识的“人才”也不再是行业的宠儿。他认为,当前AI业界最欢迎的是具备“人才”的专业技能、又具备领导力的“精英”。就此,熊辉给公司人才管理提出了几点建议:注重打磨公司文化、对人才供求做出正确的预见、实现职位描述精准化等等。当然,这里我们并不仅仅要讨论这个方法论。作为合作者,熊辉教授在本次KDD发表了8篇文章,下面我们选取一篇进行学习。
Prospecting the Career Development of Talents: A Survival Analysis Perspective
本文的贡献在于:
1)研究的方向是人才职业生涯路径建模,重点放在人才管理的两个问题上,即:营业额与职业发展。提出了一种新的生存分析方法来建模:利用排序约束公式基于多任务学习建立员工的职业发展道路。
2)对现实世界的人才数据进行广泛的评估以证明生存模型的效率,
3)预测营业额和员工的职业发展。
本文提出了两种模型:
- 人事变更行为模型
观测时间定义为
目标矩阵定义为
转换为多任务学习之后,任务变成了为下列观测值建模:
而正则化项通过下列公式计算惩罚因子得出
B)职业进展模型
初始定义为:![]()
损失函数为:

上图为一个把原始的职业生涯路径数据转化为适合多任务学习设置的示意图。
特征空间表达式为:
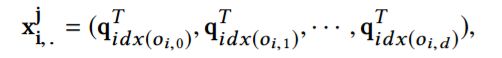

上表为本文提出的优化算法
上表为数据与特征列表
上图为实验结果
KDD China 中郑宇博士以及滴滴的叶杰平博士介绍了城市计算的部分,有关内容请参见第九部分。
总结:
这是阿里参会的大部分队员的合影,明年我们伦敦见!