大家好,我是来自奇虎360的国浩。今天我给大家带来的是Cassandra在360的最新进展。
我会从四个方面来介绍Cassandra在360的应用情况:Cassandra在360的使用历史再结合两个案例来介绍Cassandra在360的使用场景,最后介绍360的大规模集群是怎样做到运维统一的。
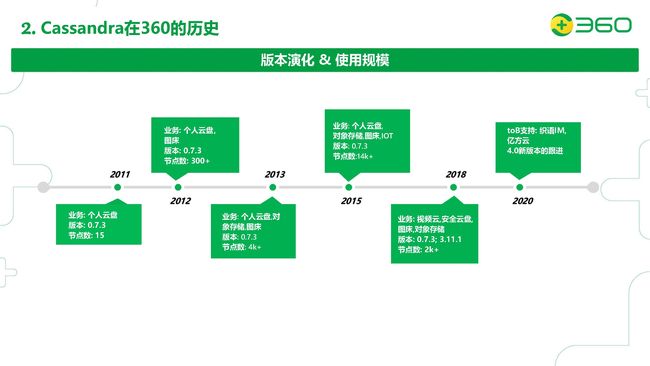
首先我先介绍Cassandra在360的使用历史。Cassandra在360已经有使用十年之多的历史了,我们在2011年就把Cassandra使用在了生产环境。
最初,我们是应用到了个人云盘的业务上,最初的版本是0.7.3的版本。最初的节点数也是比较少的,是15台。后来随着我们个人云盘业务的发展,从15台,到300台,到4000台,到2015年最高的时候14000台Cassandra节点。2015年我们公司高层决定对个人云盘业务做了私有化,不再免费提供了。这样的话我们Cassandra的节点数下降了。后来我们出于在2018年的考虑,对我们公司内所有的对象存储做了一个统一的平台,所以2018年我们又重新拾起了Cassandra,并且从最开始的0.7.3版本迁移到了3.11.1。当时0.7.3和3.11.1都是共存的。
现在我们的节点数达到了2000多台。2020年,因为公司收购了一些ToB的公司,我们打算在ToB上大力发展,对我们Cassandra的要求也是更高了。所以我们后面会以更大的力度去跟进Cassandra 4.0的一些最新的功能。后面我也会介绍我们针对Cassandra原生版本的一些改进,比如对0.7.3的一些技术上的改进,包括我们做的一些功能上的定制开发,这些也都迁移到了我们最新的版本上。

下面我会介绍我们公司把Cassandra应用与对象存储的项目里的应用情况。
首先理论上对象存储应该是没有存储上限的,实质上它就是一个拥有命名空间(bucket)的大规模键值存储,用户可以通过键值这样的一个简单的查询来存取一些数据。公司是针对Cassandra的基础上来构建这样的键值存储。目前这个存储接入的业务包括我们的视频云、360IM、安全云盘。总体的服务是达到了800个节点的规模,存储了近20PB的数据,每天增加量是300TB以上。
然后对象存储的特点是:存储量是巨大的;文件大小也是任意的;它还是一个在线的存储,所以对我们的性能和时间要求也比较高;而且它根据用户的使用情况,它是没有冷热数据的区分的,用户也可能要求取到一个很老的数据,而且我们的读写速度要求是比较高的。

因为这些特点,也给我们的系统设计带来一些挑战。
首先因为数据量非常多,它会存储海量的小文件,对于我们元信息存储的压力就会成为我们存储的瓶颈。存储的容量也是我们考量的范围之内,因为它本身有无限扩展容量的要求。针对我们公司的网络环境,我们公司同城会有多个机房,机房之间会存在一些割接的需求,在割接的情况下,我们怎么去保证数据的高可用。另外业务对这个系统的依赖性也是比较高的,对访问时延的毛刺要求比较低。
为什么我们要基于Cassandra来构建对象存储服务呢?首先我们是看中它的平行扩展的功能,并且数据能够自动平衡。它的多种数据分区策略,能解决数据热点的问题。然后它支持多数据中心的部署,防止了我们单个机房割接造成的数据中心的孤岛的一些问题。还有就是我们服务的可用性要求比较高,我们的业务也是可以接受最终一致性的;另外Cassandra的可调节一致性,以及高分区容错性,对整体的服务影响小。
