采用Vivado HLS为视频处理实现中值滤波器和排序网络
Vivado的高层次综合功能将帮助您为嵌入式视频应用设计更好的排序网络。
从汽车到安全系统再到手持设备,如今采用嵌入式视频功能的应用越来越多。每一代新产品都需要更多的功能和更好的图像质量。但是,对于一些设计团队来说,实现高质量的图像并非易事。
作为赛灵思的一名DSP设计现场应用工程师,我经常被问到有关IP和高效视频滤波实现方法这方面的问题。我发现利用最新Vivado®设计套件的高层次综合(HLS)功能,很容易在任何赛灵思7系列All Programmable器件中实现基于排序网络的高效中值滤波方法。
在详细探讨该方法之前,我们先来回顾一下设计人员在图像完整性方面所面临的一些挑战以及解决这些问题常用的滤波技术。
数字图像噪声大多出现在系统获取或传输图像的过程中。例如,扫描仪或数码相机的传感器和电路可以产生几种类型的不规则噪声。通信通道中的随机比特错误或模数转换器错误会导致特别麻烦的“脉冲噪声”。这种噪声经常被称为胡椒盐(salt-and-pepper)噪声,因为它以随机白点或黑点的形式出现在显示器的图像表面,严重降低了图像质量(图1)。

为降低图像噪声,视频工程师通常会在设计中应用空间滤波器。这些滤波器利用噪声点周围像素的优质特性或数值对图像中渲染较差的像素进行替换或加强。空间滤波器主要分为线性和非线性两种。最常用的线性滤波器被称为均值滤波器。它用邻近像素的均值替换每个像素值。这样,渲染较差的像素就可根据图像中其它像素点的平均值得到改善。均值滤波器能以低通方式快速去除图像噪声。但是,该方式通常伴有副作用——使整体图像的边缘变得模糊。
大多数情况下,非线性滤波法比线性均值滤波法更好。非线性滤波特别善于消除脉冲噪声。最常用的非线性滤波器是次序统计滤波器。而最受欢迎的非线性次序统计滤波器是中值滤波器。
中值滤波器广泛用于视频与图像处理,因为此种滤波器具有出色的降噪能力,而且模糊程度比相同尺寸的线性平滑滤波器低得多。与均值滤波器类似,中值滤波器也要依次分析图像中的每个像素,并观察其邻近的像素以判定该像素是否能代表其周围像素。但是,中值滤波器并非简单地将像素值用周围像素的平均值进行替换,而是用周围像素值的中值来替换。由于中值必须是邻近某个像素的实际值,因此中值滤波器在跨越边缘时不会创建新的虚拟像素值(避免了均值滤波器的边界模糊影响)。因此,中值滤波器在保留锐边方面比其它任何滤波器做得都要好。这种滤波器在计算中值时,首先将周围窗口中的所有像素值按数值大小顺序进行排序,然后用中间像素值替换待过滤的像素(如果待计算区域包含偶数个像素,那么使用中间两个像素的平均值)。
例如,假设一个3x3像素窗口以值为229的像素为中心,该窗口值如下
39 83 225
5 229 204
164 61 57
我们可以对像素进行排序,获得顺序列表为5 39 57 61 83 164 204 225 229。
中值就是位于中间的像素值,即83。在输出图像中用该值替代初始值229。图2表明在图1噪声输入图像中应用3x3中值滤波器后的效果。待过滤像素周围的窗口越大,滤波效果越显著。

