数据挖掘之京东购买意向预测
目录:
- 一. 数据检查
- 1.1 检查用户是否一致
- 1.2 检查是否有重复记录
- 1.3 检查注册时间
- 1.3 INT类型转换
- 二. 构建特征表单
- 2.1 构建User_table
- 2.2 构建Item_table
- 三. 数据清洗
- 四. 数据探索
- 4.1 一周各天购买情况
- 4.2 一个月中各天购买量
- 4.2.1 2016年2月
- 4.2.2 2016年3月
- 4.2.3 2016年4月
- 4.3 商品类别销售统计
- 4.3.1 一周各商品类别销售情况
- 4.3.2 每月各类商品销售情况(只关注商品8)
- 4.4 查看特定用户对特定商品的的轨迹
- 五. 特征工程
- 5.1 用户基本特征
- 5.2 商品基本特征
- 5.3 评论特征
- 5.4 行为特征
- 5.5 累积用户特征
- 5.6 用户近期行为特征
- 5.7 累积商品特征
- 5.8 类别特征
- 六. 构造训练集/测试集
- 6.1 标签
- 6.2 构造测试集
- 6.3 构造验证集(线下测试集)
- 6.4 构造测试集
- 七. Xgboost建模
一. 数据检查
利用pd.Merge连接两个数据, 观察数据是否减少
1.1 检查用户是否一致
import pandas as pd
def user_action_check():
df_user = pd.read_csv(r'data/JData_User.csv', encoding = 'gbk')
df_sku = df_user.loc[:, 'user_id'].to_frame()
df_month2 = pd.read_csv(r'data\JData_Action_201602.csv', encoding = 'gbk')
print('Is action of Feb. from User file? ', len(df_month2) == len(pd.merge(df_sku, df_month2)))
df_month3 = pd.read_csv(r'data\JData_Action_201603.csv', encoding = 'gbk')
print('Is action of Mar. from User file? ', len(df_month3) == len(pd.merge(df_sku, df_month3)))
df_month4 = pd.read_csv(r'data\JData_Action_201604.csv', encoding = 'gbk')
print('Is action of Apr. from User file? ', len(df_month4) == len(pd.merge(df_sku, df_month4)))
user_action_check()
Is action of Feb. from User file? True
Is action of Mar. from User file? True
Is action of Apr. from User file? True
1.2 检查是否有重复记录
def deduplicate(filepath, filename, newpath):
df_file = pd.read_csv(filepath, encoding = 'gbk')
before = df_file.shape[0]
df_file.drop_duplicates(inplace = True)
after = df_file.shape[0]
n_dup = before - after
print('No. of duplicate records for ' + filename + ' is: ' + str(n_dup))
if n_dup != 0:
df_file.to_csv(newpath, index = None)
else:
print('No duplicate records in ' + filename)
deduplicate(r'data\JData_Action_201603.csv', 'Mar. action', '京东/JData_Action_201603_dedup.csv')
deduplicate(r'data\JData_Action_201604.csv', 'Feb. action', '京东/JData_Action_201604_dedup.csv')
deduplicate(r'data\JData_Comment.csv', 'Comment', '京东/JData_Comment_dedup.csv')
deduplicate(r'data\JData_Product.csv', 'Product', '京东/JData_Product_dedup.csv')
deduplicate(r'data\JData_User.csv', 'User', '京东/JData_User_dedup.csv')

df_month2 = pd.read_csv(r'Fdata\JData_Action_201602.csv', encoding = 'gbk')
IsDuplicated = df_month2.duplicated()
df_d = df_month2[IsDuplicated]
df_d.groupby('type').count()
#发现重复数据大多数都是由于浏览(1),或者点击(6)产生

1.3 检查注册时间
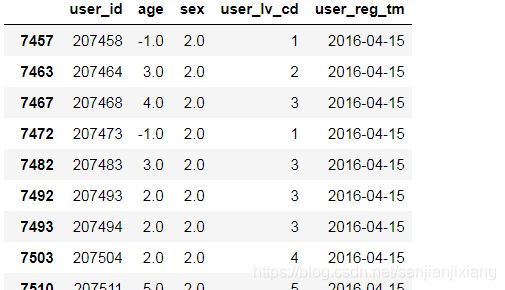
df_user = pd.read_csv(r'data\JData_User.csv', encoding = 'gbk')
df_user['user_reg_tm'] = pd.to_datetime(df_user['user_reg_tm'])
df_user.loc[df_user.user_reg_tm >= '2016-4-15']
df_month = pd.read_csv(r'data\JData_Action_201604.csv')
df_month['time'] = pd.to_datetime(df_month['time'])
df_month.loc[df_month.time >= '2016-4-16']
结论:说明用户没有异常操作数据,所以这一批用户不删除
1.3 INT类型转换
df_month = pd.read_csv(r'data\JData_Action_201602.csv', encoding = 'gbk')
df_month['user_id'] = df_month['user_id'].apply(lambda x: int(x))
print(df_month['user_id'].dtype)
df_month.to_csv(r'京东\JData_Action_201602.csv', index = None)
df_month = pd.read_csv(r'data\JData_Action_201603.csv', encoding = 'gbk')
df_month['user_id'] = df_month['user_id'].apply(lambda x: int(x))
print(df_month['user_id'].dtype)
df_month.to_csv(r'京东\JData_Action_201603.csv', index = None)
df_month = pd.read_csv(r'data\JData_Action_201604.csv', encoding = 'gbk')
df_month['user_id'] = df_month['user_id'].apply(lambda x: int(x))
print(df_month['user_id'].dtype)
df_month.to_csv(r'京东\JData_Action_201604.csv', index = None)
二. 构建特征表单
2.1 构建User_table
#定义文件名
ACTION_201602_FILE = "京东/JData_Action_201602.csv"
ACTION_201603_FILE = "京东/JData_Action_201603.csv"
ACTION_201604_FILE = "京东/JData_Action_201604.csv"
COMMENT_FILE = "京东/JData_Comment.csv"
PRODUCT_FILE = "京东/JData_Product.csv"
USER_FILE = "京东/JData_User.csv"
USER_TABLE_FILE = "京东/User_table.csv"
ITEM_TABLE_FILE = "京东/Item_table.csv"
import pandas as pd
import numpy as np
from collections import Counter
# 功能函数: 对每一个user分组的数据进行统计
def add_type_count(group):
behavior_type = group.type.astype(int)
type_cnt = Counter(behavior_type)
group['browse_num'] = type_cnt[1]
group['addcart_num'] = type_cnt[2]
group['delcart_num'] = type_cnt[3]
group['buy_num'] = type_cnt[4]
group['favor_num'] = type_cnt[5]
group['click_num'] = type_cnt[6]
return group[['user_id', 'browse_num', 'addcart_num', 'delcart_num', 'buy_num', 'favor_num', 'click_num']]
