知识蒸馏在文本方向上的应用
知识蒸馏在文本方向上的应用
完整项目代码在我的GitHub仓库下
虽然说做文本不像图像对gpu依赖这么高,但是当需要训练一个大模型或者拿这个模型做预测的时候,也是耗费相当多资源的,尤其是BERT出来以后,不管做什么用BERT效果都能提高,万物皆可BERT。
然而想要在线上部署应用,大公司倒还可以烧钱玩,毕竟有钱任性,小公司可玩不起,成本可能都远大于效益。这时候,模型压缩的重要性就体现出来了,如果一个小模型能够替代大模型,而这个小模型的效果又和大模型差不多,何乐而不为。
文章目录
- 知识蒸馏在文本方向上的应用
- 知识蒸馏介绍
- 模型结构
- 模型实现
- 代码结构
- 学生模型输入
- 学生模型结构
- 教师模型结构
- 损失函数
- 模型效果
- TNEWS测试效果
- 已知问题
- 参考链接
知识蒸馏介绍
在讲知识蒸馏时一定会提到的Geoffrey Hinton开山之作Distilling the Knowledge in a Neural Network当然也是在图像中开的山,下面简单做一个介绍。
知识蒸馏使用的是Teacher—Student模型,其中teacher是“知识”的输出者,student是“知识”的接受者。知识蒸馏的过程分为2个阶段:
1.原始模型训练: 训练"Teacher模型", 它的特点是模型相对复杂,可以由多个分别训练的模型集成而成。
2.精简模型训练: 训练"Student模型", 它是参数量较小、模型结构相对简单的单模型。
模型结构
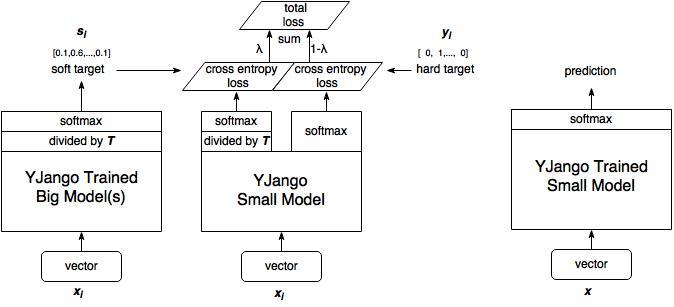
借用YJango大佬的图,这里我简单解释一下我们怎么构建这个模型
1.训练大模型
首先我们先对大模型进行训练,得到训练参数保存,这一步在上图中并未体现,上图最左部分是使用第一步训练大模型得到的参数。
2. 计算大模型输出
训练完大模型之后,我们将计算soft target,不直接计算output的softmax,这一步进行了一个divided by T蒸馏操作。(注:这时候的输入数据可以与训练大模型时的输入不一致,但需要保证与训练小模型时的输入一致)
3. 训练小模型
小模型的训练包含两部分。
-soft target loss
-hard target loss
通过调节λ的大小来调整两部分损失函数的权重。
5. 小模型预测
预测就没什么不同了,按常规方式进行预测。
模型实现
模型基本上是对论文Distilling Task-Specific Knowledge from BERT into Simple Neural Networks的复现,下面介绍部分代码实现
代码结构
Teacher模型:BERT模型
Student模型:一层的biLSTM
LOSS函数:交叉熵 、MSE LOSS
知识函数:用最后一层的softmax前的logits作为知识表示
学生模型输入
Student模型的输入句向量由句中每一个词向量求和取平均得到,词向量为预训练好的300维中文向量,训练数据集为Wikipedia_zh中文维基百科。
w2v_model = gensim.models.KeyedVectors.load_word2vec_format('sgns.wiki.word')
# 生成句向量
def build_sentence_vector(sentence,w2v_model):
sen_vec = [0]*300
count = 0
for word in sentence:
try:
sen_vec += w2v_model[word]
count += 1
except KeyError:
continue
if count != 0:
sen_vec /= count
return sen_vec
学生模型结构
学生模型为单层biLSTM,再接一层全连接。
class biLSTM(nn.Module):
def __init__(self):
super(biLSTM, self).__init__()
self.lstm = nn.LSTM(input_size=300, hidden_size=256,
num_layers=1, batch_first=True, dropout=0, bidirectional= True)
self.fc1 = nn.Linear(512, 128)
self.fc2 = nn.Linear(128, 2)
def forward(self, x, hidden=None):
lstm_out, hidden = self.lstm(x, hidden)
out = self.fc1(lstm_out)
activated_t = F.relu(out)
linear_out = self.fc2(activated_t)
return linear_out, hidden
教师模型结构
教师模型为BERT,并对最后四层进行微调,后面也接了一层全连接。
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in list(self.bert.parameters())[:-4]:
param.requires_grad = False
self.fc = nn.Linear(config.hidden_size, 192)
# self.fc1 = nn.Linear(192, 48)
self.fc2 = nn.Linear(192, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask
_, pooled = self.bert(context, attention_mask=mask, output_all_encoded_layers= False)
out = self.fc(pooled)
out = F.relu(out)
# out = self.fc1(out)
out = self.fc2(out)
return out
损失函数
