【语义分割】Hierarchical Multi-Scale Attention for Semantic Segmentation
论文地址:https://arxiv.org/abs/2005.10821v1
摘要
多尺度推理通常用于改善语义分割的结果。 多个图像比例通过网络传递,然后将结果与平均或最大池合并。 在这项工作中,我们提出了一种基于注意力的方法来组合多尺度预测。我们表明,在一定尺度上的预测更适合解决特定的故障模式,并且网络学会在此类情况下倾向于使用这些尺度以生成更好的预测 。 我们的注意力机制是分层的,因此与其他最近的方法相比,其训练内存效率大约高4倍。 除了可以进行更快的训练外,这还使我们可以使用更大的农作物进行训练,从而提高了模型的准确性。 我们在两个数据集上演示了该方法的结果:城市景观和Mapillary Vistas。 对于包含大量弱标记图像的Cityscapes,我们还利用自动标记来提高泛化性。 使用我们的方法,可以在Mapillary(61.1 IOU val)和Cityscapes(85.1 IOUtest)中获得最新的最新结果。
1 介绍
语义分割的任务是将图像中的所有像素标记为属于N类之一。 在这项任务中有一个折衷,就是某些类型的预测最好在较低的推理分辨率下处理,而其他任务最好在较高的推理分辨率下处理。 精细的细节(例如物体的边缘或薄的结构)通常可以通过放大图像尺寸来更好地预测。 同时,对于较大结构的预测(需要更多的全局上下文),在缩小图像尺寸时通常会做得更好,因为网络的接收场可以观察到更多必要的上下文。 我们将后一个问题称为类混淆。 图1给出了这两种情况的示例。

使用多尺度推理是解决这种折衷的常用方法。 预测在一定范围内进行,并将结果与平均或最大合并合并。 使用平均值组合多个尺度通常可以改善结果,但是会遇到将最佳预测与较差预测相结合的问题。 例如,如果对于给定的像素,最佳预测来自2倍标度,而更差的预测来自0.5倍标度,则平均将合并这些预测,从而导致输出低于标准值。 另一方面,最大池化(Max-pooling)仅选择N个标度中的一个用于给定像素,而最佳答案可能是跨不同标度的预测的加权组合。
为解决此问题,我们采用一种关注机制来预测如何 与Chen等[1]提出的方法类似,在像素级别将多尺度预测结合在一起 。 我们提出了一种分级注意机制,网络可以通过该机制学习预测相邻尺度之间的相对权重。 在我们的方法中,由于它具有等级性质,我们只需要用一个额外的比例尺扩展训练流水线,而其他方法,例如[1],则需要在训练阶段显式地添加每个额外的推论比例尺。 例如,当用于多尺度评估的目标推理尺度为{0.5、1.0和2.0}时,其他注意方法要求首先使用所有这些尺度对网络进行训练,从而导致4.25倍(![]() )的额外训练成本。 我们的方法只需要在训练期间增加一个额外的0.5倍刻度,这只会增加0.25倍(
)的额外训练成本。 我们的方法只需要在训练期间增加一个额外的0.5倍刻度,这只会增加0.25倍(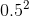 )的成本。 此外,与先前提出的方法(仅限于在推理过程中仅使用训练尺度)相比,我们提出的分层机制还提供了在推理时选择额外尺度的灵活性。
)的成本。 此外,与先前提出的方法(仅限于在推理过程中仅使用训练尺度)相比,我们提出的分层机制还提供了在推理时选择额外尺度的灵活性。