# 由于用户行为数据量较大,一次性读入可能造成内存错误(Memory Error),因而使用pandas的分块(chunk)读取.
def get_from_action_data(fname, chunk_size = 50000):
reader = pd.read_csv(fname, header = 0, iterator = True, encoding = 'gbk')
chunks = []
loop = True
while loop:
try:
chunk = reader.get_chunk(chunk_size)[['user_id', 'type']]
chunks.append(chunk)
except StopIteration:
loop = False
print('Iteration is stopped')
df_ac = pd.concat(chunks, ignore_index = True)
df_ac = df_ac.groupby(['user_id'], as_index = False).apply(add_type_count)
df_ac = df_ac.drop_duplicates('user_id')
return df_ac
# 将各个action数据的统计量进行聚合
def merge_action_data():
df_ac = []
df_ac.append(get_from_action_data(fname = ACTION_201602_FILE))
df_ac.append(get_from_action_data(fname = ACTION_201603_FILE))
df_ac.append(get_from_action_data(fname = ACTION_201604_FILE))
df_ac = pd.concat(df_ac, ignore_index = True)
# 用户在不同action表中统计量求和
df_ac = df_ac.groupby(['user_id'], as_index = False).sum()
# 构造转化率字段
df_ac['buy_addcart_ratio'] = df_ac['buy_num'] / df_ac['addcart_num']
df_ac['buy_browse_ratio'] = df_ac['buy_num'] / df_ac['browse_num']
df_ac['buy_click_ratio'] = df_ac['buy_num'] / df_ac['click_num']
df_ac['buy_favor_ratio'] = df_ac['buy_num'] / df_ac['favor_num']
# 将大于1的转化率字段置为1(100%)
df_ac.loc[df_ac['buy_addcart_ratio'] > 1, 'buy_addcart_ratio'] = 1.
df_ac.loc[df_ac['buy_browse_ratio'] > 1, 'buy_browse_ratio'] = 1.
df_ac.loc[df_ac['buy_click_ratio'] > 1, 'buy_click_ratio'] = 1.
df_ac.loc[df_ac['buy_favor_ratio'] > 1, 'buy_favor_ratio'] = 1.
return df_ac
# 从FJData_User表中抽取需要的字段
def get_from_jdata_user():
df_user = pd.read_csv(USER_FILE, header = 0)
df_user = df_user[['user_id', 'age', 'sex', 'user_lv_cd']]
return df_user
user_base = get_from_jdata_user()
user_behavior = merge_action_data()
user_behavior = pd.merge(user_base, user_behavior, on = ['user_id'], how = 'left')
user_behavior.to_csv(USER_TABLE_FILE, index = False)
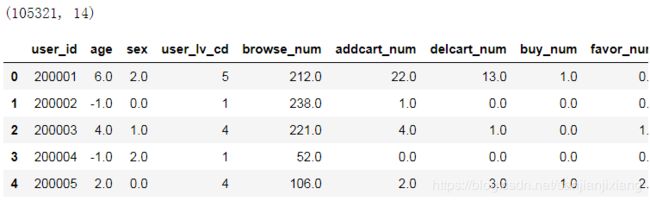
user_table = pd.read_csv(USER_TABLE_FILE)
print(user_table.shape)
user_table.head()
2.2 构建Item_table
# 读取Product中商品
def get_from_jdata_product():
df_item = pd.read_csv(PRODUCT_FILE, header = 0, encoding = 'gbk')
return df_item
# 对每一个商品分组进行统计
def add_type_count(group):
behavior_type = group.type.astype(int)
type_cnt = Counter(behavior_type)
group['browse_num'] = type_cnt[1]
group['addcart_num'] = type_cnt[2]
group['delcart_num'] = type_cnt[3]
group['buy_num'] = type_cnt[4]
group['favor_num'] = type_cnt[5]
group['click_num'] = type_cnt[6]
return group[['sku_id', 'browse_num', 'addcart_num', 'delcart_num', 'buy_num', 'favor_num', 'click_num']]
# 对action中的数据进行统计
def get_from_action_data(fname, chunk_size = 50000):
reader = pd.read_csv(fname, header = 0, iterator = True)
chunks = []
loop = True
while loop:
try:
chunk = reader.get_chunk(chunk_size)[['sku_id', 'type']]
chunks.append(chunk)
except StopIteration:
loop = False
print('Iteration is stopped')
df_ac = pd.concat(chunks, ignore_index = True)
df_ac = df_ac.groupby('sku_id', as_index = False).apply(add_type_count)
df_ac = df_ac.drop_duplicates('sku_id')
return df_ac
# 获取评论中的商品数据,如果存在某一个商品有两个日期的评论,取最晚的那一个
def get_from_jdata_comment():
df_cmt = pd.read_csv(COMMENT_FILE, header = 0)
df_cmt['dt'] = pd.to_datetime(df_cmt['dt'])
idx = df_cmt.groupby(['sku_id'])['dt'].transform(max) == df_cmt['dt']
df_cmt = df_cmt[idx]
return df_cmt[['sku_id', 'comment_num', 'has_bad_comment', 'bad_comment_rate']]
# 数据合并
def merge_action_data():
df_ac = []
df_ac.append(get_from_action_data(fname = ACTION_201602_FILE))
df_ac.append(get_from_action_data(fname = ACTION_201603_FILE))
df_ac.append(get_from_action_data(fname = ACTION_201604_FILE))
df_ac = pd.concat(df_ac, ignore_index = True)
# 用户在不同action表中统计量求和
df_ac = df_ac.groupby(['sku_id'], as_index = False).sum()
# 构造转化率字段
df_ac['buy_addcart_ratio'] = df_ac['buy_num'] / df_ac['addcart_num']
df_ac['buy_browse_ratio'] = df_ac['buy_num'] / df_ac['browse_num']
df_ac['buy_click_ratio'] = df_ac['buy_num'] / df_ac['click_num']
df_ac['buy_favor_ratio'] = df_ac['buy_num'] / df_ac['favor_num']
# 将大于1的转化率字段置为1(100%)
df_ac.loc[df_ac['buy_addcart_ratio'] > 1, 'buy_addart_ratio'] = 1.