中值滤波器具备出色的降噪能力,因此也被广泛应用于扫描速率视频转换系统的内插级,例如为实现隔行视频信号而将场速率从50Hz转换为100Hz的运动补偿内插程序,或者隔行至逐行转换中的边缘定向内插程序。如欲了解有关中值滤波器更详尽的介绍,有兴趣的读者可以参考 [1]和 [2]。
在运用中值滤波器时最为关键的是确定使用哪种排序方法,以获得用来生成每个输出像素的像素排序列表。排序过程需要大量计算时钟周期。
目前,赛灵思在Vivado设计套件中可提供高层次综合。我通常会告诉人们,可以根据排序网络概念在C语言中运用一种简单而有效的方法来设计中值滤波器。我们可使用Vivado HLS [3]来获得Zynq®-7000 All Pro-grammableSoC的FPGA架构的实时性能 [4]。
下面的内容里,我们假设图像格式是每像素8位,每行1,920像素,每帧1,080行,帧速率为60Hz,因此最小像素速率至少为124MHz。不过,为了设置一些设计难度,我将要求Vivado HLS工具提供200MHz的目标时钟频率,如果得到比124MHz更大的频率值效果会更好(由于实际视频信号中还包含空白数据,因此时钟速率比活动像素所要求的速率高)。
什么是排序网络?
排序是指将阵列中的元素按照升序或降序的方式重新进行排列的过程。排序是很多嵌入式计算系统中最重要的操作之一。
由于排序在众多应用中起到关键作用,因此很多科学文献中的大量文章都对众所周知的排序方法的复杂性和速度进行了分析,例如冒泡排序、希尔排序、归并排序和快速排序。对于大数据集来说快速排序是速度最快的排序算法 [5],而冒泡排序是最简单的。通常,所有这些技术都应该以软件任务的形式在RISC CPU上运行,而且每次只执行一个对比。它们的工作负载不是恒定的,而是取决于有多少输入数据已部分排序。例如,需要对一套N个样本进行排序,假设快速排序的计算复杂性在最差、一般和最好的情况下分别是N2、NlogN和NlogN。同时,冒泡排序的复杂性分别是N2、N2和N。不得不承认我还尚未发现关于此类复杂性数字的统一观点。但在我读过的有关此问题的所有文章中似乎都赞同一个观点,那就是计算某种排序算法的复杂性并不简单。这本身似乎成为了寻找备选方案的主要原因。
在进行图像处理时,我们需要在排序方法上获得确定的行为,以便以恒定的吞吐量产生输出图片。因此,上述算法都无法成为采用Vivado HLS的FPGA设计的理想备选方案。
排序网络可通过使用并列执行实现更快的运行速度。排序网络的基础构成模块是比较器。比较器是一种简单组件,能对a和b两个数据进行排序,然后将最大值和最小值分别输出到顶部和底部输出结果中,必要时还可进行交换。排序网络对于经典排序算法的优势在于比较器的数量在给定输入数量下是固定的。因此,排序网络在FPGA硬件中易于实现。图3举例说明了一个针对五个样本的排序网络(采用赛灵思System Generator生成[6])。需要注意到的是处理延迟正好是五个时钟周期,且与输入样本数值无关。此外还应注意到右侧的五个并行输出信号包含排序后的数据,其中最大值在顶部,最小值在底部。

在C语言中通过排序网络实现中值滤波器是很简单的,如图4中的代码所示。Vivado HLS指令被嵌入到C语言代码自身内(#pragma HLS)。Vivado HLS只需要两个优化指令即可生成最佳RTL代码。首先是利用1的初始间隔 (II)将整个函数流水线化,使输出像素速率等于FPGA时钟速率。第二步优化是将像素窗口重新划分为单独的寄存器,以便同步并行访问所有数据,从而提高带宽。

顶层函数
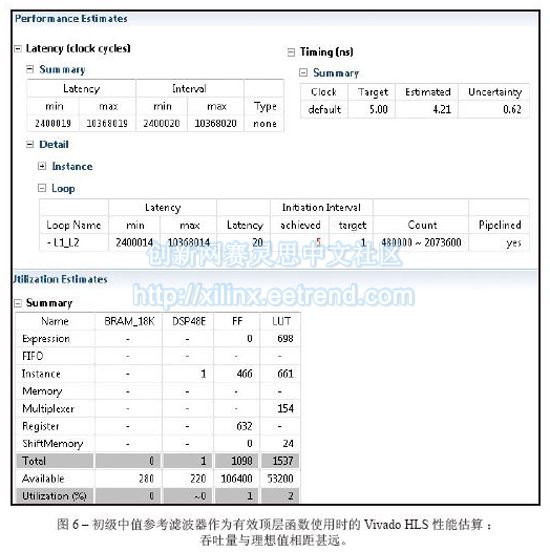
图5中的代码段是中值滤波器的初级实现,我们将其作为参考。最里面的回路已进行流水线化处理,以便在任何时钟周期内都能生成一个输出像素。为了生成延迟估计报告,我们需要利用TRIPCOUNT指令通知Vivado HLS编译器有关回路L1和L2中可能出现的迭代次数,因为它们是“不受控”的。也就是说,假设该设计可在运行期间处理低于最大允许分辨率为1,920 x 1,080像素的图像分辨率,这些环路的极限值就是图片的高度和宽度,而这两个值在编译期间都是未知的。