要在Cityscapes中获得最新结果,我们还采用了 粗糙图像的自动标注策略,以增加数据集的方差,从而提高泛化能力。 我们的策略是由多个近期工作推动的,包括[2,3,4]。 与典型的软标签策略相反,我们采用硬标签来管理标签存储大小,这有助于通过降低磁盘IO成本来提高训练吞吐量。
1.1 贡献
-
一种有效的分层多尺度注意机制,通过允许网络学习如何最佳地组合来自多个推理尺度的预测,从而有助于类混淆和精细细节。
-
基于硬阈值的自动标记策略,可利用未标记图像并提高IOU。
-
我们在Cityscapes(85.1 IOU)和Mapillary Vistas(61.1 IOU)中取得了最先进的结果。
2 相关工作
多尺度上下文方法。最先进的语义分割网络使用输出步长较低的网络干线。 这使网络能够更好地解析细节,但也具有缩小接收场的效果。 接受域的减少会导致网络难以预测场景中的大型对象。金字塔池可以通过组合多尺度上下文来抵消收缩的接受域。 PSPNet [5]使用空间金字塔池化模块,该模块使用一系列池化和卷积操作,使用从网络干线的最后一层获得的特征,在多个尺度上组合特征。 DeepLab [6]使用Atrous空间金字塔池(ASPP),该空间采用具有不同膨胀级别的atrous卷积,因此创建了比PSPNet更密集的功能。 最近,ZigZagNet [7]和ACNet [8]利用中间功能,而不仅仅是网络主干最后一层的功能来创建多尺度上下文。
关系上下文方法。在实践中,金字塔池技术涉及固定的,方形的上下文区域,因为通常以对称方式使用合并和扩展。 此外,这样的技术往往是静态的而不是学习的。 但是,关系上下文方法通过关注像素之间的关系来构建上下文,并且不限于正方形区域。 关系上下文方法的学习性质允许基于图像合成来构建上下文。 此类技术可以为非方形语义区域(例如,长火车或高高的细灯柱)建立更合适的上下文。 OCRNet [9],DANET [10],CFNet [11],OCNet [12]和其他相关工作[13、14、15、16、17、18、19、20]使用这种关系来构建更好的上下文。
多尺度推理。关系和多尺度上下文方法[21,22,23,9]都使用多尺度评估来获得最佳结果。 有两种常见的方法可以在多个规模上组合网络预测:平均池和最大池,平均池更为常见。 但是,平均池化涉及对来自不同规模的输出进行均等加权,这可能是次优的。 为了解决这个问题[1,24],请注意组合使用多个量表。 Chen等[1]使用神经网络的最终特征同时训练所有规模的注意力头部。 而陈等。 等 使用来自特定层的注意力,Yang等。 等 [24]使用来自不同网络层的功能组合来构建更好的上下文信息。 但是,上述两种方法都有一个特点,即网络和注意力集中在固定比例尺上。 在运行时只能使用那些规模,否则必须对网络进行重新培训。 我们提出了一种基于层次的注意力机制,该机制与推理时间内的量表无关。 此外,我们表明,我们提出的层次化注意力机制不仅可以提高平均池的性能,还可以使我们从诊断上可视化类别和场景的不同比例的重要性。 此外,我们的方法与诸如[22,25,26,9,27,10,28]之类的其他注意力金字塔池化方法正交,因为这些方法使用单比例尺图像并执行注意力以更好地组合多级特征以生成高分辨率 预测。