针对我们服务的这些特点,我们最终选择把我们的对象存储构建在Cassandra之上。
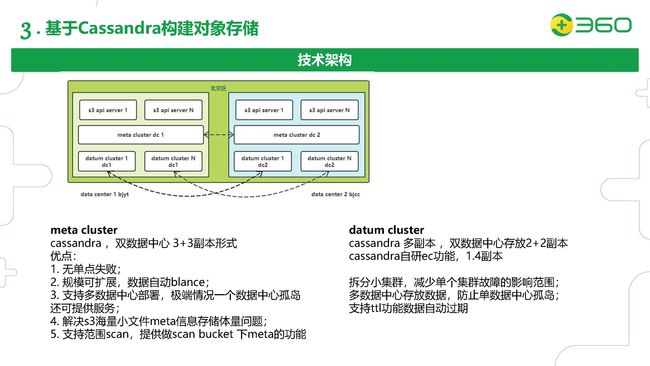
这里是我们对象存储的技术架构。从上往下应该是有三种角色,我们先从单机房的情况来看看。
首先第一层是我们的S3的接入层,也就是一个Web server,接受用户的读写请求,把数据进行切片,最终存到我们我们的数据集群(Datum Cluster)。数据切片的元信息,我们会存到第二层的元数据信息的集群(Meta Cluster)。Meta Cluster的设计我们使用了双数据中心的架构,按照一边三个副本的部署形式,主要看中了Cassandra对多数据中心部署的原生支持。
我们的Cassandra对某一个Bucket底下可以支持范围Scan的功能。这个也解决了我们海量小文件元信息存储体量的问题。我们的Datum集群也是使用了Cassandra多副本的部署形式,我们针对敏感度比较高的业务使用了多副本2+2的配置,针对要求比较低一些的业务使用了我们自研的EC(Erasure Code)纠删码的功能,可以把成本降到1.4个副本,也就是说比之前的成本下降了一半还要多。
我们后面的数据中心也拆分了多个小集群,这样可以减少单个集群故障的影响范围。因为使用多数据中心存放数据,也可以防止单数据中心孤岛问题。另外我们也看中了Cassandra的TTL功能,因为用户在上传的时候可以指定TTL,然后Cassandra会根据TTL自动清除过期的数据。
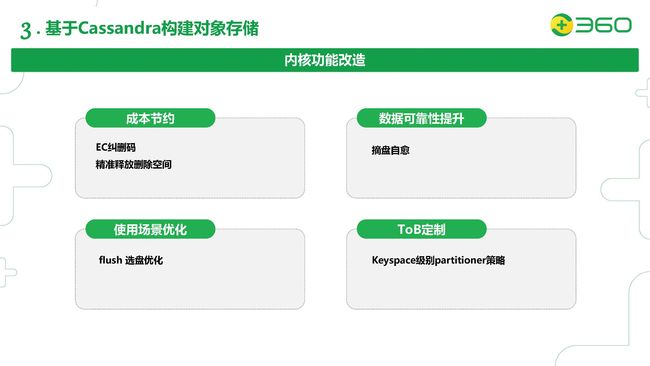
接下来,我们看一下根据我们的使用场景对Cassandra内核的二次开发,主要是这四个方面:成本节约,数据可靠性提升,使用场景优化,ToB定制。

第一个是节约我们的存储成本。
首先我们是对象存储,所以我们的存储数据量是比较多的。因为用户并不是所有的业务对我们数据访问的时延都是特别在乎的,他可能存的有一些比较老的数据,做一些归纳,所以我们希望提供的是在他能允许的范围最大可能去降低他的存储成本。所以我们引入了一个纠删码的技术,也就是从原来需要的3副本成了1.4副本(10个数据块+4个校验块),同时数据可用性也得到了一些提高:在3副本的情况下,如果有三个节点发生故障,会导致数据丢失;如果使用了我们的EC纠删码,配置了10+4的副本,只有当五个节点发生故障,才会导致数据丢失。
数据模型上的设计,键值对存储可以使用最上面看到的这一张表,也就是原始CF。使用我们的EC纠删码10+4,我们会把这个原始表隐藏,自动去创建两个关联表:第一个是Chunk信息的表,存储我们的数据分块;第二个是我们分块数据关联的表。也就是每一个数据来了以后,我们的协调者节点拿到了数据的写入请求,会根据副本的配置,把写入请求的数据做一个十块的切分,并根据十块的内容计算出来四个校验块。这十四块数据会拼上row key的数据存到Chunk表里,根据row key拼出来的信息也会存到Key Meta的表里。这样能做到数据1.4副本的分布。