在C语言代码中,待滤波的像素窗口可访问图像中不同的行。因此,利用存储器位置来降低存储带宽需求的优势比较有限。尽管Vivado HLS可对代码进行综合,但吞吐量并未达到最优值,如图6所示。回路L1_L2的初始化间隔(最里面回路L2完全展开的结果,由HLS编译器自动执行)为五个时钟周期,而非一个,因此得到的输出数据速率无法支持实时性能。从整个函数的最大延迟中也能明确这一点。在一个5纳秒的目标时钟周期中,用来计算输出图像的周期数量为10,368,020,这意味着帧速率为19.2Hz而非60Hz。正如参考文献[7]中详细描述的,Vivado HLS设计人员必须明确地将视频线路缓冲器的行为代码写入用于生成RTL的C语言模型中,因为HLS工具无法自动将新存储器插到用户代码中。
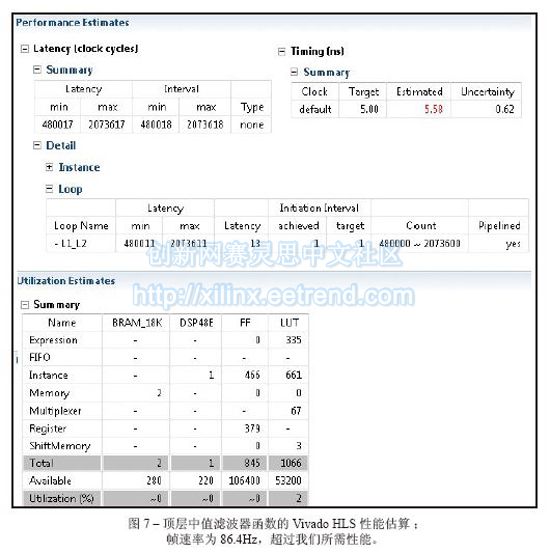
全新的顶层函数C语言代码如图8所示。由于当前的像素坐标(行,列)显示为in_pix[r][c],因此需在坐标(r-1, c-1)中的待滤波输出像素周围创建一个滑动窗口。对于3x3大小的窗口,其结果是out_pix[r-1][c-1]。需要注意到的是当窗口尺寸为5x5或7x7的时候,输出像素坐标分别为(r-2, c-2)和(r-3, c-3)。静态阵列线路_缓冲器可存储KMED视频线路数量等同于中值滤波器中垂直样本的数量(当前情况下的数量为3个);而且由于静态C语言关键字的原因,Vivado HLS编译器可自动将内容映射到FPGA双端口Block RAM (BRAM)元件中。