df_ac.loc[df_ac['buy_browse_ratio'] > 1, 'buy_browse_ratio'] = 1.
df_ac.loc[df_ac['buy_click_ratio'] > 1, 'buy_click_ratio'] = 1.
df_ac.loc[df_ac['buy_favor_ratio'] > 1, 'buy_favor_ratio'] = 1.
return df_ac
item_base = get_from_jdata_product()
item_behavior = merge_action_data()
item_comment = get_from_jdata_comment()
item_behavior = pd.merge(item_base, item_behavior, on = 'sku_id', how = 'left')
item_behavior = pd.merge(item_behavior, item_comment, on = 'sku_id', how = 'left')
item_behavior.to_csv(ITEM_TABLE_FILE, index = False)
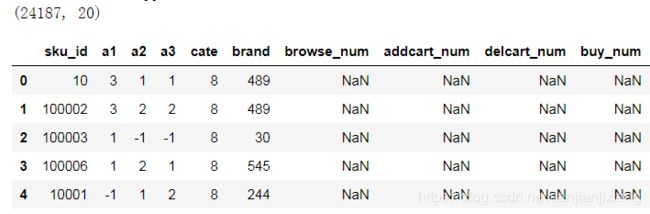
item_tabel = pd.read_csv(ITEM_TABLE_FILE)
print(item_tabel.shape)
item_tabel.head()
三. 数据清洗
import pandas as pd
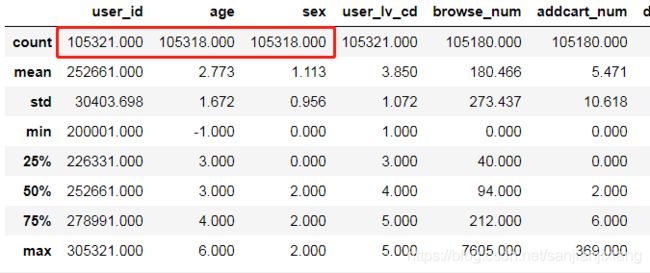
df_user = pd.read_csv('京东/User_table.csv', header = 0)
pd.options.display.float_format = '{:.3f}'.format #输出格式设置,保留三位小数
df_user.describe()
df_user[df_user['age'].isnull()]

# 删除没有age,sex的用户
delete_index = df_user[df_user['age'].isnull()].index
df_user.drop(delete_index, axis = 0, inplace = True)
# 删除无交互记录的用户
df_naction = df_user[df_user['browse_num'].isnull() & df_user['addcart_num'].isnull() & df_user['delcart_num'].isnull() & df_user['buy_num'].isnull() & df_user['favor_num'].isnull() & df_user['click_num'].isnull()]
df_user.drop(df_naction.index, axis = 0, inplace = True)
print(len(df_user))
# 统计并删除无购买记录的用户
df_bzero = df_user[df_user['buy_num'] == 0]
print(len(df_bzero))
df_user = df_user[df_user['buy_num'] != 0]
df_user.describe()
105177
75694
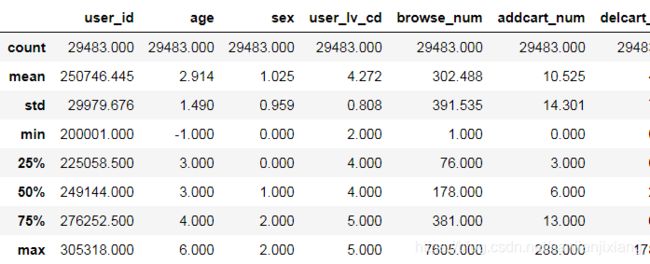
# 删除爬虫及惰性用户
bindex = df_user[df_user['buy_browse_ratio'] < 0.0005].index
print(len(bindex))
df_user.drop(bindex, axis = 0, inplace = True)
cindex = df_user[df_user['buy_click_ratio'] < 0.0005].index
print(len(cindex))
df_user.drop(cindex, axis = 0, inplace = True)
df_user.describe()
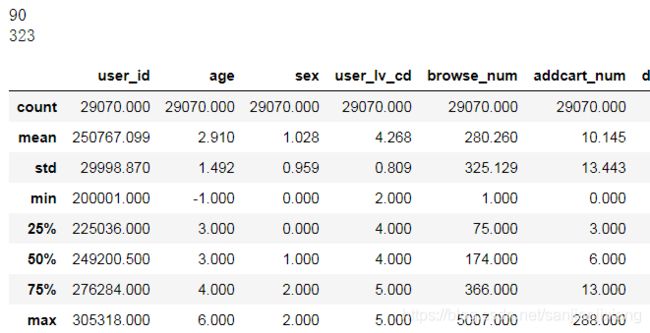
df_user.to_csv('京东/User_table.csv', index = None)
四. 数据探索
4.1 一周各天购买情况
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
ACTION_201602_FILE = "京东/JData_Action_201602.csv"
ACTION_201603_FILE = "京东/JData_Action_201603.csv"
ACTION_201604_FILE = "京东/JData_Action_201604.csv"
COMMENT_FILE = "京东/JData_Comment.csv"
PRODUCT_FILE = "京东/JData_Product.csv"
USER_FILE = "京东/JData_User.csv"
USER_TABLE_FILE = "京东/User_table.csv"
ITEM_TABLE_FILE = "京东/Item_table.csv"
# 提取购买(type=4)的行为数据
def get_from_action_data(fname, chunk_size = 50000):
reader = pd.read_csv(fname, header = 0, iterator = True)
chunks = []
loop = True
while loop:
try:
chunk = reader.get_chunk(chunk_size)[['user_id', 'sku_id', 'type', 'time']]
chunks.append(chunk)
except StopIteration:
loop = False
print('Iteration is stopped')
df_ac = pd.concat(chunks, ignore_index = True)
df_ac = df_ac[df_ac['type'] == 4]
return df_ac[['user_id', 'sku_id', 'time']]
df_ac = []
df_ac.append(get_from_action_data(fname = ACTION_201602_FILE))
df_ac.append(get_from_action_data(fname = ACTION_201603_FILE))
df_ac.append(get_from_action_data(fname = ACTION_201604_FILE))
df_ac = pd.concat(df_ac, ignore_index = True)
print(df_ac.dtypes)
df_ac.head()
# 将time字段转换为datetime类型
df_ac['time'] = pd.to_datetime(df_ac['time'])
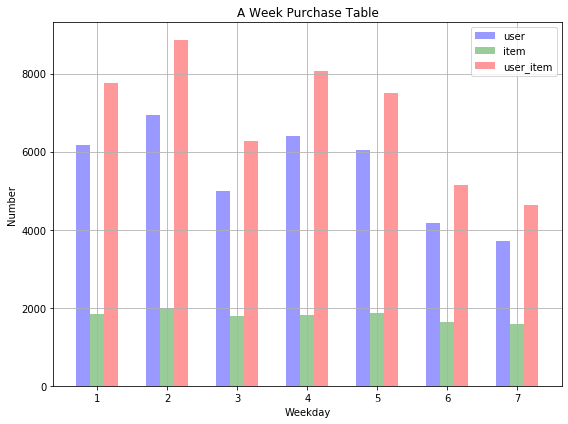
# 使用lambda匿名函数将时间time转换为星期(周一为1, 周日为7)
df_ac['time'] = df_ac['time'].apply(lambda x: x.weekday() + 1)
# 周一到周日每天购买用户个数
df_user = df_ac.groupby('time')['user_id'].nunique()
df_user = df_user.to_frame().reset_index()
df_user.columns = ['weekday', 'user_num']
# 周一到周日每天购买商品个数
df_item = df_ac.groupby('time')['sku_id'].nunique()
df_item = df_item.to_frame().reset_index()
df_item.columns = ['weekday', 'item_num']
# 周一到周日每天购买记录个数
df_ui = df_ac.groupby('time', as_index = False).size()
df_ui = df_ui.to_frame().reset_index()
df_ui.columns = ['weekday', 'user_item_num']
bar_width = 0.2 # 条形宽度
opacity = 0.4 # 透明度
plt.figure(figsize = (8, 6))
plt.bar(df_user['weekday'], df_user['user_num'], bar_width, alpha = opacity, color = 'b', label = 'user')
plt.bar(df_item['weekday'] + bar_width, df_item['item_num'], bar_width, alpha = opacity, color = 'g', label = 'item')