在读取请求到来的时候,它根据同样的原理,当读请求到达协调者节点,根据1.4副本的配置,先在Key Meta表查到所有关联的row key,然后再在Chunk表里批量异步的通过row key读取所有的数据块,优先读数据块。如果没有成功取到所有的数据块,再去读我们的校验块,通过EC纠删码的反解码过程,把数据补齐之后再返回给客户端。

针对上面这个设计我们也需要更改我们的数据副本分布策略。
默认的副本分布策略是SimpleStrategy,也就是说三副本的情况是往环里的下面两个节点顺延来存储另外两个副本。
我们设计里的Chunk表需要采取一个新的副本分布策略,因为我们需要保证Chunk表里10+4的所有块最大限度的分布到尽可能多的节点里,所以我们新增了一个条带化的副本分布策略,如上图所示。我们的Key Meta还是使用普通的副本存储策略,因为这个元数据是非常重要的,如果它丢了,那就代表整个key下面的数据都丢掉了。所以元数据还是使用Simple的副本分布策略。
针对我们刚才提到的加入EC纠删码以后,我们需要更改我们数据读写的路径,以及加入两个新的扩展表,我们在读取的路径下做了一些修改,并且针对于它的数据修复做了一个定制化的读修复的功能。每次需要读一个key的时候,先去读取它的元信息,拿到它的所有Chunk的数据块的信息。如果所有的数据块都是健康的,我们会在协调者节点上直接把数据拼装好了以后直接发送给我们的客户端。如果发现有数据块是丢失的,我们会去读取我们的EC校验块,再加上我们原有的数据块进行一个EC的反解码,拿到最终的数据,把这部分的数据直接返回给我们的客户端。另一部分因为发现有数据缺失,我们会在系统表里(System Keyspace里我们创建了一张默认的系统表)记录我们丢失的数据块的信息。
为什么要加这张表?因为我们有数据块丢失发生的时候往往是这个数据块的节点已经挂掉了。这时如果我们把这个信息存到这样的本地表里,不管对方的节点是不是还是存活的,再由一个repair task异步的去消费这个表里的数据,如果那个节点还是挂掉的,我们这个表里的数据不会删。如果节点是健康的状态的话,相当于我们发送了写请求把这个修回来了之后,对应的我们会清除本地表的内容。这样可以做到读取过程中的读修复。
我们还针对这个EC功能加了一个异步删除的功能。也就是说我们在写入一条删除请求的时候,相当于也是写入了一条Delete的标志。所以我们在截取到Delete标志的时候,会在协调者节点读取我们的元信息,然后同步地标记删除元信息,同时也会开一个异步的线程池一点一点地标记Chunk信息的删除。下次读取的时候只要元信息已经被标记删除了,就会正常返回删除。
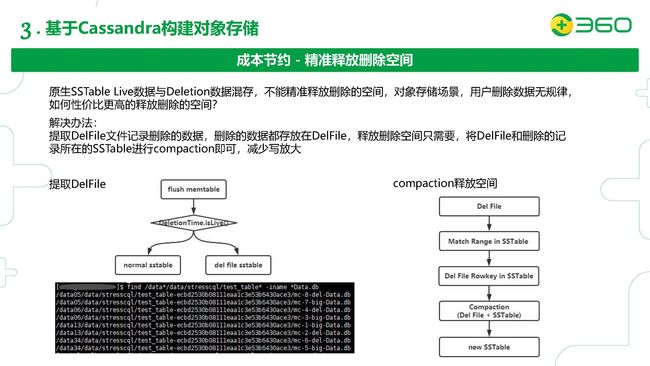
这张slide继续说明我们针对成本节约的另一个改进。
我们这种对象存储的场景,有些用户会使用删除的请求。Cassandra默认的是在SSTable层面把正常的数据和删除的数据混合的,如果我们要释放数据空间的话,需要对这些SSTable做Compaction才能真正的删除,这样并不能做到一个精准的删除。