损失函数为学生输出s_logits和教师输出t_logits的MSE损失与学生输出与真实标签的交叉熵。
# 损失函数
def get_loss(t_logits, s_logits, label, a, T):
loss1 = nn.CrossEntropyLoss()
loss2 = nn.MSELoss()
loss = a * loss1(s_logits, label) + (1 - a) * loss2(t_logits, s_logits)
return loss
模型效果
Teacher
Running time: 116.05915258956909 s
| precision | recall | F1-score | support | |
|---|---|---|---|---|
| 0 | 0.91 | 0.84 | 0.87 | 2168 |
| 1 | 0.82 | 0.90 | 0.86 | 1833 |
| accuracy | 0.86 | 4001 | ||
| macro avg | 0.86 | 0.87 | 0.86 | 4001 |
| weight avg | 0.87 | 0.86 | 0.86 | 4001 |
Student
Running time: 0.155623197555542 s
| precision | recall | F1-score | support | |
|---|---|---|---|---|
| 0 | 0.87 | 0.85 | 0.86 | 2168 |
| 1 | 0.83 | 0.85 | 0.84 | 1833 |
| accuracy | 0.85 | 4001 | ||
| macro avg | 0.85 | 0.85 | 0.85 | 4001 |
| weight avg | 0.85 | 0.85 | 0.85 | 4001 |
可以看出student模型与teacher模型相比精度有一定的丢失,这也可以理解,毕竟student模型结构简单。而在运行时间上大模型是小模型的746倍(cpu)。
TNEWS测试效果
在数据集中选了5类并做了下采样。(此部分具体说明后续完善)
Student alone
| precision | recall | F1-score | support | |
|---|---|---|---|---|
| story | 0.6489 | 0.7907 | 0.7128 | 215 |
| sports | 0.7669 | 0.7849 | 0.7758 | 767 |
| house | 0.7350 | 0.7778 | 0.7558 | 378 |
| car | 0.8162 | 0.7522 | 0.7829 | 791 |
| game | 0.7319 | 0.7041 | 0.7177 | 659 |
| accuracy | 0.7562 | 2810 | ||
| macro avg | 0.7398 | 0.7619 | 0.7490 | 2810 |
| weight avg | 0.7592 | 0.7562 | 0.7567 | 2810 |
Teacher
| precision | recall | F1-score | support | |
|---|---|---|---|---|
| story | 0.6159 | 0.8651 | 0.7195 | 215 |
| sports | 0.8423 | 0.7940 | 0.8174 | 767 |
| house | 0.8030 | 0.8519 | 0.8267 | 378 |
| car | 0.8823 | 0.7863 | 0.8316 | 791 |
| game | 0.7835 | 0.8073 | 0.7952 | 659 |
| accuracy | 0.8082 | 2810 | ||
| macro avg | 0.7854 | 0.8209 | 0.7981 | 2810 |
| weight avg | 0.8172 | 0.8082 | 0.8100 | 2810 |
Student
| precision | recall | F1-score | support | |
|---|---|---|---|---|
| story | 0.5207 | 0.8186 | 0.6365 | 215 |
| sports | 0.8411 | 0.7040 | 0.7665 | 767 |
| house | 0.7678 | 0.7698 | 0.7688 | 378 |
| car | 0.8104 | 0.7459 | 0.7768 | 791 |
| game | 0.6805 | 0.7466 | 0.7120 | 659 |
| accuracy | 0.7434 | 2810 | ||
| macro avg | 0.7241 | 0.7570 | 0.7321 | 2810 |
| weight avg | 0.7604 | 0.7434 | 0.7470 | 2810 |
已知问题
- 没有写蒸馏过程,就是divided by T是如何实现蒸馏(其实是懒)
直接用student小模型训练数据的效果如何,并未做测试。
在TNEWS数据集上完成测试,并上传了训练代码。数据集-量并不是很大,自己也只标注了几千条数据,后续会在CLUE的TNEWS短文本分类数据集上做测试,再出一个对比结果。
在TNEWS数据集上测试,蒸馏结果与直接用student训练效果并未明显提高,还需后续更多测试。
参考链接
-
如何理解soft target这一做法? 知乎 YJango的回答
-
【经典简读】知识蒸馏(Knowledge Distillation) 经典之作
-
Distilling the Knowledge in a Neural Network
-
Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
-
Chinese-Word-Vectors