自动标记。特别是针对Cityscapes的最新语义分割工作,已按原样利用了约20,000个粗标签图像来训练最新模型[12,29]。 然而,由于标签的粗糙性,大量的每个粗糙图像未被标记。 为了在Cityscapes上获得最先进的结果,我们采取了自动标记策略,该策略受Xie等人的启发。 等 [2],语义分段中的其他半监督自我训练[30,31,32,33,34],以及基于伪标签的其他方法,例如[4,35,36,3]。 我们为Cityscapes中的粗糙图像生成了标签。 我们生成的标签几乎没有未标记区域,因此可以利用粗糙图像的全部内容。
尽管大多数图像分类自动标签工作都使用连续或软标签,但为了生成存储效率和训练速度,我们会生成阈值限制的标签。 使用软标签时,教师网络为图像的每个像素提供N个类别中的每个类别的连续概率,而对于硬标签,阈值用于选择每个像素中的单个顶级类别。类似于[37,4],我们生成硬密度 粗略城市景观图像的标签。 示例如图4所示。 等。 等 [2],我们不对标签进行迭代优化。 相反,我们使用默认的粗略和精细标记提供的图像对教师模型进行一次完整训练的迭代。 经过这次联合训练,我们对粗图像执行自动标记,然后将其替换在我们的教师训练食谱中,以获取最新的测试结果。 结合使用伪生成的硬标签和建议的层次注意,我们可以在Cityscapes上获得最新的结果。
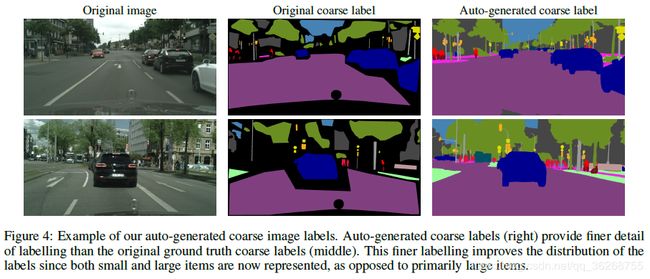
3 分层多尺度注意力
我们的注意力机制在概念上与[1]非常相似,其中针对每个比例学习一个密集的遮罩,并且通过在遮罩之间执行逐像素相乘的组合来组合这些多尺度预测,然后在不同的像素之间进行逐像素求和 缩放以获取最终结果,请参见图2。我们将Chen的方法称为“显式”。 使用我们的分层方法,我们无需学习每个固定比例尺的所有注意框,而是学习相邻比例尺之间的相对注意框。 训练网络时,我们仅与相邻的比例尺对一起训练。 如图2所示,给定一组来自单个(较低)比例尺的图像特征,我们以像素为单位预测了两个图像比例尺之间的相对关注度。 在实践中,要获取一对缩放图像,我们可以获取一个输入图像并将其按比例缩小2倍,这样我们就可以得到1倍的缩放输入和0.5倍的缩放输入,尽管任何缩小比例都可以 被选中。 重要的是要注意,网络输入本身是原始训练图像的缩放版本,因为我们在训练时会使用图像缩放增强。 这允许网络网络学习预测一系列图像比例的相对关注度。 在进行推论时,我们可以在如图所示并由以下等式描述的一系列计算中,将学习到的注意力分层地应用到N个预测尺度之间。 我们将小比例尺放在首位,并逐步发展到更高的比例尺,因为它们具有更大的全局范围,可以选择需要通过更高的比例尺预测优化的地方。
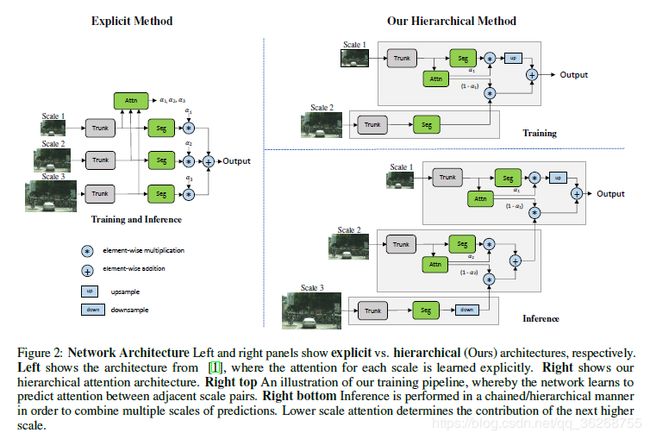
更正式地讲,在训练过程中,给定的输入图像通过factorrwherer =缩放。 0.5表示2的下采样乘数,r = 2.0表示2的下采样乘数,r = 1表示无操作。 对于我们的训练,我们选择= 0.5和1.0 = 1.0。 然后通过共享网络干线发送两个图像,其中r = 1和rr = 0.5,这会产生语义logitsL以及每个刻度的注意掩码(α),用于将刻度之间的logits组合在一起。因此,对于两个刻度进行训练和推断,使用 双线性上采样操作,*和+分别是逐像素乘法和加法,该方程式可形式化为:
![]()
使用我们提出的策略有两个优点:
•推断时,我们现在可以灵活地选择尺度,因此,通过我们提出的注意力机制链以分层方式,可以将新的尺度(例如0.25x或2.0x)添加到以0.5x和1.0x训练的模型中。 这不同于以前提出的方法,该方法仅限于使用模型训练期间使用的相同比例。
•与显式方法相比,这种分层结构使我们可以提高训练效率。使用显式方法,如果使用标度0.5、1.0 ,2.0,相对于单规模培训,培训成本为0.52+ 1.02+ 2.02 = 5.25。 使用我们的分层方法,培训成本仅为0.52+ 1.02 = 1.25。
3.1 结构
骨干:对于本节中的消融研究,我们将ResNet-50 [38](输出步长配置为8)用作网络的干线。 为了获得最先进的结果,我们使用了更大,功能更强大的主干HRNet-OCR [9]。
语义头:语义预测是由专用的全卷积头执行的,该头由(3x3 conv)→(BN)→( ReLU)→(3x3转换)→(BN)→(ReLU)→(1x1转换)。 最终卷积输出num_classeschannels.Attention Head:注意预测是使用结构上与语义头相同的单独的head进行的,除了最终卷积输出(其输出单个通道)。 当将ResNet-50用作主干时,这些语义和注意头将获得ResNet-50最后阶段的功能。 使用HRNet-OCR时,这些语义和注意头会从OCR块中获取功能。
辅助语义头:使用HRNet-OCR,还存在一个辅助语义头,它在OCR之前直接从HRNet干线中获取其功能。 该磁头由(1x1转换)→(BN)→(ReLU)→(1x1转换)组成。 在注意语义对数之后,通过双线性上采样将预测上采样到目标图像大小。
3.2 分析
为了评估我们的多尺度注意力方法的有效性,我们使用DeepLab V3 +体系结构和ResNet50干线来训练网络。 在表1中,我们表明,与基线平均方法(49.4)或显式方法(51.4)相比,我们的分层注意力方法具有更高的准确性(51.6)。 当添加0.25x比例尺时,我们的方法也观察到明显更好的结果。与显式方法不同,当使用额外的0.25x比例尺时,我们的方法不需要重新训练网络。 推理时的这种灵活性是我们方法的主要优势。 我们可以训练一次,但是可以在一系列不同的尺度上灵活地进行评估。
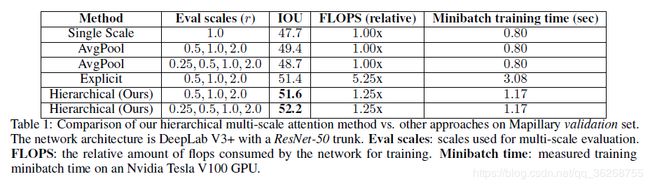
此外,我们还观察到,使用基线平均多尺度方法,简单地添加0.25x尺度会对准确性产生不利影响,因为它会导致IOU降低0.7,而对于我们的方法 ,再加上0.6IOU,即可额外获得0.25倍的比例提升精度。 使用基线平均法,0.25倍的预测值是如此之粗,以至于按其他比例进行平均时,我们会观察到车道标记,人孔,电话亭,路灯,交通灯和交通标志(前后)等类别, 自行车架下降了1.5IOU。 预测的粗糙性会损害边缘和精细的细节。 但是,使用我们提出的注意力方法,增加0.25倍标度会使我们的结果提高0.6倍,因为我们的网络能够以最合适的方式应用0.25倍预测,而不会在边缘使用它。 可以在图3中观察到这样的示例,其中对于左侧图像中的精细帖子,只有0.5x的预测会涉及到很少的帖子,但是在2.0x尺度中会出现非常强烈的注意力信号。 相反,对于右侧非常大的区域,注意力机制将学会最大程度地利用较低的比例(0.5x)和很少的错误2.0x预测。