plt.bar(df_ui['weekday'] + bar_width*2, df_ui['user_item_num'], bar_width, alpha = opacity, color = 'r', label = 'user_item')
plt.xlabel('Weekday')
plt.ylabel('Number')
plt.title('A Week Purchase Table')
plt.xticks(df_user['weekday'] + bar_width, (1, 2, 3, 4, 5, 6, 7))
plt.tight_layout()
plt.legend(prop = {'size': 10})
plt.grid()
4.2 一个月中各天购买量
4.2.1 2016年2月
df_ac = get_from_action_data(fname = ACTION_201602_FILE)
df_ac['time'] = pd.to_datetime(df_ac['time']).apply(lambda x: x.day)
df_user = df_ac.groupby('time')['user_id'].nunique()
df_user = df_user.to_frame().reset_index()
df_user.columns = ['day', 'user_num']
df_item = df_ac.groupby('time')['sku_id'].nunique()
df_item = df_item.to_frame().reset_index()
df_item.columns = ['day', 'item_num']
df_ui = df_ac.groupby('time', as_index = False).size()
df_ui = df_ui.to_frame().reset_index()
df_ui.columns = ['day', 'user_item_num']
bar_width = 0.2
opacith = 0.4
day_range = range(1, len(df_user['day']) + 1)
plt.figure(figsize = (10, 7))
plt.bar(df_user['day'], df_user['user_num'], bar_width, alpha = opacity, color = 'b', label = 'user')
plt.bar(df_item['day'] + bar_width, df_item['item_num'], bar_width, alpha = opacity, color = 'g', label = 'item')
plt.bar(df_ui['day'] + bar_width*2, df_ui['user_item_num'], bar_width, alpha = opacith, color = 'r', label = 'user_item')
plt.xlabel('Day')
plt.ylabel('Number')
plt.title('February Purchase Table')
plt.xticks(df_user['day'] + bar_width, day_range)
plt.tight_layout()
plt.legend(prop = {'size': 12})
plt.grid()
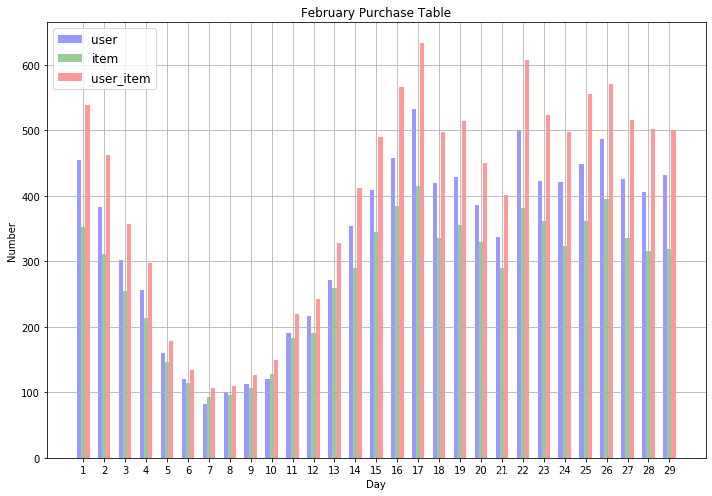
4.2.2 2016年3月
df_ac = get_from_action_data(fname = ACTION_201603_FILE)
df_ac['time'] = pd.to_datetime(df_ac['time']).apply(lambda x: x.day)
df_user = df_ac.groupby('time')['user_id'].nunique()
df_user = df_user.to_frame().reset_index()
df_user.columns = ['day', 'user_num']
df_item = df_ac.groupby('time')['sku_id'].nunique()
df_item = df_item.to_frame().reset_index()
df_item.columns = ['day', 'item_num']
df_ui = df_ac.groupby('time', as_index = False).size()
df_ui = df_ui.to_frame().reset_index()
df_ui.columns = ['day', 'user_item_num']
bar_width = 0.2
opacith = 0.4
day_range = range(1, len(df_user['day']) + 1)
plt.figure(figsize = (10, 7))
plt.bar(df_user['day'], df_user['user_num'], bar_width, alpha = opacity, color = 'b', label = 'user')
plt.bar(df_item['day'] + bar_width, df_item['item_num'], bar_width, alpha = opacity, color = 'g', label = 'item')
plt.bar(df_ui['day'] + bar_width*2, df_ui['user_item_num'], bar_width, alpha = opacith, color = 'r', label = 'user_item')
plt.xlabel('Day')
plt.ylabel('Number')
plt.title('March Purchase Table')
plt.xticks(df_user['day'] + bar_width, day_range)
plt.tight_layout()
plt.legend(prop = {'size': 12})
#plt.grid()
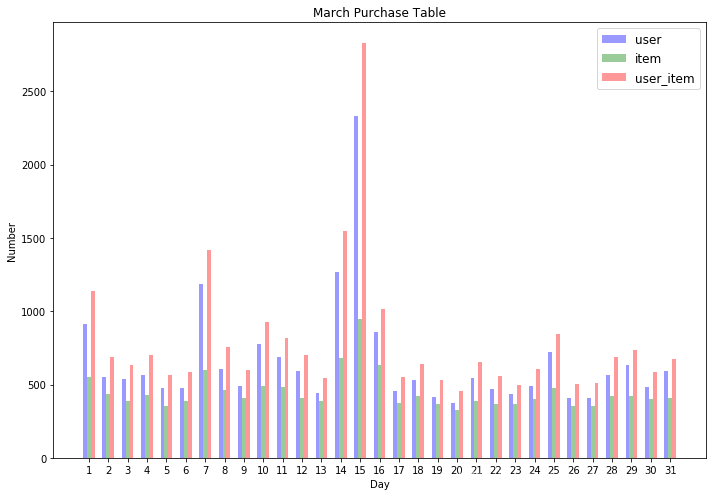
4.2.3 2016年4月
df_ac = get_from_action_data(fname = ACTION_201604_FILE)
df_ac['time'] = pd.to_datetime(df_ac['time']).apply(lambda x: x.day)
df_user = df_ac.groupby('time')['user_id'].nunique()
df_user = df_user.to_frame().reset_index()
df_user.columns = ['day', 'user_num']
df_item = df_ac.groupby('time')['sku_id'].nunique()
df_item = df_item.to_frame().reset_index()
df_item.columns = ['day', 'item_num']
df_ui = df_ac.groupby('time', as_index = False).size()
df_ui = df_ui.to_frame().reset_index()
df_ui.columns = ['day', 'user_item_num']
bar_width = 0.2
opacith = 0.4
day_range = range(1, len(df_user['day']) + 1)
plt.figure(figsize = (12, 8))
plt.bar(df_user['day'], df_user['user_num'], bar_width, alpha = opacity, color = 'b', label = 'user')
plt.bar(df_item['day'] + bar_width, df_item['item_num'], bar_width, alpha = opacity, color = 'g', label = 'item')
plt.bar(df_ui['day'] + bar_width*2, df_ui['user_item_num'], bar_width, alpha = opacith, color = 'r', label = 'user_item')
plt.xlabel('Day')
plt.ylabel('Number')
plt.title('March Purchase Table')
plt.xticks(df_user['day'] + bar_width, day_range)
plt.tight_layout()
plt.legend(prop = {'size': 12})
#plt.grid()
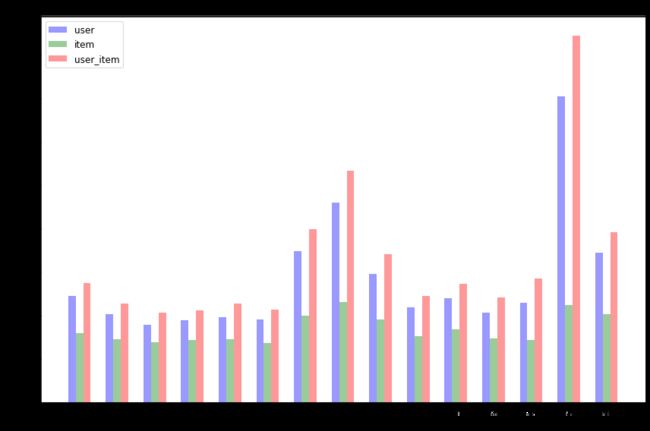
4.3 商品类别销售统计
4.3.1 一周各商品类别销售情况
def get_from_action_data(fname, chunk_size = 50000):