这样仅需很少的HLS指令就可实现实时性能。需对最里面的回路L2进行流水线化处理,以便在任何时钟周期内都能生成一个输出像素。输入与输出图像阵列in_pix和out_pix被映射为RTL中的FIFO流接口。将该线路_缓冲器阵列划分成多个KMED独立阵列,以便Vivado HLS编译器将每个阵列映射到独立的双端口BRAM中。由于这样会有更多的可用端口,从而增加了载入/存储操作次数(每个双端口BRAM在每个周期内能完成两次载入或存储操作)。图7是Vivado HLS性能估算报告。目前,最大延迟为2,073,618个时钟周期。在5.58ns的估计时钟周期下,我们可以获得86.4Hz的帧速率。这已超越了我们的需求值!回路L1_L2正如我们所希望的那样得到II=1。应注意到的是需要两个BRAM以存放KMED线路缓冲存储器。
利用高层次综合进行架构探索
在我看来,Vivado HLS的最佳特性之一是能够通过改变工具的优化指令或C语言代码本身这样的方式来探索不同设计架构并对性能进行权衡,从而实现富有创造性的设计自由度。两种操作方式都非常简单而且并不耗时。
如果需要更大的中值滤波器窗口该怎么做?例如需要5x5而不是3x3的窗口尺寸。我们只需将KMED在C语言代码中的定义从“3”变为“5”,并再次运行Vivado HLS即可。图9是单独在3x3、5x5和7x7三种窗口尺寸情况下对中值滤波器例程进行综合所得到的HLS对比报告。在所有三种情况下,例程已完全流水线化 (II=1),并且满足目标时钟周期;延迟分别为9、25和49个时钟周期,与人们对于排序网络的预期表现相符。显然,由于待排序的数据总量从9增至25甚至达到49,因此所使用的资源(触发器和查找表)也相应增加。
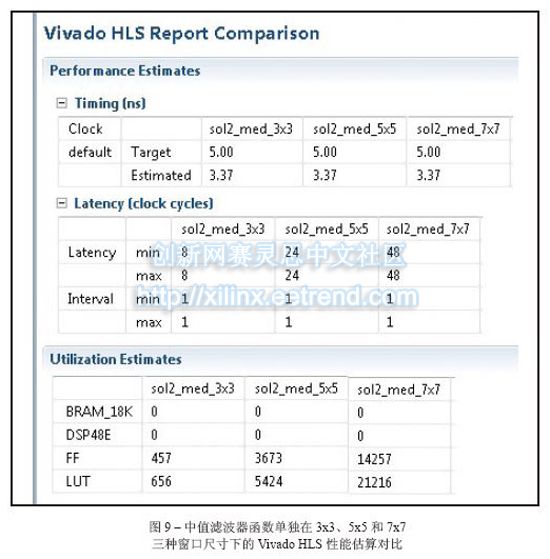
由于独立函数已完全流水线化,因此顶层函数的延迟保持恒定,同时当增大窗口尺寸的时候时钟频率会略有减小。到目前为止我们只讨论了将Zynq-7000 All Programmable SoC作为目标器件的这种情况,但采用Vivado HLS时我们可在相同项目中轻松尝试不同目标器件。例如,如果我们选用Kintex®-7 325T并对相同的3x3中值滤波器设计进行综合,所用的布局布线资源包括两个BRAM、一个DSP48E、1,323个触发器和705个查找表(LUT),时钟和数据速率为403MHz;而使用ZynqSoC器件时,则需使用两个BRAM、一个DSP48E、751个触发器和653个查找表,时钟和数据速率为205MHz。
最后,如果我们想查看3x3中值滤波器处理每样本为11位(而非8位)灰色图像时的资源使用情况,我们可通过应用ap_int C++类型来改变pix_t数据类型的定义,这样就可规定任意位宽的定点数。我们只需通过启动C语言预处理符号GRAY11就可重新编译该项目。在这种情况下,ZynqSoC上的资源使用估算量为四个BRAM、一个DSP48E、1,156个触发器和1,407个查找表。图10给出了最后两种情况的综合估算报告。

短短数个工作日
此外,我们还可以看到,对于具有不同窗口尺寸甚至不同位数/像素的中值滤波器,生成时序和面积估算值到底有多简单。尤其是在使用3x3 (或5x5)中值滤波器的情况下,由Vivado HLS自动生成的RTL只在ZynqSoC器件上占用很小面积(-1速度级),布局布线完成后,FPGA时钟频率为206(5x5版本为188)MHz,有效数据速率为206(或188)MSPS。
得到这些结果所需的总设计时间仅为五个工作日。其中大部分时间都用于构建MATLAB®和C模型,而非运行Vivado HLS工具本身;后者所需时间不足两个工作日。