Hive 史上最全面的大数据学习第九篇(四) Hive Sql 操作 今天的你也要加油啊

Hive概述 & 安装方式详解
Hive表操作
Hive表分类
Hive Sql 操作
Hive 自定义函数
Hive On HBase
五、Hive SQL 操作
5.1 Select 语句
使用正则表达式指定列
create table
logs
(
uuid string,
userid string ,
fromUrl string ,
dateString string,
timeString string,
ipAddress string,
browserName string,
pcSystemNameOrmobileBrandName string ,
systemVersion string,
language string,
cityName string
)
partitioned BY (day string)
row format delimited fields terminated
by ' ';
load data local inpath '/clean01' into table logs partition(day='2020-07-30');
# 设置此属性 开启正则匹配
set hive.support.quoted.identifiers=none;
# 使用正则表达式查找string相关字段的信息 注意 引号为反引号 (esc下面那个)
select userid ,`.*string` from logs;

5.2 Where 语句
Where 作为SQL中的条件查询
0: jdbc:hive2://HadoopNode00:10000> select * from logs where userid ='707a2a9c-c89f-4041-a276-df12611a9363';
5.3 Group By
聚合函数
0: jdbc:hive2://HadoopNode00:10000> select address.city as city ,avg(salary) as avgSalary from t_user group by city;

5.4 Join 语句
内连接
create table testuser(
id int,
name string,
sex boolean,
age int,
salary double,
hobbies array,
card map,
address struct
)
row format delimited
fields terminated by ','
collection items terminated by '|'
map keys terminated by '>'
lines terminated by '\n';
1,zhangsan,true,10,20100,TV|GAME,JIANSHE>001|ZHAOSHAN>002,CHAINA|BJ
2,lisi,false,20,20100,TV|GAME,JIANSHE>002|ZHAOSHAN>006,CHAINA|BJ
3,wangwu,true,30,20100,TV|GAME,JIANSHE>003|ZHAOSHAN>007,CHAINA|HN
4,ermazi,false,49,20070,TV|GAME,JIANSHE>004|ZHAOSHAN>008,CHAINA|SH
5,ergouzi,false,50,21000,TV|GAME,JIANSHE>005|ZHAOSHAN>009,CHAINA|BJ
# 使用内连接 查询性别不同但是工资相同的人
select a.sex,a.name,a.salary,b.sex,b.name,b.salary from testuser a join testuser b on a.salary = b.salary where a.sex != b.sex;
select a.sex,a.name,a.salary,b.sex,b.name,b.salary from testuser a join testuser b on a.salary = b.salary where a.sex = true and b.sex = false;
查询 来自三个不同城市的人且具有第二个爱好相同的人
select
a.address.city ,a.name as name ,a.hobbies[1] as hobby,
b.address.city ,b.name as name, b.hobbies[1] as hobby,
c.address.city ,c.name as name ,c.hobbies[1] as hobby
from testuser a
join testuser b on a.hobbies[1] = b.hobbies[1]
join testuser c on b.hobbies[1] = c.hobbies[1]
where a.address.city = 'SH' and b.address.city = 'HN' and c.address.city = 'BJ';
JOIN优化
这种优化其实是指手动指定那些数据最大,从而最后查询(和之前查过的,已经缓存上的数据进行对比),这样可以减少服务器的压力
在上述三表连接的操作中,其实就是一种“失误”的写法,为什么呢 ?因为通过比较我们可以发现,来自北京的人最多,也就是说当前a表最大。Hive同时假定查询中最后一个表是最大的那个表。在对每行记录进行连接操作时,它会尝试将其他表缓存起来,然后扫描最后那个表进行计算。因此,用户需要保证连续查询中的表的大小从左到右是依次增加的。
但是咱们将最大的表放在第一个,显然就违反这个逻辑,因为测试数据较小我们根本不会发现有任何差异,但是真正的在生产环境中,我们就需要将表依次从小到大进行排列,来达到效率的最大化。
但是假如我们在书写SQL语句的时候不能将最大的表放在最后,或者忘记放在最后,有什么办法去解决这个问题呢?
幸运的是,用户并非总是要将最大的表放置在查询语句的最后面的。这是因为Hive还提供了一个“标记”机制来显式地告之查询优化器哪张表是大表,来看具体的SQL语句:
select
/*+STREAMTABLE(a)*/
a.address.city as name, a.name, a.hobbies[1] as hobby ,
b.address.city as name, b.name,b.hobbies[1] as hobby ,
c.address.city as name, c.name,c.hobbies[1] as hobby
from testuser a
join testuser b on a.hobbies[1] = b.hobbies[1]
join testuser c on a.hobbies[1] = c.hobbies[1]
where a.address.city = 'BJ' and b.address.city = 'SH' and c.address.city = 'HN';
/+STREAMTABLE(a)/ 使用此关键字,括号写表的 |别名|
6.5 排序
Order By
order by 在此处叫做全局排序
select * from testuser order by salary;
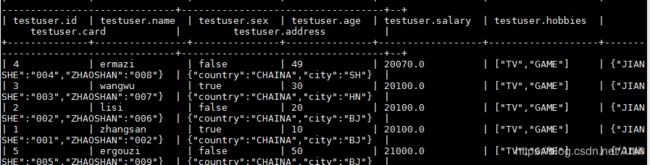
select * from testuser order by salary desc;
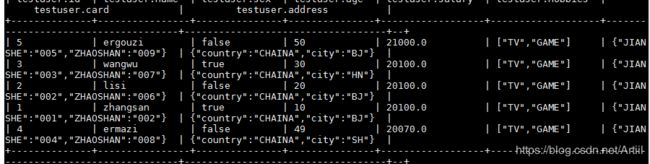
Sort By
select * from testuser sory by salary;
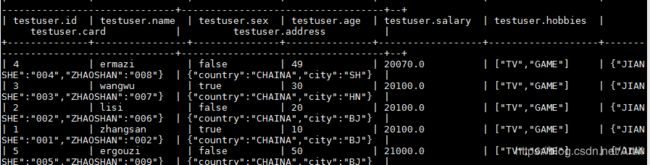
现在看来 sort by 和order by 没有任何区别
原因在于默认情况下 reduceTask的个数为为1
所以不管是全局还是局部都不会有任何区别
设置ReduceTask个数
# 获取ReduceTask个数
set mapreduce.job.reduces;
# 设置 ReduceTask个数
set mapreduce.job.reduces = 2;
select * from testuser order by salary;

select * from testuser sory by salary;

将ReduceTask个数设置成2以后,此时就会启动两个RecueTask进行数据的处理,此时就能体现出来SortBy和Order By的区别
Orderby 的运行结果还是原来的,到那时SortBy的数据被分为两个区 ,此时数据就按照局部进行排序
献给每一个正在努力的我们,就算在忙,也要注意休息和饮食哦!我就是我,一个在互联网跌跌撞撞,摸爬滚打的热忱,给个三连吧~ 还有就是不要只看,多动手才行!