reader = pd.read_csv(fname, header = 0, iterator = True)
chunks = []
loop = True
while loop:
try:
chunk = reader.get_chunk(chunk_size)[['cate', 'brand', 'type', 'time']]
chunks.append(chunk)
except StopIteration:
loop = False
print('Iteration is stopped')
df_ac = pd.concat(chunks, ignore_index = True)
df_ac = df_ac[df_ac['type'] == 4]
return df_ac[['cate', 'brand', 'type', 'time']]
df_ac = []
df_ac.append(get_from_action_data(fname = ACTION_201602_FILE))
df_ac.append(get_from_action_data(fname = ACTION_201603_FILE))
df_ac.append(get_from_action_data(fname = ACTION_201604_FILE))
df_ac = pd.concat(df_ac, ignore_index = True)
df_ac['time'] = pd.to_datetime(df_ac['time']).apply(lambda x: x.weekday() + 1)
print(df_ac.shape)
df_ac.head()

# 周一到周日每天购买商品类别数量统计
df_product = df_ac.groupby(['time', 'cate']).brand.count()
df_product = df_product.unstack() # unstack() 将行旋转到列
df_product.plot(kind = 'bar', title = 'Cate Purchase Table in a Week', figsize = (8, 6))
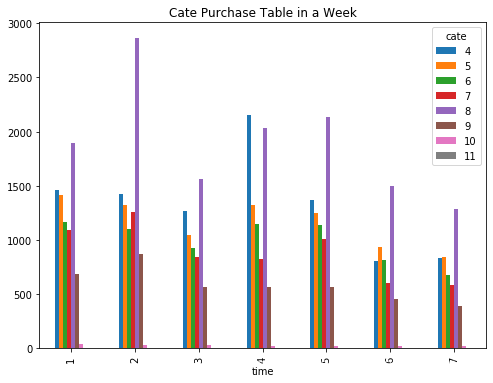
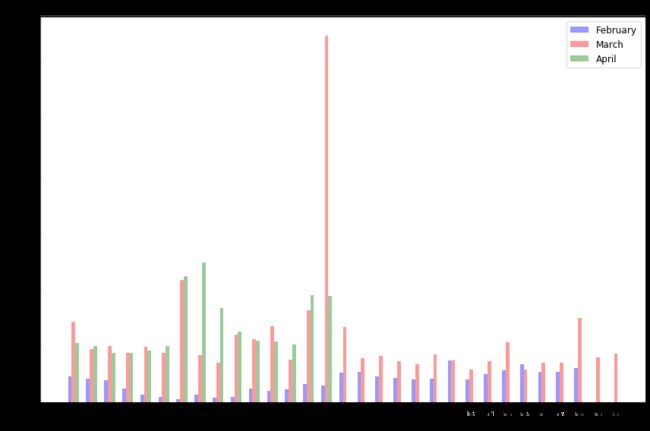
4.3.2 每月各类商品销售情况(只关注商品8)
df_ac2 = get_from_action_data(fname = ACTION_201602_FILE)
df_ac2['time'] = pd.to_datetime(df_ac2['time']).apply(lambda x: x.day)
df_ac3 = get_from_action_data(fname = ACTION_201603_FILE)
df_ac3['time'] = pd.to_datetime(df_ac3['time']).apply(lambda x: x.day)
df_ac4 = get_from_action_data(fname = ACTION_201604_FILE)
df_ac4['time'] = pd.to_datetime(df_ac4['time']).apply(lambda x: x.day)
dc_cate2 = df_ac2[df_ac2['cate'] == 8]
dc_cate2 = dc_cate2.groupby('time').brand.count()
dc_cate2 = dc_cate2.to_frame().reset_index()
dc_cate2.columns = ['day', 'product_num']
dc_cate3 = df_ac3[df_ac3['cate'] == 8]
dc_cate3 = dc_cate3.groupby('time').brand.count()
dc_cate3 = dc_cate3.to_frame().reset_index()
dc_cate3.columns = ['day', 'product_num']
dc_cate4 = df_ac4[df_ac4['cate'] == 8]
dc_cate4 = dc_cate4.groupby('time').brand.count()
dc_cate4 = dc_cate4.to_frame().reset_index()
dc_cate4.columns = ['day', 'product_num']
bar_width = 0.2
opacity = 0.4
day_range = range(1, len(dc_cate3['day']) + 1)
plt.figure(figsize = (12, 8))
plt.bar(dc_cate2['day'], dc_cate2['product_num'], bar_width, alpha = opacity, color = 'b', label = 'February')
plt.bar(dc_cate3['day'] + bar_width, dc_cate3['product_num'], bar_width, alpha = opacity, color = 'r', label = 'March')
plt.bar(dc_cate4['day'] + bar_width*2, dc_cate4['product_num'], bar_width, alpha = opacity, color = 'g', label = 'April')
plt.xlabel('Day')
plt.ylabel('Number')
plt.title('Cate-8 Purchase Table')
plt.xticks(dc_cate3['day'] + bar_width, day_range)
plt.tight_layout()
plt.legend(prop = {'size': 12})
4.4 查看特定用户对特定商品的的轨迹
def special_ui_action_data(fname, user_id, item_id, chunk_size = 50000):
reader = pd.read_csv(fname, header = 0, iterator = True)
chunks = []
loop = True
while loop:
try:
chunk = reader.get_chunk(chunk_size)[['user_id', 'sku_id', 'type', 'time']]
chunks.append(chunk)
except StopIteration:
loop = False
print('Iteration is stopped')
df_ac = pd.concat(chunks, ignore_index = True)
df_ac = df_ac[(df_ac['user_id'] == user_id) & (df_ac['sku_id'] == item_id)]
return df_ac
def explore_user_item_via_time():
user_id = 266079
item_id = 138778
df_ac = []
df_ac.append(special_ui_action_data(ACTION_201602_FILE, user_id, item_id))
df_ac.append(special_ui_action_data(ACTION_201603_FILE, user_id, item_id))
df_ac.append(special_ui_action_data(ACTION_201604_FILE, user_id, item_id))
df_ac = pd.concat(df_ac, ignore_index = False)
print(df_ac.sort_values('time'))
explore_user_item_via_time()

五. 特征工程
import pandas as pd
import numpy as np
action_02_path = '京东/JData_Action_201602.csv'
action_03_path = '京东/JData_Action_201603.csv'
action_04_path = '京东/JData_Action_201604.csv'
comment_path = '京东/JData_Comment.csv'
product_path = '京东/JData_Product.csv'
user_path = '京东/JData_User.csv'
def get_actions(action_path):
reader = pd.read_csv(action_path, iterator = True)
#reader[['user_id', 'sku_id', 'model_id', 'type', 'cate', 'brand']] = reader[['user_id', 'sku_id', 'model_id', 'type', 'cate', 'brand']].astype('float32')