在用户删除无规律的情况,怎样能性价比更高的精准删除,释放空间呢?我们改了Cassandra做Flush memtable的过程,在里面加了一个迭代器,对每一个row都做DeletionTime.isLive()判断。如果这个row是带删除标记的数据,就flush到delFile SSTable里;如果是普通的数据,就flush到正常的SSTable里。这样可以把带删除标记的数据和正常数据分开,在做compaction的时候就可以非常精准的释放空间。
Compaction里面是这样做的:首先我们挑一些DelFile SSTable出来,每个DelFile SSTable也会有一个StartKey以及EndKey,我们根据这个范围在正常的SSTable扫描看看有没有交集,把有交集的SSTable筛选出来。然后确认DelFile的Rowkey也在这些筛选出来的SSTable里,形成SSTable的列表,把这些SSTable和我们的DelFile做一次Compaction,这样可以精准的释放我们删除的空间,形成新的SSTable。
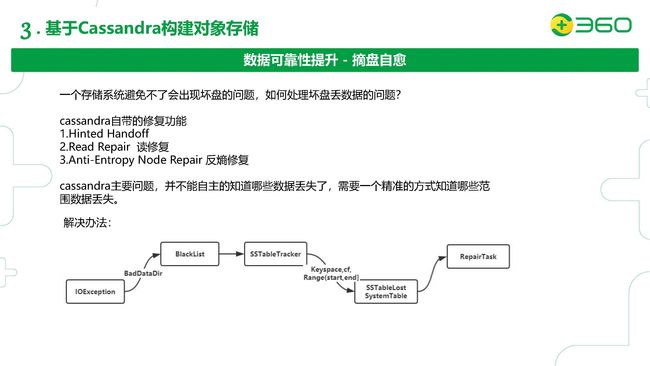
这里我们对数据的可靠性做了二次开发,也就是摘盘自愈的功能。一个存储系统避免不了出现坏盘的问题。如何处理坏盘丢数据的问题呢?
大家知道Cassandra自带有一些修复功能:Hinted Handoff, Read Repair读修复, Anti-Entropy Node Repair反熵修复。但是对于我们这样重IO的场景,反熵修复的开销也是非常大的,所以我们一般也不会去开启反熵修复。这里Cassandra的主要问题,是并不能自主的知道哪些数据丢失了,比如我们有一个坏盘,它并不知道哪些数据丢失了,它需要一个精准的方式知道哪些范围的数据丢失。Cassandra在检测到IO Exception(比如有坏盘)的时候,默认的机制是STOP,也就是进入一个对客户端和其他节点看来都是挂掉的状态。同时它会把BadDataDir加入到一个黑名单BlackList里面,这样后续和IO相关的一些操作(比如Flush memtable)就会避免这个目录。
我们在这个加入Blacklist的地方做了一些二次开发。首先我们对IOException加了一个引用的计数。比如说,我们有十块盘,如果盘1出现了十次IOException,我们会把它标记为一个不可用的状态,把它加入黑名单。然后我们会去通过一个Hook去扫SSTableTracker(这是Cassandra内部的一个数据结构,用来存储CF下面都有哪些SSTable)中属于坏盘数据目录下面的SSTable,并且把这些SSTable对应的Keyspace、CF以及token范围加到一个叫SSTableLost的系统表里。后面会有一个异步的RepairTask对这些范围做修复。
有了这个实现,就解放了我们的一些运维的压力。因为出现了坏盘以后,不用运维去特别快速的修复,因为系统有自动修复的能力。
另一个针对我们对象存储的场景优化是Flush Memtable的选盘策略。
大家如果细心观察,会发现如果你有多个数据目录,flush memtable的时候会启动很多个线程,针对每个数据目录会有数个线程(根据memtable_flush_writers的配置)。这些线程分别向所有数据目录写SSTable数据,当JBOD盘数比较多的时候,CPU占用飙高,读写时延毛刺过高,而且这样会产生很多小SSTable文件,对后续的Compaction操作带来更大压力。
