keras入门(一)——迁移VGG16模型训练mnist数据集实现手写数字识别
作为一个刚入门keras的小白,实战的时候参照网上修改VGG16模型训练mnist数据集实现手写数字识别,掉进了不少坑,走了不少弯路,也学习了很多知识。下面跟大家分享一下,有问题欢迎大家评论指出~
整个程序参考了以下文档和视频:
人工智能深度学习第21讲:迁移学习
b站视频
(一)修改VGG16模型
model_vgg=VGG16(include_top=False,weights="imagenet",input_shape=(48,48,3))
for layer in model_vgg.layers:
layer.trainable=False
model=Flatten(name="flatten")(model_vgg.output)
model=Dense(10,activation="softmax")(model)
model_vgg_mnist=Model(inputs=model_vgg.input,outputs=model,name="vgg16")1.keras中VGG16模型
VGG16模型,权重由ImageNet训练而来,模型的默认输入尺寸是224x224,但是最小是48x48,这个一定要注意。
keras.applications.vgg16.VGG16(include_top=True,weights=‘imagenet’,input_tensor=None,input_shape=None,pooling=None,classes=1000)
参数:
include_top:是否保留顶层的3个全连接网络
weights:None代表随机初始化,即不加载预训练权重。'imagenet’代表加载预训练权重
input_tensor:可填入Keras tensor作为模型的图像输出tensor
input_shape:可选,仅当include_top=False有效,应为长为3的tuple,指明输入图片的shape,图片的宽高必须大于48,如(200,200,3)
2.for循环
固定住模型中卷积层和池化层的参数,不让他们进行训练。可以从截图中看到,要训练的参数大大减少。

3.添加其他层,组合
为了减少训练时间我就直接添加Flatten层然后分类了,大家可以自行添加全连接层。
然后通过Model将自己添加的层和VGG模型组合起来。
(二)编译模型
sgd=SGD(lr=0.05,decay=1e-5)
model_vgg_mnist.compile(optimizer=sgd,loss="categorical_crossentropy",metrics=['accuracy'])(三)加载mnist数据集,修改数据集尺寸、类型
#加载mnist数据集,为了缩短训练时间取数据集前10000个
(x_train,y_train),(x_test,y_test)=mnist.load_data()
x_train,y_train=x_train[:10000],y_train[:10000]
x_test,y_test=x_test[:10000],y_test[:10000]
#修改数据集的尺寸、将灰度图像转换为rgb图像
x_train=[cv2.cvtColor(cv2.resize(i,(48,48)),cv2.COLOR_GRAY2BGR)for i in x_train]
x_train=np.concatenate([arr[np.newaxis]for arr in x_train]).astype('float32')
x_train=x_train/255
x_test=[cv2.cvtColor(cv2.resize(i,(48,48)),cv2.COLOR_GRAY2BGR)for i in x_test]
x_test=np.concatenate([arr[np.newaxis]for arr in x_test]).astype('float32')
x_test=x_test/2551.着重说一下修改图像的尺寸和类型!
我一开始不懂np.concatenate和np.newaxis,就寻思用for循环不也能来实现修改图像的尺寸和类型嘛。
for i in range(len(x_train)):
x_train[i]=cv2.resize(x_train[i],(48,48))然后就残忍的报错了:![]() 我想之前我用opencv这个resize函数处理图像没有问题啊,图像不就是一个数组嘛,那我取出来x_train其中一个元素不也是数组嘛,放进resize为什么不行。
我想之前我用opencv这个resize函数处理图像没有问题啊,图像不就是一个数组嘛,那我取出来x_train其中一个元素不也是数组嘛,放进resize为什么不行。
经过我苦苦挣扎后,才明白“对象”的意义!resize输入参数虽然是数组,但是输入的是一个独立的数组,也就是数组这个对象。而我取出来x_train的一个元素,这个元素虽然代表一个图片,但是他不是独立的一个,他是x_train这个数组对象的一部分。所以程序通过list列表的方式改变每一个图像的尺寸和类型,然后又用np.concatenate和np.newaxis将x_train这个列表还原成一个数组。
2.np.concatenate和np.newaxis
首先x_train这个列表里面(上一步把x_train列表化了已经),每一个元素都是一个图片,大小为(48, 48, 3)。我们需要得到的x_train数组的shape为(10000,48,48,3)。所以我们需要:
- 第一步:通过np.newaxis函数把每一个图片增加一个维度变成(1,48,48,3)。所以就有了程序中的arr[np.newaxis]。
- 第二步:通过np.concatenate把每个数组连接起来组成一个新的x_train数组,连接后的x_train数组shape为(10000,48,48,3)
(四)编码、训练、评估、保存模型
#编码
y_train=np_utils.to_categorical(y_train,10)
y_test=np_utils.to_categorical(y_test,10)
#训练模型
model_vgg_mnist.fit(x_train,y_train,epochs=3,batch_size=100)
#评估模型
result=model_vgg_mnist.evaluate(x_test,y_test)
print("loss:",result[0])
print("acc:",result[1])
#保存模型
model_vgg_mnist.save('my_mnist_vgg16.model')因为用cpu训练,条件有限,为节省时间省略了全连接层,只训练了3轮,大约十五分钟,正确率大约80%
(五)测试
model = load_model('my_mnist_vgg16.model')
img = cv2.imread('F:/Qin/Produce/keras/other_mnist_cnn/test_pic/4.jpg')
cv2.imshow("图片:4",img)
img =img.astype('float32')
img=cv2.resize(img,(48,48))
img = (img.reshape(1,48,48,3))/ 255
predict = model.predict(img)
predict=np.argmax(predict,axis=1)
print('识别为:')
print(predict)
cv2.waitKey(0)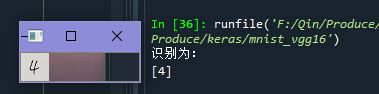
预测模型类别这里也要注意!
不能直接写成predict = model.predict_classes(img),会报错。

原因:
参考网址
The predict_classes method is only available for the Sequential class (which is the class of your first model) but not for the Model class (the class of your second model).
With the Model class, you can use the predict method which will give you a vector of probabilities and then get the argmax of this vector (with np.argmax(y_pred1,axis=1)).
第一次用的网络是在model=Sequential()下添加模块的的方法,Sequential class可以使用model.predict_classes()
第二次用的网络是编写好网络结构后使用model=Model(input=mnist_input,outputs=output)综合起来的方法,也就是Model class,无法使用model.predict_classes(),但是可以使用组合形式预测。
(六)测试结果
用自己手写的0~9张数字图片进行识别,有4张识别正确,网络还需要进一步完善和训练。