chunks = []
loop = True
while loop:
try:
chunk = reader.get_chunk(50000)
chunks.append(chunk)
except StopIteration:
loop = False
print('Iteration is stopped.')
action = pd.concat(chunks, ignore_index = True)
action[['user_id', 'sku_id', 'model_id', 'type', 'cate', 'brand']] = action[['user_id', 'sku_id', 'model_id', 'type', 'cate', 'brand']].astype('float32')
return action
def get_all_action():
action_02 = get_actions(action_02_path)
action_03 = get_actions(action_03_path)
action_04 = get_actions(action_04_path)
actions = pd.concat([action_02, action_03, action_04])
return actions
5.1 用户基本特征
from sklearn.preprocessing import LabelEncoder
def get_basic_user_feat():
user = pd.read_csv(user_path, encoding = 'gbk')
user.dropna(axis = 0, how = 'any', inplace = True)
user[['sex', 'age']] = user[['sex', 'age']].astype(int)
age_df = LabelEncoder().fit_transform(user['age'])
age_df = pd.get_dummies(age_df, prefix = 'age')
sex_df = pd.get_dummies(user['sex'], prefix = 'sex')
user_lv_df = pd.get_dummies(user['user_lv_cd'], prefix = 'user_lv_cd')
user = pd.concat([user['user_id'], age_df, sex_df, user_lv_df], axis = 1)
return user
5.2 商品基本特征
def get_basic_product_feat():
product = pd.read_csv(product_path)
attr1_df = pd.get_dummies(product['a1'], prefix = 'a1')
attr2_df = pd.get_dummies(product['a2'], prefix = 'a2')
attr3_df = pd.get_dummies(product['a3'], prefix = 'a3')
product = pd.concat([product[['sku_id', 'cate', 'brand']], attr1_df, attr2_df, attr3_df], axis = 1)
return product
5.3 评论特征
comment_date = ["2016-02-01", "2016-02-08", "2016-02-15", "2016-02-22", "2016-02-29", "2016-03-07",
"2016-03-14", "2016-03-21", "2016-03-28", "2016-04-04","2016-04-11", "2016-04-15"]
def get_comments_product_feat(end_date):
comments = pd.read_csv(comment_path)
comment_date_end = end_date
comment_date_begin = comment_date[0]
for date in reversed(comment_date):
if date < comment_date_end:
comment_date_begin = date
break
comments = comments[comments.dt == comment_date_begin]
df = pd.get_dummies(comments['comment_num'], prefix = 'comment_num')
# 为了防止某个时间段不具备评论数为0的情况(测试集出现过这种情况)
for i in range(0, 5):
if 'comment_num_' + str(i) not in df.columns:
df['comment_num_' + str(i)] = 0
df = df[['comment_num_0', 'comment_num_1', 'comment_num_2', 'comment_num_3', 'comment_num_4']]
comments = pd.concat([comments, df], axis = 1)
comments = comments[['sku_id', 'has_bad_comment', 'bad_comment_rate','comment_num_0',
'comment_num_1', 'comment_num_2', 'comment_num_3', 'comment_num_4']]
return comments
5.4 行为特征
# 获取某个时间段的行为记录
def get_time_action(start_date, end_date, all_actions):
actions = all_actions[(all_actions.time >= start_date) & (all_actions.time < end_date)].copy()
return actions
def get_action_feat(start_date, end_date, all_actions, i):
actions = get_time_action(start_date, end_date, all_actions)
actions = actions[['user_id', 'sku_id', 'cate', 'type']]
before_date = 'action_before_%s' % i
df = pd.get_dummies(actions['type'], prefix = before_date)
actions = pd.concat([actions, df], axis = 1)
# 分组统计,用户-类别-商品,不同用户对不同类别下商品的行为计数
actions = actions.groupby(['user_id', 'sku_id', 'cate'], as_index = False).sum()
# 分组统计,用户-类别,不同用户对不同商品类别的行为计数
user_cate = actions.groupby(['user_id', 'cate'], as_index = False).sum()
del user_cate['sku_id']
del user_cate['type']
actions = pd.merge(actions, user_cate, how = 'left', on = ['user_id', 'cate'])
#本类别下其他商品点击量
# 前述两种分组含有相同名称的不同行为的计数,系统会自动针对名称调整添加后缀,x,y,所以这里作差统计的是同一类别下其他商品的行为计数
actions[before_date + '_1.0_y'] = actions[before_date + '_1.0_y'] - actions[before_date + '_1.0_x']
actions[before_date + '_2.0_y'] = actions[before_date + '_2.0_y'] - actions[before_date + '_2.0_x']
actions[before_date + '_3.0_y'] = actions[before_date + '_3.0_y'] - actions[before_date + '_3.0_x']
actions[before_date + '_4.0_y'] = actions[before_date + '_4.0_y'] - actions[before_date + '_4.0_x']
actions[before_date + '_5.0_y'] = actions[before_date + '_5.0_y'] - actions[before_date + '_5.0_x']
actions[before_date + '_6.0_y'] = actions[before_date + '_6.0_y'] - actions[before_date + '_6.0_x']
