2020美赛C题赛后总结之——文本预处理Pyhotn编程代码
1.背景介绍
美赛C题涉及到文本处理之间的工作,笔者学艺不精,广为搜罗了很多代码加以完善改进,封装成一个个的函数,这些函数都很有针对性,主要应用于文本预处理包括,排序、分词、获取语料库、去标点、统计词频、特征提取、词性还原、去停用词等。
2.任务分析
为了更好地了解代码,我们首先来认识一下数据集的格式。
文中涉及三个数据集microwave.tsv,hair_dryer.tsv, pacifier.tsv
表头都是一样的,以pacifier(奶嘴)为例。
我们要用到的有如下几列。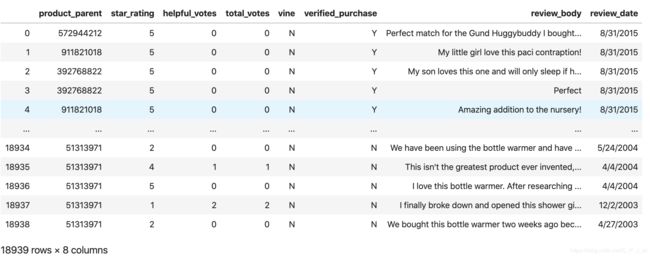
3.Pyhton代码
库引用
#代码所涉及到的库(部分,其余为引用的将在后面引用)
import numpy as np
import pandas as pd
import re
from os import path
import matplotlib.pyplot as plt
import jieba
数据读取
读取数据,由于文件格式不是常见的csv,而且也不必读取全部的列,
因此笔者编写了一个新的函数,用于读取特定文件特定列的数据
def getData(filename,cols):
train=pd.read_csv(filename, sep='\t',header=0,usecols=cols)
return train
小写化并排序
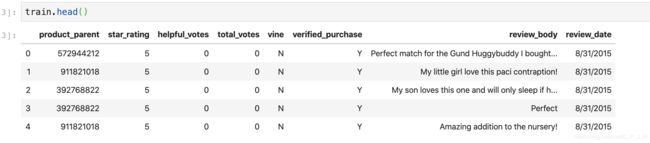
如上图所示我们只需要对train的4-7列小写化并排序
def sortLow(train):
for i in range(3):
train.iloc[:,i+4]=train.iloc[:,i+4].str.lower()
train=train.sort_values(by=["vine",'verified_purchase'],ascending=False)
train=train.reindex(list(range(len(train))))#排序后索引会乱掉我们重置索引
return train
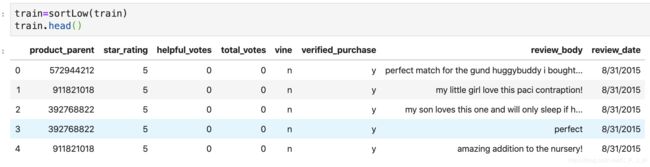
删除过短的评论记录
review_body列中包含用户的评论内容,我们希望删除评论内容小于三个单词的行
#对字符串中单词计数
def count_words(series):
len_li=[]
for string in series:
string=str(string)
string=string.split(' ')#将文章按照空格划分开
len_li.append(len(string))
return pd.Series(len_li)
#删除小于三个单词的评论
train['counts']=count_words(train.review_body)
train=train[train.counts>3]
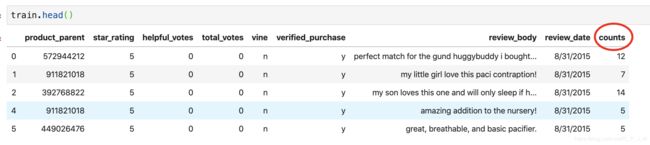
获取简单的语料库
我们希望将所有评论汇总到一起,组成一个语料库。
from string import punctuation
punc=punctuation
#去除标点和数字
def text_save(filename, data):#filename为写入CSV文件的路径,data为要写入数据列表.
