Vivado HLS(High-level Synthesis)笔记一:HLS基本流程
前言
实验室项目需要,需要将在服务器段跑出的网络参数配置到FPGA上,一种方法是直接利用verilog或者vhdl直接去写一个网络的前向传播模型,另一种就是用 C/C++ 来描述网络的前向传播模型,然后利用Vivado的HLS将其转化为硬件描述语言——verilog或者vhdl。第一种方法资源利用率高,但需要考虑时序和并行性(硬件语言设计的两个重要因素),这一点比较困难;第二种方法相对高效且容易一点;作为一个新手,本着先将流程跑通的想法,我选择了第二种方法作为首次尝试的方法,通过高亚军老师的视频课来学习的,附上链接:https://www.bilibili.com/video/av41246874
先来谈谈CPU、GPU、DSP、FPGA之间的区别:https://blog.csdn.net/Qiuoooooo/article/details/81779583
对于一个软件工程师,应该掌握的程度:
- FPGA内部每个单元的功能;
- 具体的算法操作和每个单元之间的对应关系;
- 算法模型中资源的利用率;
- 算法模型的优化方法;
总结起来就一句话“怎样能使得我们用C/C++转化成的HDL代码可以高效运行?”
一. Vivado HLS的工作原理
1. History of ESL(Electronic System Level)
CAD-CAE-EDA
- Computer Aided Design
- Computer Aided Engineering
- Electronic Design Automation
在EDA这个阶段,最典型的特征就是出现了硬件描述语言——VHDL和Verilog;
到了现在,就出现了ESL(电子系统级设计方法)这个概念,它的本质是在说在ESL这个阶段我们希望采用具有更高抽象度的方式去描述系统行为,所以在这个阶段有两个显著特征:
- 使用高级语言(例如C或者C++),XILINX有Vivado HLS这个工具;
- 使用基于模型的设计工具——System Generator;
2. High-level Synthesis Benefits
- 对于硬件工程师,提高项目效率,不需要考虑并行性和时序的问题,直接在算法级考虑优化;
- 对于软件工程师,可以提高系统性能,原来需要CPU、GPU或者DSP才能实现的算法现在都可以通过FPGA来实现,一方面提高了吞吐率,另一方面也改善了功耗;
- 在C/C++这个层面开发算法并且验证;
- 通过优化工具来高效指导转化过程;
在算法描述完成后,需要一个相应文本来测试我们的算法,
3. Vivado HLS的综合流程
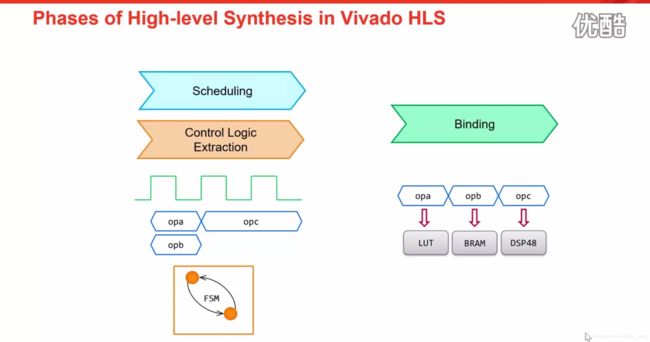
- Scheduling:确定每个时钟周期应该做什么操作,同时这个操作大概需要几个时钟周期完成,以及是否可以并行执行;
- Control Logic Extraction:控制逻辑的提取通常会生成一个状态机,这个可以在HDL代码中看到;
- Binding:确定每个操作需要用什么资源去实现,完成这样的一个从操作到资源映射过程;
下面来看一下对于这几个过程的实例:
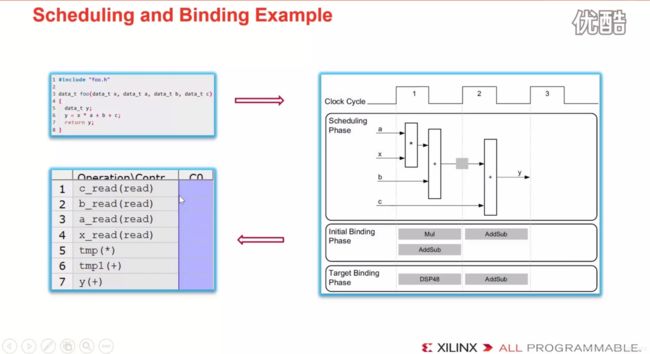
Scheduling and Binding Example的例子如下,下面这个例子比较简单,所以只有一个状态C0;