# 统计用户对不同类别下商品计数与该类别下商品行为计数均值(对时间)的差值
actions[before_date + 'minus_mean_1'] = actions[before_date + '_1.0_x'] - actions[before_date + '_1.0_x'] / i
actions[before_date + 'minus_mean_2'] = actions[before_date + '_2.0_x'] - actions[before_date + '_2.0_x'] / i
actions[before_date + 'minus_mean_3'] = actions[before_date + '_3.0_x'] - actions[before_date + '_3.0_x'] / i
actions[before_date + 'minus_mean_4'] = actions[before_date + '_4.0_x'] - actions[before_date + '_4.0_x'] / i
actions[before_date + 'minus_mean_5'] = actions[before_date + '_5.0_x'] - actions[before_date + '_5.0_x'] / i
actions[before_date + 'minus_mean_6'] = actions[before_date + '_6.0_x'] - actions[before_date + '_6.0_x'] / i
del actions['type']
return actions
5.5 累积用户特征
分时间段用户不同行为的购买转化率和均值
from datetime import datetime
from datetime import timedelta
def get_accumulate_user_feat(end_date, all_actions, day):
start_date = datetime.strptime(end_date, '%Y-%m-%d') - timedelta(days = day)
start_date = start_date.strftime('%Y-%m-%d')
before_date = 'user_action_%s' % day
actions = get_time_action(start_date, end_date, all_actions)
df = pd.get_dummies(actions['type'], prefix = before_date)
actions['date'] = pd.to_datetime(actions['time']).apply(lambda x: x.date())
actions = pd.concat([actions[['user_id', 'date']], df], axis = 1)
actions = actions.groupby('user_id', as_index = False).sum()
actions[before_date + '_1_ratio'] = np.log(1 + actions[before_date + '_4.0']) - np.log(1 + actions[before_date + '_1.0'])
actions[before_date + '_2_ratio'] = np.log(1 + actions[before_date + '_4.0']) - np.log(1 + actions[before_date + '_2.0'])
actions[before_date + '_3_ratio'] = np.log(1 + actions[before_date + '_4.0']) - np.log(1 + actions[before_date + '_3.0'])
actions[before_date + '_5_ratio'] = np.log(1 + actions[before_date + '_4.0']) - np.log(1 + actions[before_date + '_5.0'])
actions[before_date + '_6_ratio'] = np.log(1 + actions[before_date + '_4.0']) - np.log(1 + actions[before_date + '_6.0'])
actions[before_date + '_1_mean'] = actions[before_date + '_1.0'] / day
actions[before_date + '_2_mean'] = actions[before_date + '_2.0'] / day
actions[before_date + '_3_mean'] = actions[before_date + '_3.0'] / day
actions[before_date + '_4_mean'] = actions[before_date + '_4.0'] / day
actions[before_date + '_5_mean'] = actions[before_date + '_5.0'] / day
actions[before_date + '_6_mean'] = actions[before_date + '_6.0'] / day
return actions
5.6 用户近期行为特征
def get_recent_user_feat(end_date, all_actions):
actions_3 = get_accumulate_user_feat(end_date, all_actions, 3)
actions_30 = get_accumulate_user_feat(end_date, all_actions, 30)
actions = pd.merge(actions_3, actions_30, how = 'left', on = 'user_id')
del actions_3
del actions_30
actions['recent_action1'] = np.log(1 + actions['user_action_30_1.0'] - actions['user_action_3_1.0']) - np.log(1 + actions['user_action_30_1.0'])
actions['recent_action2'] = np.log(1 + actions['user_action_30_2.0'] - actions['user_action_3_2.0']) - np.log(1 + actions['user_action_30_2.0'])
actions['recent_action3'] = np.log(1 + actions['user_action_30_3.0'] - actions['user_action_3_3.0']) - np.log(1 + actions['user_action_30_3.0'])
actions['recent_action4'] = np.log(1 + actions['user_action_30_4.0'] - actions['user_action_3_4.0']) - np.log(1 + actions['user_action_30_4.0'])
actions['recent_action5'] = np.log(1 + actions['user_action_30_5.0'] - actions['user_action_3_5.0']) - np.log(1 + actions['user_action_30_5.0'])
actions['recent_action6'] = np.log(1 + actions['user_action_30_6.0'] - actions['user_action_3_6.0']) - np.log(1 + actions['user_action_30_6.0'])
return actions
# 用户对同类别下各种商品的行为
# 增加用户对不同类别的交互特征
def get_user_cate_feature(start_date, end_date, all_actions):
actions = get_time_action(start_date, end_date, all_actions)
actions = actions[['user_id', 'cate', 'type']]
df = pd.get_dummies(actions['type'], prefix = 'type')
actions = pd.concat([actions[['user_id', 'cate']], df], axis = 1)
actions = actions.groupby(['user_id', 'cate']).sum()
actions = actions.unstack()
actions.columns = actions.columns.swaplevel(0, 1)