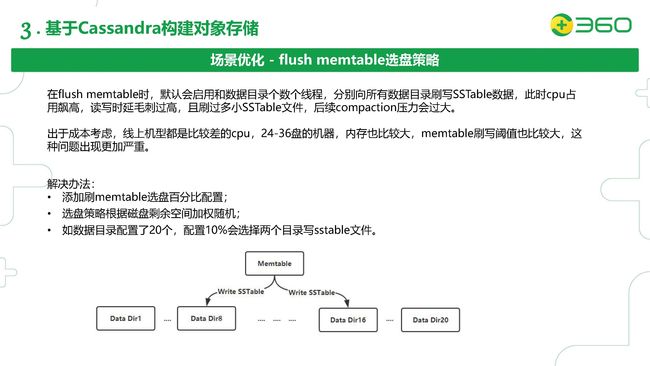
另外,出于低成本的考虑,我们对象存储线上的机型选择的都是比较差的CPU(核数较低,可能还没有盘数多),24-36盘的机器(即使memtable_flush_writers设成1,也会有24-36个flush memtable的线程),内存也比较大(这样可以让memtable flush的阈值比较大)。但是这样Flush发生的时候对CPU的影响也更大,读写时延也更容易瞬间飙高(因为可用CPU短期内都被flush memtable的线程占用了),这个对于我们的在线业务来说是不可以接受的,所以我们在这里也做了一个二次开发。
我们的解决方法是添加了一个flush memtable的选盘百分比的配置,比如有20个JBOD的盘,我们配置10%就会选择两个目录来flush SSTable。到底哪两个盘是根据选盘的策略,按照磁盘剩余空间加权来随机选择的。这里的一个好处是:在没做这个策略之前,flush SSTable是根据每个盘的token范围把需要flush的memtable拆成20份,这样会产生很多小的SSTable。加了这个阈值的话,相当于把这20份变成了两份,对后续的compaction写放大的压力小一些,而且也有效的防止了CPU的突然飙高。

这个slides是我们对象存储针对ToB场景的一些定制。
一般来说,To B场景是厂家给我们一些服务器,这些服务器上会混合部署很多的服务。有些其他的业务也会用到Cassandra,它们根据它们的row key设计或者业务模型想选择各种各样的Partitioner策略。比如有的想选择Murmur3Partitioner,有的想选择OrderPreservingPartitioner。但是Cassandra默认的一个集群只支持一种partitioner策略。
我们的解决办法是在Keyspace级别实现Partitioner策略,在Keyspace Schema信息里记录所选的Partitioner类型。每个节点保留多类型Token对应关系,在内存里通过tokenMap的数据结构来表示。然后我们做了一个映射关系,Murmur3在Cassandra内部是一个LongToken,我们通过转码把它转成byte[ ]形式。OrderPreservingPartitioner是StringToken形式,我们通过反转码可以把byte[ ]转成StringToken,在内存里存储这样的映射关系,这样Gossip消息交换无需变更内容。

刚才我们已经介绍完了对象存储业务的所有二次开发的具体情况,现在我们再来看看我们的另一个大规模应用Cassandra的业务——海量日志查询系统。
360是一家安全公司,它会产生海量的安全日志信息,需要一个实时性要求较高的日志检索系统。我们需要从这样一个分布式的海量日志系统里,快速的(在几秒的时间内)检索我们关心的数据。它主要的功能有三个部分:数据导入;索引建立/重建;查询。目前这个系统服务于我们的云查杀业务,进入了超过20个数据源,每天新增的数据达到了1500亿条日志数据,每天的数据增长量大约在17TB。