file = open(filename,'a')
for line in data:
line=str(line)
line = re.sub(r"[{}]+".format(punc)," ",line)#正则匹配标点
line = re.sub(r"\d+"," ",line)#正则匹配数字
file.write(line+" ")
file.close()
print("保存文件成功")
#获取词典
def getDicCsv(name):
review_body=train['review_body']
review_body=list(review_body)#将评论存入列表
text_save(name,review_body)
调用getDicCsv函数之后我们就获得了一个txt的语料库
分词
#分词
import jieba
def dis(path):
text = open(path, encoding='utf-8').read()
text_cut=jieba.cut(text)
return text_cut
上述代码用于将txt文件分成单个词语列表
def rmSym(Series):#去除标点符号存入列表
lis=[]
for line in Series:
line=str(line)
line=line.lower()
line = re.sub(r"[{}]+".format(punc)," ",line)
line = re.sub(r"\d+"," ",line)
lis.append(line)
return lis
上述代码用于对一个单独的Series进行分词处理,对于train[‘review_body’],该函数会输出一个二维列表,每个子列表都对应一条评论的分词结果
词频统计
#词频统计
def getWordFre(wordList,num):
#输入词语列表和获取top词数量
word_counts = collections.Counter(wordList) # 对分词做词频统计
word_counts = word_counts.most_common(num) # 获取前n最高频的词
return word_counts#返回词频列表
输入词语列表和数量,输出一个词频列表,长度为num,词频从大到小排列。
词形还原
from nltk import word_tokenize, pos_tag
from nltk.corpus import wordnet
from nltk.stem import WordNetLemmatizer
def get_wordnet_pos(tag):
if tag.startswith('J'):
return wordnet.ADJ
elif tag.startswith('V'):
return wordnet.VERB
elif tag.startswith('N'):
return wordnet.NOUN
elif tag.startswith('R'):
return wordnet.ADV
else:
return None
#词形还原输出列表
def lem(sentence):
# 获取单词的词性
tokens = word_tokenize(sentence) # 分词
tagged_sent = pos_tag(tokens) # 获取单词词性
wnl = WordNetLemmatizer()
lemmas_sent = []
for tag in tagged_sent:
wordnet_pos = get_wordnet_pos(tag[1]) or wordnet.NOUN
lemmas_sent.append(wnl.lemmatize(tag[0], pos=wordnet_pos)) # 词形还原
return lemmas_sent
对二维列表进行词形还原并展开成一维列表
def pureList(data_list):
lem_list=[]
for i in data_list:
lem_list = lem_list+lem(i)
return lem_list#返回词形还原后的一维列表
去停用词
from nltk.corpus import stopwords
stop_words=stopwords.words('english')
noStopList = [word for word in wod_list if(word not in stop_words)]
特征提取
from sklearn.feature_extraction.text import CountVectorizer
#语料
corpus = noStopList
#将文本中的词语转换为词频矩阵
vectorizer = CountVectorizer()
#计算个词语出现的次数
X = vectorizer.fit_transform(corpus)
#获取词袋中所有文本关键词
word = vectorizer.get_feature_names()
#查看词频结果
X.toarray()
word
from sklearn.feature_extraction.text import TfidfTransformer
#类调用
transformer = TfidfTransformer()
print(transformer)
#将词频矩阵X统计成TF-IDF值
tfidf = transformer.fit_transform(X)
#查看数据结构 tfidf[i][j]表示i类文本中的tf-idf权重
tfidf_arr=tfidf.toarray()
import heapq
#获取一个一维数组中最大的n个词
por=list(por)
#此时por为[0,0,2.333,0,...,4.56.0,2,1,3.23...]好长的一个列表
re2 = map(por.index, heapq.nlargest(300, por))
#求最大的n个索引 nsmallest与nlargest相反,求最小
#注意re2是一个map对象
拆分日期列
#如果review_date数据格式为datetime要转化成字符串形式
train['year']=train['review_date'].apply(lambda x:x.split('/')[2])
train['month']=train['review_date'].apply(lambda x:x.split('/')[0])
然后可以根据dataframe索引筛选特定年月的数据,也可以运用groupby方法进行分类汇总
获取特定年月的词频
def get_month_review_word_fre(year,month,dataframe,fre_num):
year=str(year);month=str(month)
test=train[train['year']==year]
test=test[test.month==month]
test=test.review_body
test=rmSym(test)
pureSenList=[]
for sen in test:
tem=lem(sen,stop_words)
pureSenList+=tem
word_fre=getWordFre(pureSenList,fre_num)
return word_fre
将输出year年month月所有评论的前fre_num个词频
4.声明
- 上文的函数中存在函数中调用函数的情况,请读者注意。
- 欢迎广大读者在留言区指正错误,提出意见,如果认为本文对您有帮助可以加个关注点个小赞,不胜感激。
- 这些代码的原型的原链接已经难以找到,笔者希望原作者能够私信的形式告知笔者,以便笔者在借鉴中声明。