 图3:在两个不同场景下,每个尺度的语义和注意力预测。 左边的场景说明了一个精细的细节问题,而右边的场景说明了一个大区域分割问题。 留白为白色表示较高的值(接近1.0)。 给定像素在所有比例上的注意力值总和为1.0左:路边的薄路柱最好以2倍的比例解析,并且该注意比其他比例成功地吸引了更多关注该比例的人 右图:在2倍关注度图像中,右图:以0.5倍尺度预测的大道路/分隔区域是最好的,并且注意力确实成功地集中在该区域的0.5倍尺度上。6
图3:在两个不同场景下,每个尺度的语义和注意力预测。 左边的场景说明了一个精细的细节问题,而右边的场景说明了一个大区域分割问题。 留白为白色表示较高的值(接近1.0)。 给定像素在所有比例上的注意力值总和为1.0左:路边的薄路柱最好以2倍的比例解析,并且该注意比其他比例成功地吸引了更多关注该比例的人 右图:在2倍关注度图像中,右图:以0.5倍尺度预测的大道路/分隔区域是最好的,并且注意力确实成功地集中在该区域的0.5倍尺度上。6
3.2.1 单尺度与双尺度特征
虽然我们确定的体系结构仅从两个相邻图像比例尺中较低的比例产生特征来吸引注意头(请参见图2),但我们尝试了用两个相邻范围的特征来训练关注头。 我们没有观察到准确性上的显着差异,因此我们只考虑了一组特征。
4 在城市景观上自动标记
受近期针对图像分类任务[2]和[39]的自动标签工作的启发,我们为“城市景观”采用了自动标签策略,以提高有效数据集的大小和标签质量。 在“城市景观”中,有20,000个带有粗标签的图像与3500个带有细标签的图像。 粗糙图像的标签质量非常适中,并且包含大量未标记的像素,请参见图4。通过使用我们的自动标签方法,我们可以改善标签质量,从而有助于对IOU进行建模。
图像分类中的标签是使用软的或连续的标签,从而教师网络为每个图像的每个像素为N个类中的每一个提供目标(软)概率。 这种方法的挑战是磁盘空间和训练速度:存储标签大约需要3.2TB磁盘空间:20000张图像* 2048w * 1024h * 19类* 4B = 3.2TB。 即使我们选择存储此类标签,在训练过程中读取如此大量的标签也可能会大大减慢训练速度。
相反,我们采用了硬标签策略,即对于给定的像素,我们选择了教师网络的顶级预测。 我们根据教师网络的输出概率来确定标签的阈值。 超出阈值的教师预测将成为真实的标签,否则像素将被标记为信号等级。 在实践中,我们使用0.9的阈值。
5 结果
5.1 实施协议
在本节中,我们将详细描述我们的实现协议。
训练细节。我们的模型在Nvidia DGX服务器上使用Pytorch [40]进行训练,每个节点包含8个GPU,混合精度,分布式数据并行训练和同步批处理归一化。 我们为优化器使用随机梯度下降(SGD),在训练中每GPU的批量大小为1,动量为0.9,权重衰减为5e−4。我们采用“多项式”学习率策略[41]。 在默认设置下,我们使用RMI [42]作为主要损失函数,而对辅助损失函数使用交叉熵。 对于Cityscapes,我们使用2.0的乘方指数,0.01的初始学习率,并在2DGX节点上训练175个时期。 对于Mapillary,我们使用1.0的多边形指数,0.02的初始学习率,并在4个DGX节点上训练200个时期。 与[29]中一样,我们在数据加载器中使用类均匀采样从每个类中均等地采样,这有助于在数据分布不均等时改善结果。