右边你可以看到我们安全日志的格式。安全日志的特点:一是数据源录入格式固定;二是数据量巨大;三是数据无冷热之分,若干年之后也可能拿出来分析,一般是基于时间段的查询;四是查询条件固定,一般使用定值查询;五是内容很少更新/重建。
我们是基于Cassandra来建立的查询系统。我们的索引信息存放在Cassandra里,原始数据存放在HDFS里。
为什么采用Cassandra?一是因为它的写入性能高,支持批量数据的快速导入;二是便于扩展,数据能自动平衡;三是创建表也比较方便。
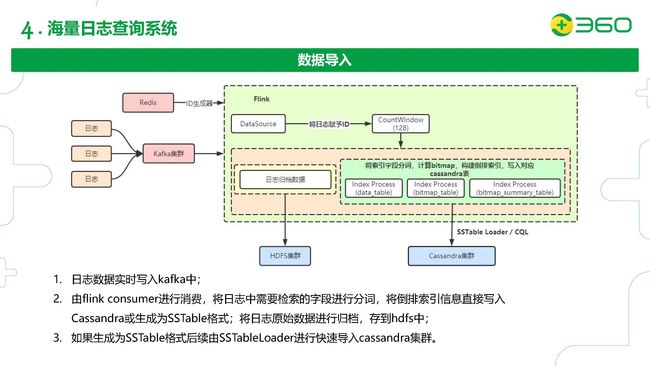
先来看看数据导入的流程。首先我们的日志数据会以流的形式打到Kafka里面,然后我们用流处理引擎Flink来做消费,通过Redis的ID生成器拿到一批ID赋予我们的日志。再然后把日志中需要索引的字段分词、计算bitmap、构建倒排索引,并直接写入到Cassandra表里或者生成SSTable;日志的原始数据归档到HDFS集群里。如果生成了SSTable则通过SSTableLoader批量导入到Cassandra集群。

再来看看数据查询的流程。
首先我们数据的查询条件是固定的,都会有一个固定的索引字段,以及索引字段对应的查询值是什么,还有查询的时间是什么范围。这里是通过RESTful API向查询引擎发起查询请求。查询引擎通过查询Cassandra中的多级索引表,得到原始数据位于日志归档文件的位置和偏移量(filepath, offset, length),然后根据这些信息,再从HDFS里获取日志数据。

最后,我们再来介绍一下我们的统一运维平台。
因为我们线上的Cassandra规模是比较大的。我们有两千多个节点,20个集群。而我们线上只有一个兼职运维。但是他的工作也不是完全管理Cassandra集群,那他是怎么做到管理这么多节点的呢?Cassandra社区现在正在推广一个叫sidecar的运维平台,这个是在4.0版本之后提出的,目前实现的功能比较少,而且我们现在使用的3.11版本不适用。但是我们借鉴了sidecar的思路实现了一套自研的统一运维平台,将一些运维的重复性操作,统一放到里面,解放了很多运维的工作。
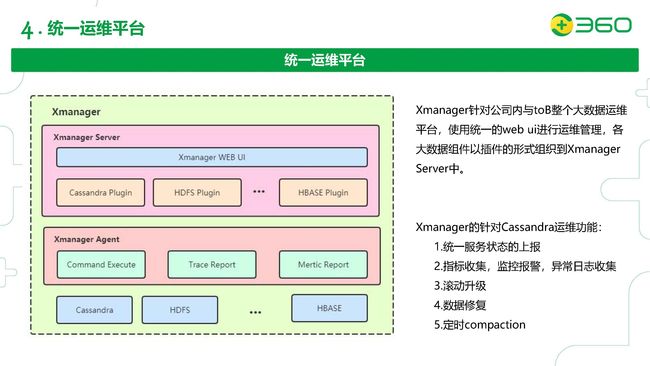
我们把这个平台在公司内部称为Xmanager。它是我们ToB整个大数据运维平台,Cassandra运维只是它里面的一部分功能。它自上到下有三个层次。首先有Xmanager Server,其中包含一个类似于Dashboard的Xmanager Web UI,底下可以装一些插件,包括Cassandra插件。Cassandra插件实现了部分功能(后期我们会有一些迭代):
- 统一的服务状态的上报
- 指标收集,监控报警,异常日志收集
- 滚动升级(包括修改参数需要的滚动重启)
- 数据修复(可视化)
- 定时compaction
我们有Xmanager Agent,抽象出了这样一些功能模块。因为Agent是部署在每个节点上,是一个独立的进程,所以我们需要Command Execute来执行命令,Trace Report来收集trace的信息,Metric Report来收集每个节点的指标,包括通过JMX接口来收集Cassandra进程里的详细指标。这样的架构可以根据不同的插件来扩展功能,来支持更多的系统,包括HDFS,HBase,等等。