基于python爬虫的百度翻译破解项目
基于python爬虫的百度翻译调用项目
- 前言
- 项目概述
- 难点
- 项目步骤以及问题的解决方法
- 观察百度翻译的翻译请求格式
- 获取sign值和token值
- 爬虫具体实现流程
前言
假期实在比较闲,决定学习一下爬虫的相关知识,同时也是熟悉一下脚本语言,也能为下学期抢课做点准备。
由于是初学者,也是第一次写博客,希望大家多指教。
项目概述
首先整体来说,项目主要引用python的request第三方库,给百度翻译网站发送一些翻译请求并接收网站的返回并进行返回数据的解析,从中提取出需要的信息。
难点
项目的难点在于如何模仿自己是一个浏览器而不被发现是一个爬虫在发出请求。想要进行模仿有如下做法:
- 在发送的请求中携带存放浏览器信息的User-Agent,使用post请求或者get等请求的时候包含在headers参数中
- 如果还是不行可以在headers参数中添加cookies字段,稍后会具体说明cookies的来源以及使用方法
- 有的时候网站为了反爬虫会在浏览器发出请求的时候对某些字段进行加密,我们需要在发出请求的时候模拟这些字段的加密
项目步骤以及问题的解决方法
观察百度翻译的翻译请求格式
先在输入框输入我们想要翻译的内容,清空之前的network信息,之后点击翻译,这是network中就会出现一次翻译中浏览器和服务器之间进行的全部交流

观察上图,我们综合名字和Type可以发现,有两次数据发送是比较特殊的,分别是langdetect和v2transapi,他们正是翻译中最主要的两次通讯,分别完成语言检测以及翻译功能。
我们仔细观察这两个post请求:

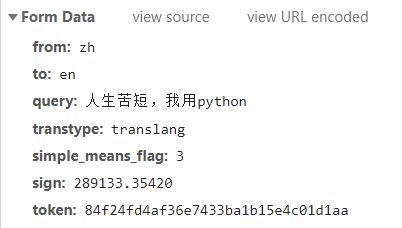
可以发现:
第一次的langdetect请求发送的数据很简单,只有我们的待翻译内容。观察其response:{“error”:0,“msg”:“success”,“lan”:“zh”},证明其只是用来返回内容的语种,所以不做过多分析,直接模拟post即可。
而第二次的请求中,我们发现多了许多奇怪的字段(后四个)。对于我们并不知道是干什么用的字段,最好的办法就是post的时候将其删去看看是否影响我们获得结果。如果影响再通过多次更换内容的请求来看这个字段是否会发生变化,不变的话填入固定的值即可,变化我们再讨论其来源。在本例中,经过我的多次尝试,发现transtype和simple_means_flag不光多次请求不会发生变化,将其去掉之后也不会影响结果的获得,果断删掉。
而sign和token则是在不同的情况下会发生改变的:
- sign值在查询的内容发生改变的时候也会发生改变
- token则类似cookie,虽然连续的多次查询中其值不会发生改变,但是更换设备等操作会使其发生改变。
所以我们需要搞明白sign值和token值的获取方法。
获取sign值和token值
附上参考链接:link,帮助很大,谢谢大佬。
其实之前的时候百度翻译反爬虫还没有这么狠,我们可以偷鸡使用手机版百度翻译,就没有sign和token这些费劲的东西了,只需要源语种、目标语种以及带翻译内容即可。但是现在手机版的百度翻译也绕不开这俩加密,全部木大了,只能硬夯。不过查看手机版作为爬虫的一种思路还是可以借鉴的,这里不多赘述。
首先,我们要找到源文件中为字典中sign值赋值的算法。全局搜索之后发现index_71文件中有看起来很像赋值的sign的出现。
(先点击Line29左侧按钮把代码格式化)
于是我们可以对这个sign进行分析。单机左侧行号可以在这里添加断点,然后再点击主界面上的翻译开始新的一轮翻译过程,观察代码运行情况。


观察发现:sign值的生成正是把我们的输入内容“人生苦短,我用python”作为参数丢到了函数y中进行一些操作,得到的就是sign了,这也与我们之前实验获得的结果相符。所以接下来的任务就是找到y函数的定义。
同样,在sign的下面就是token的获取,在这插个眼我们之后进行讨论。
我们把这个js文件复制下来进行分析。
从我们找到的sign的使用位置往上翻,在其使用域内最上方发现这样一段代码:
define("translation:widget/translate/input/translate", function(t, a) {
"use strict";
var e = t("translation:widget/translate/input/prompt"),
n = t("translation:widget/translate/input/textarea"),
r = t("translation:widget/common/util"),
s = t("translation:widget/translate/output/output"),
o = t("translation:widget/common/config/trans"),
i = t("translation:widget/translate/input/processlang"),
l = t("translation:widget/common/string"),
u = t("translation:widget/translate/input/soundicon"),
g = t("translation:widget/translate/input/hash"),
c = t("translation:widget/common/environment"),
d = t("translation:widget/translate/input/longtext"),
p = t("translation:widget/common/sendLog"),
m = t("translation:widget/translate/details/dictionary/simplemeans"),
f = t("translation:widget/translate/history/history"),
y = t("translation:widget/translate/input/pGrab"),
h = t("translation:widget/translate/details/adLink/adLink"),
w = {
可以看到其中有
y = t("translation:widget/translate/input/pGrab"),
于是我们再搜索引号内的内容,发现了y的来源:
define("translation:widget/translate/input/pGrab", function(r, o, t) {
"use strict";
function a(r) {
if (Array.isArray(r)) {
for (var o = 0, t = Array(r.length); o < r.length; o++)
t[o] = r[o];
return t
}
return Array.from(r)
}
function n(r, o) {
for (var t = 0; t < o.length - 2; t += 3) {