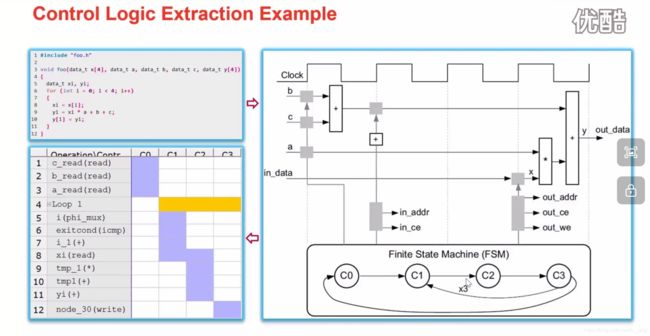
扩至逻辑的提取例子,有四个状态,在C0状态执行b+c,C1状态产生x和数组的地址,C2状态执行相应的乘法操作,C3状态将结果写入y数组的对应位,如此循环几次,直到到达循环边界退出循环。需要注意的是,生成的控制状态(左下)和状态机(右下)不是一一对应的,但它们之间非常接近。
4. Vivado HLS设计流程
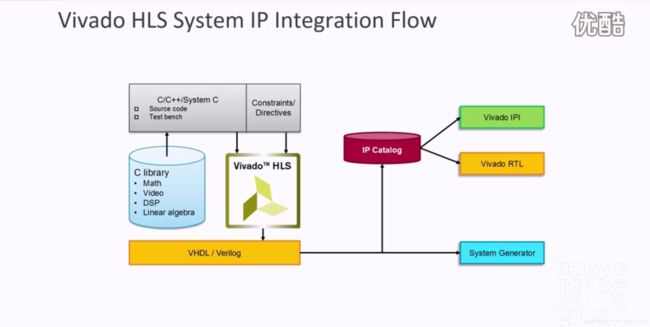
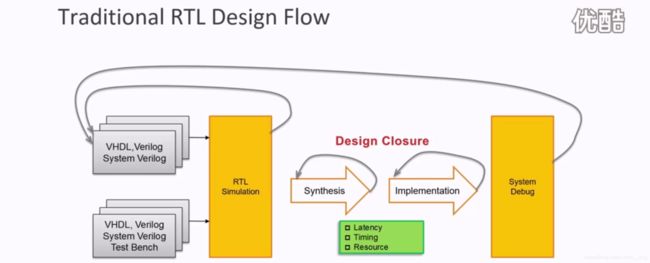
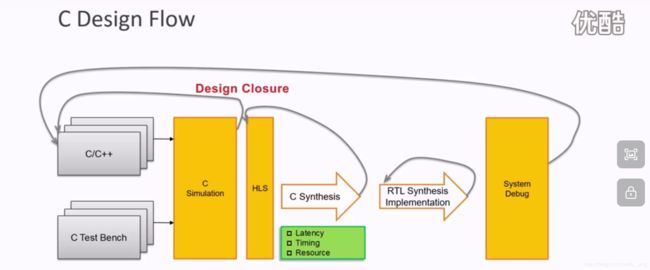
- Vivado HLS的设计输入包括Test bench、C/C++和Directives,相应的设计输出有IP(在Vivado的IP Catalog中)、DCP(RTL代码综合后的网表文件)、SysGen(HLS之后的结果可以导入SysGen中使用)。
- Test bench的作用有两点:一是验证C/C++代码的正确性;二是在与RTL的协同仿真阶段,生成用于RTL级验证的Test bench;
- 对于一个工程,只可以有一个顶层的函数用于综合,这个函数下面的子函数也可以被综合,通常情况下C/C++综合后的RTL代码的结构和原始的C函数描述的结构一致(除了子函数所需要的逻辑量很小、算法功能很简单时,综合阶段不会单独有这个结构,将HLS INLINE off关掉时就会完全一致)。
- 并不是所有的C/C++语言风格的代码都能被综合,有两点需要注意:一是动态内存分配,二是操作系统层面;
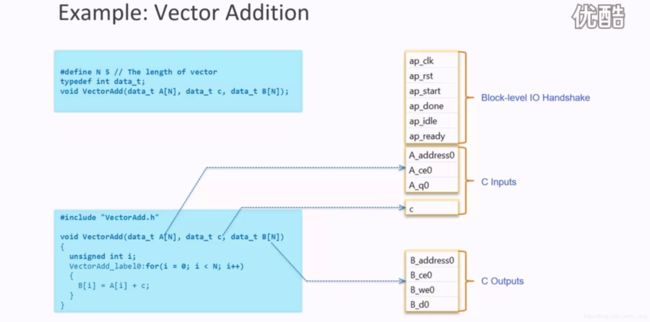
- 一个C/C++代码最后映射到RTL代码有三大类接口,包括Block-level IO Handshake(握手信号)、C Inputs、C Outputs;
Directives的两种方式:
-
将每个directive以directives.tcl格式作为一个Tcl命令单独存放,以"#"作为标识;
优势在于:每个solution都有独立的directives,如果这个solution需要重新综合,那么只有这个solution下面的directive会起到作用;不足之处在于:如果C source code文件需要被给到第三方,那么需要将directives.tcl包含其中,对于一个代码需要获得同样的综合结果,那么同样的directives.tcl必不可少。 -
将每个directive嵌入到C/C++源码中,以pragma格式出现,"%"作为标识;
优势在于:如果C source code文件需要被给到第三方,不需要单独将directives.tcl交付,对于一个代码需要获得同样的综合结果,也不需要额外的directives.tcl;不足之处在于:如果一个solution需要重新综合,那么所有的directives都要被执行。
几点小技巧:
- 为C/C++代码中的for循环单独创建标签,这会使得在创建directives时非常方便;
- 最好将directives单独存放,不要将其和源码放在一起;
- Test bench中的main()函数的返回结果值为int类型,仿真通过返回值为0,不通过才是1;
- 通常情况下RTL代码的层次和原始的C/C++代码层次一致;