欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld。
技术交流QQ群:433250724,欢迎对算法、技术、应用感兴趣的同学加入。
前面介绍过线性回归的基本知识,线性回归因为它的简单,易用,且可以求出闭合解,被广泛地运用在各种机器学习应用中。事实上,除了单独使用,线性回归也是很多其他算法的组成部分。线性回归的缺点也是很明显的,因为线性回归是输入到输出的线性变换,拟合能力有限;另外,线性回归的目标值可以是(−∞,+∞),而有的时候,目标值的范围是[0,1](可以表示概率值),那么就不方便了。
逻辑回归可以说是最为常用的机器学习算法之一,最经典的场景就是计算广告中用于CTR预估,是很多广告系统的核心算法。
逻辑回归Logistic Regression
逻辑回归(LR),虽然叫回归,然是从目标函数来看,它是设计用来做分类的,经典的LR是用于二分类的情况的,也就是说只有0,1两类。
定义一个样本xi∈Rm的类别是1的概率为:
这就是sigmoid函数的形式,绘制出来是这样的形式:
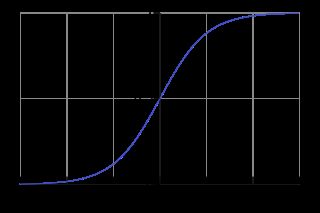 、
、
图1
可以看到,取值范围是在(0,1)的,因此近似可以理解为一个概率的取值。在神经网络模型中,sigmoid函数是一种激励函数,其他常见的还有tanh函数,以及其他一些函数。(这些激励函数后面介绍神经网络模型的时候再展开)
记sigmoid函数为
给定一个数据集S,其中有N个样本,那么可以写出目标函数:最小化负对数似然函数:
可以看到目标函数本质上是一个求和的形式,为了防止数值本身过大,一般会用平均值形式:
如何优化这个目标函数呢?采用标准的梯度下降算法,梯度下降可以参考我前面写的PRML ch5.2-5.3中关于梯度下降的部分,也可以参考一下资料[2]。
通过梯度下降,我们就可以求出w,然后带到
就可以求出属于1类的概率,只要概率大于0.5,我们就可以分类为1;当然,如果保留概率本身的数值,我们也可以认为是做了一个回归预测,只不过取值范围是(0,1)。
Softmax Regression
上面介绍的逻辑回归是针对二分类问题的,可以看下图图2,实线部分就是表示逻辑回归的model,多个输入,一个输出,
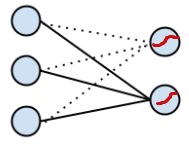
图2
如果有多类,我们可以采用多个二分类,且互相间是独立的;另外一种情况,类别之间不是独立的,而是同时在多个类中进行分类,这个时候就需要用softmax了(图2中,虚线部分又增加了一个输出,实际上逻辑回归是softmax的一个特例)。
当有k个类别时,一个样本x(i)属于第j类的概率是:
(如果j=0,1,而且w0=0,那么就是逻辑回归的形式了,只不过因为只有两类,逻辑回归就只关注类1,而不关注类0了)
模仿逻辑回归,我们可以写出似然函数:
类似的,目标函数是
于是,可以求出目标函数对于参数的梯度,对于每一个输出目标j,其参数wj的梯度是,
对于每一个wj,j=1,2,…,k,采用更新:
基本的算法到这里就可以结束了,不过如果我们再看一下下面的性质,
其中 c是一个常数向量。也就是说,如果学到的最优解 wj经过任意平移变换以后,目标函数值不变,依然是最优解。避免数值太大,可以加入一项weight decay项(也就是正则项,可以参考前面的 机器学习方法:回归(二)稀疏与正则),即目标函数是:
对应的,梯度是:
(上面的weight decay方法也可以直接用于逻辑回归,形式几乎是一样的。)
对于每一个样本、每一个类别,softmax都可以求出一个概率p(y(i)=j|x(i);w),然后概率最大的那个类别就是分类的类别。如何决定是用一个softmax Regression,还是用k个logistic Regression?一般来说可以根据类别是否mutually exclusive来决定——如果互相间有重合(或者本身在语义上并不相关,比如一张图片“是否风景照片”和“是否含有人”),那么就用k个logistic Regression;如果互相间是互斥的,那么就可以采用softmax。
前面主要讲了梯度下降来求解,实际上有非常多的优化方法可以比梯度下降做到更快更好,常见的有BFGS method,SGD,Conjugate gradient method等,具体这些方法在本文就不展开了,后面有时间分别介绍一下。
Ok,逻辑回归和softmax就介绍到这里。这两个算法也是深度学习中经常会被提到的基础算法,后面在介绍深度学习的时候,可以再回来复习下。接下来打算写一些深度学习相关的最最基础的算法。
觉得有一点点价值,就支持一下哈!花了很多时间手打公式的说~更多内容请关注Bin的专栏
参考资料
[1] http://www.cnblogs.com/daniel-D/archive/2013/05/30/3109276.html
[2] http://www.cnblogs.com/LeftNotEasy/archive/2010/12/05/mathmatic_in_machine_learning_1_regression_and_gradient_descent.html
[3] PRML, ch4 , Logistic regresssion
[4] http://deeplearning.stanford.edu/wiki/index.php/Softmax_Regression
[5] http://en.wikipedia.org/wiki/Gradient_descent