var a = o.charAt(t + 2);
a = a >= "a" ? a.charCodeAt(0) - 87 : Number(a),
a = "+" === o.charAt(t + 1) ? r >>> a : r << a,
r = "+" === o.charAt(t) ? r + a & 4294967295 : r ^ a
}
return r
}
function e(r) {
var o = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);
if (null === o) {
var t = r.length;
t > 30 && (r = "" + r.substr(0, 10) + r.substr(Math.floor(t / 2) - 5, 10) + r.substr(-10, 10))
} else {
for (var e = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), C = 0, h = e.length, f = []; h > C; C++)
"" !== e[C] && f.push.apply(f, a(e[C].split(""))),
C !== h - 1 && f.push(o[C]);
var g = f.length;
g > 30 && (r = f.slice(0, 10).join("") + f.slice(Math.floor(g / 2) - 5, Math.floor(g / 2) + 5).join("") + f.slice(-10).join(""))
}
var u = void 0,
l = "" + String.fromCharCode(103) + String.fromCharCode(116) + String.fromCharCode(107);
u = null !== i ? i : (i = window[l] || "") || "";
for (var d = u.split("."), m = Number(d[0]) || 0, s = Number(d[1]) || 0, S = [], c = 0, v = 0; v < r.length; v++) {
var A = r.charCodeAt(v);
128 > A ? S[c++] = A : (2048 > A ? S[c++] = A >> 6 | 192 : (55296 === (64512 & A) && v + 1 < r.length && 56320 === (64512 & r.charCodeAt(v + 1)) ? (A = 65536 + ((1023 & A) << 10) + (1023 & r.charCodeAt(++v)),
S[c++] = A >> 18 | 240,
S[c++] = A >> 12 & 63 | 128) : S[c++] = A >> 12 | 224,
S[c++] = A >> 6 & 63 | 128),
S[c++] = 63 & A | 128)
}
for (var p = m, F = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(97) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(54)), D = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(51) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(98)) + ("" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(102)), b = 0; b < S.length; b++)
p += S[b],
p = n(p, F);
return p = n(p, D),
p ^= s,
0 > p && (p = (2147483647 & p) + 2147483648),
p %= 1e6,
p.toString() + "." + (p ^ m)
}
var i = null;
t.exports = e
});;
只要我们将这一段代码转化为可用的js代码并在py程序中引用即可。
为了保持这段代码的可执行性,我们需要为其添加一个参数_gtk,这个参数是可以从服务器发来的网页源码中获取到的,我们只用它来运行这个函数。
而为了获取网页源码,我们需要在爬虫开始的时候与服务器进行一次握手,在保存cookies信息的同时从服务器返回的页面源码中获得token和_gtk参数。
爬虫具体实现流程
1. 首先准备爬虫所需要的url以及User-Agent
ini_url = 'https://fanyi.baidu.com' # 握手url
detact_url = 'https://fanyi.baidu.com/langdetect' # 语种检测url
dict_url = 'https://fanyi.baidu.com/v2transapi' # 翻译url
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
}
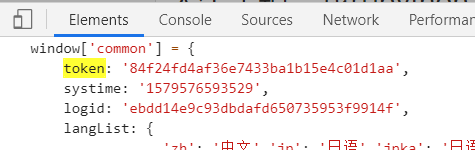
2. 之后要进行request第三方库中session模块的实例化,并进行握手来获取cookies并存储到session中。此外,我们还可以利用这次握手来获得token和_gtk,这要用到re模块,用我们找到的token和_gtk出现的格式写出正则表达式来在网页源码中进行模式匹配。我们只需要第一次自己找出来用来做模式匹配,之后便可以自动获得。

import request
import re
# 实例化session
session = requests.session()
# 建立会话,存储cookies
r = session.get(ini_url, headers=headers)
# 必须做两次来确保token是最新的
r = session.get(ini_url, headers=headers)
# 利用这次握手获得本次会话的token和_gtk
token = re.findall(r"token: '(.*?)',", r.content.decode())[0]
gtk = re.findall(r"window.gtk = '(.*?)';", r.content.decode())[0]
这里说一下我们爬虫发出请求的两种方式,一种是使用request直接发出请求,另一种是使用request库中的session模块,它们的区别在于session模块可以存储cookies信息,request则不会。
我们需要根据爬虫目标网站是否要求cookies进行选择是否需要使用session。一般来讲是需要登录的网站用cookies的比较多,session可以在登录的时候就保存cookies并在每次请求的时候都带上它。