数据增强。我们采用高斯模糊,颜色增强,随机水平翻转和随机缩放(0.5 x -2.0x)以扩大数据集的训练过程。 对于Cityscape,我们使用2048x1024的作物,对于Mapillary,我们使用1856x1024的作物。
5.1.1 Cityscapes结果
Cityscapes [43]是一个大型数据集,它在5000张高分辨率图像中标记了19个语义类别。 对于Cityscapes,我们将HRNet-OCR与建议的多尺度注意力方法一起使用。 我们将RMI用作主要分割头的损失,但对于辅助分割头,我们使用交叉熵,因为我们发现使用RMI损失会导致训练深度的训练准确性降低。 首先在较大的Mapillary数据集上进行预训练,然后在Cityscapes上进行训练,即可达到最佳效果。 对于Mapillary的预训练任务,我们不会专心训练。 除了自动标记的粗图像之外,我们还使用火车+瓦尔图像实现了有关Cityscapes的最新配方。 以50%的概率从Train + val集合中采样,否则从自动标记的图像池中采样。 在推断时,我们使用比例= {0.5,1.0,2.0}和图像翻转。
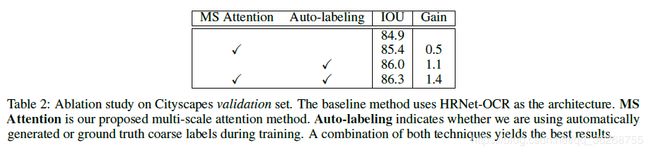
我们对Cityscapes验证集进行了消融研究,如表2所示。在平均HRNet-OCR架构上,多尺度关注产生0.5%的IOU 汇集。 自动标记可将基线的IOU提高1.1%。 将这两种技术结合在一起,总共可获得1.4%IOU的收益。
最后,在表3中,我们显示了与Cityscapes测试集中其他性能最高的方法相比的方法结果。 我们的方法得分为85.1,这是所有方法中报告的最佳Cityscapes测试得分,比以前的最佳得分高了0.6IOU。 此外,我们的方法在除三个班级以外的所有班级中均拥有最高的每班分数。 结果如图5所示。

 图5 定性结果。 从左到右:输入,基本事实,我们在Cityscapes上的方法
图5 定性结果。 从左到右:输入,基本事实,我们在Cityscapes上的方法
5.1.2 Mapillary Vistas结果
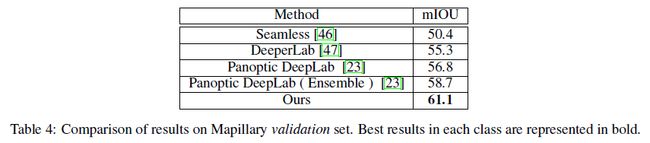
Mapillary Vistas [45]是一个大型数据集,包含25,000张高分辨率图像,被注释为66个对象类别。对于Mapillary,我们使用HRNet-OCR作为主干以及我们提出的多尺度注意力方法。 因为枫木图像可以具有非常高的分辨率,所以我们调整图像的大小,使长边为2177,如[23]中的wasdone。 我们使用ImageNet分类训练的HRNet权重来初始化模型的HRNet部分。由于Mapillary中66个类的内存需求更大,我们将作物大小减小到1856 x 1024.在表4中,我们显示了方法的结果 枫叶验证集。 我们基于单模型的方法达到61.1,比下一个最接近的方法Panoptic Deeplab [23]高2.4,后者使用模型集成来达到58.7。
6 结论
在这项工作中,我们提出了一种用于语义分割的分层多尺度注意方法。 我们的方法在提高分割精度的同时,还提高了内存和计算效率,这都是实际需要考虑的问题。 训练效率限制了可以完成快速研究的速度,而GPU内存效率则限制了可以训练的作物网络的规模,这也可能限制网络精度。 使用我们提出的方法,我们在经验上证明了Cityscapes和Mapillary的持续改进。