相对的,request则比较灵活,我们可以选择是否携带cookies,但是如果需要携带的话则要求自己去进行一次解包找到cookies放到headers的cookies字段中,并且每次cookies过期都要重新手动获取,比较麻烦。
3. 根据gtk和输入的待查询字符串,调用js函数“token”,来计算得sign值
import execjs # 用来执行百度翻译生成sign的js函数
JS_CODE = """
function a(r, o) {
for (var t = 0; t < o.length - 2; t += 3) {
var a = o.charAt(t + 2);
a = a >= "a" ? a.charCodeAt(0) - 87 : Number(a),
a = "+" === o.charAt(t + 1) ? r >>> a: r << a,
r = "+" === o.charAt(t) ? r + a & 4294967295 : r ^ a
}
return r
}
var C = null;
var token = function(r, _gtk) {
var o = r.length;
o > 30 && (r = "" + r.substr(0, 10) + r.substr(Math.floor(o / 2) - 5, 10) + r.substring(r.length, r.length - 10));
var t = void 0,
t = null !== C ? C: (C = _gtk || "") || "";
for (var e = t.split("."), h = Number(e[0]) || 0, i = Number(e[1]) || 0, d = [], f = 0, g = 0; g < r.length; g++) {
var m = r.charCodeAt(g);
128 > m ? d[f++] = m: (2048 > m ? d[f++] = m >> 6 | 192 : (55296 === (64512 & m) && g + 1 < r.length && 56320 === (64512 & r.charCodeAt(g + 1)) ? (m = 65536 + ((1023 & m) << 10) + (1023 & r.charCodeAt(++g)), d[f++] = m >> 18 | 240, d[f++] = m >> 12 & 63 | 128) : d[f++] = m >> 12 | 224, d[f++] = m >> 6 & 63 | 128), d[f++] = 63 & m | 128)
}
for (var S = h,
u = "+-a^+6",
l = "+-3^+b+-f",
s = 0; s < d.length; s++) S += d[s],
S = a(S, u);
return S = a(S, l),
S ^= i,
0 > S && (S = (2147483647 & S) + 2147483648),
S %= 1e6,
S.toString() + "." + (S ^ h)
}
"""
# 根据gtk和输入的待查询字符串,调用js函数“token”,来计算得sign值
sign = execjs.compile(JS_CODE).call('token', str, gtk)
4. 这样我们进行查询的参数就全部获得了,通过模拟浏览器的langdetect和v2transapi两次post请求来获得内容的翻译。
首先是langdetect:
detact_url = 'https://fanyi.baidu.com/langdetect' # 语种检测url
str = input("请输入要翻译的东西\n")
form_data = {'query': str
}
# 语种检测
r = session.post(detact_url, headers=headers, data=form_data)
观察r.content.decode()存放的服务器返回数据,{“error”:0,“msg”:“success”,“lan”:“zh”}我们可以看出这是一个字典,而我们需要的是“lan”字段。将其提取出来之后使用。
lan = json.loads(r.content.decode())["lan"]
由于我们在post请求的时候如果不包含源语种以及目标语种的信息会报错,而我们又希望额能够同时做到中译英和英译中,所以我们需要获得langdetect的信息,并用于生成v2transapi的data。
dict_url = 'https://fanyi.baidu.com/v2transapi' # 翻译url
# 开始查词
# 构造查询数据
dict_data = {'from': lan,
'to': 'zh' if lan == 'en' else 'en',
'query': str,
'sign': sign,
'token': token,
}
# 完善查询地址url(添加from=以及to=)也可以在post中添加参数
dict_url += '?from=' + lan + '&to=' + ('zh' if lan == 'en' else 'en')
r = session.post(dict_url, data=dict_data, headers=headers)
5. 解析本次查询所获得的服务器返回消息
{
"trans_result":{
"data":[{
"dst":"Life is short. I use python",
"prefixWrap":0,
"result":[[0,"Life is short. I use python",["0|27"],[],["0|27"]["0|27"]]],
"src":"\u4eba\u751f\u82e6\u77ed\uff0c\u6211\u7528python"
}],
"from":"zh",
"status":0,
"to":"en",
"type":2,
"keywords":[
{"means":["Life is but a span","Life's too short","Life is short"],"word":"\u4eba\u751f\u82e6\u77ed"},
{"means":["\u87d2","\u86ba\u86c7"],"word":"python"}
]
},
"liju_result":{"double":"","single":""},
"logid":3232460289
}
我们发现,翻译结果就放在字典里的trans_result键的值里的data键的值里的第一条记录里的dst键对应的值里。所以我们只要用之前相同的方法把结果提取出来就可以。
ret = json.loads(r.content.decode())['trans_result']['data'][0]['dst']
print(ret)
大功告成。