actions.columns = ['cate_4_type1', 'cate_5_type1', 'cate_6_type1', 'cate_7_type1', 'cate_8_type1',
'cate_9_type1', 'cate_10_type1', 'cate_11_type1', 'cate_4_type2', 'cate_5_type2',
'cate_6_type2', 'cate_7_type2','cate_8_type2', 'cate_9_type2', 'cate_10_type2',
'cate_11_type2', 'cate_4_type3', 'cate_5_type3', 'cate_6_type3', 'cate_7_type3',
'cate_8_type3', 'cate_9_type3', 'cate_10_type3', 'cate_11_type3','cate_4_type4',
'cate_5_type4', 'cate_6_type4', 'cate_7_type4', 'cate_8_type4', 'cate_9_type4',
'cate_10_type4', 'cate_11_type4', 'cate_4_type5', 'cate_5_type5', 'cate_6_type5',
'cate_7_type5', 'cate_8_type5', 'cate_9_type5', 'cate_10_type5', 'cate_11_type5',
'cate_4_type6', 'cate_5_type6', 'cate_6_type6', 'cate_7_type6',
'cate_8_type6', 'cate_9_type6', 'cate_10_type6', 'cate_11_type6']
actions = actions.fillna(0)
actions['cate_action_sum'] = actions.sum(axis = 1)
actions['cate8_percentage'] = (actions['cate_8_type1'] + actions['cate_8_type2'] +
actions['cate_8_type3'] + actions['cate_8_type4'] +
actions['cate_8_type5'] + actions['cate_8_type6']) / actions['cate_action_sum']
actions['cate4_percentage'] = (actions['cate_4_type1'] + actions['cate_4_type2'] +
actions['cate_4_type3'] + actions['cate_4_type4'] +
actions['cate_4_type5'] + actions['cate_4_type6']) / actions['cate_action_sum']
actions['cate5_percentage'] = (actions['cate_5_type1'] + actions['cate_5_type2'] +
actions['cate_5_type3'] + actions['cate_5_type4'] +
actions['cate_5_type5'] + actions['cate_5_type6']) / actions['cate_action_sum']
actions['cate6_percentage'] = (actions['cate_6_type1'] + actions['cate_6_type2'] +
actions['cate_6_type3'] + actions['cate_6_type4'] +
actions['cate_6_type5'] + actions['cate_6_type6']) / actions['cate_action_sum']
actions['cate7_percentage'] = (actions['cate_7_type1'] + actions['cate_7_type2'] +
actions['cate_7_type3'] + actions['cate_7_type4'] +
actions['cate_7_type5'] + actions['cate_7_type6']) / actions['cate_action_sum']
actions['cate9_percentage'] = (actions['cate_9_type1'] + actions['cate_9_type2'] +
actions['cate_9_type3'] + actions['cate_9_type4'] +
actions['cate_9_type5'] + actions['cate_9_type6']) / actions['cate_action_sum']
actions['cate10_percentage'] = (actions['cate_10_type1'] + actions['cate_10_type2'] +
actions['cate_10_type3'] + actions['cate_10_type4'] +
actions['cate_10_type5'] + actions['cate_10_type6']) / actions['cate_action_sum']
actions['cate11_percentage'] = (actions['cate_11_type1'] + actions['cate_11_type2'] +
actions['cate_11_type3'] + actions['cate_11_type4'] +
actions['cate_11_type5'] + actions['cate_11_type6']) / actions['cate_action_sum']
actions['cate8_type1_percentage'] = np.log(1 + actions['cate_8_type1']) - np.log(
1 + actions['cate_8_type1'] + actions['cate_4_type1'] + actions['cate_5_type1']
+ actions['cate_6_type1'] + actions['cate_7_type1'] + actions['cate_9_type1']
+ actions['cate_10_type1'] + actions['cate_11_type1'])
actions['cate8_type2_percentage'] = np.log(1 + actions['cate_8_type2']) - np.log(
1 + actions['cate_8_type2'] + actions['cate_4_type2'] + actions['cate_5_type2']
+ actions['cate_6_type2'] + actions['cate_7_type2'] + actions['cate_9_type2']
+ actions['cate_10_type2'] + actions['cate_11_type2'])
actions['cate8_type3_percentage'] = np.log(1 + actions['cate_8_type3']) - np.log(
1 + actions['cate_8_type3'] + actions['cate_4_type3'] + actions['cate_5_type3']
+ actions['cate_6_type3'] + actions['cate_7_type3'] + actions['cate_9_type3']
+ actions['cate_10_type3'] + actions['cate_11_type3'])
actions['cate8_type4_percentage'] = np.log(1 + actions['cate_8_type4']) - np.log(
1 + actions['cate_8_type4'] + actions['cate_4_type4'] + actions['cate_5_type4']
+ actions['cate_6_type4'] + actions['cate_7_type4'] + actions['cate_9_type4']
+ actions['cate_10_type4'] + actions['cate_11_type4'])
actions['cate8_type5_percentage'] = np.log(1 + actions['cate_8_type5']) - np.log(
1 + actions['cate_8_type5'] + actions['cate_4_type5'] + actions['cate_5_type5']
+ actions['cate_6_type5'] + actions['cate_7_type5'] + actions['cate_9_type5']
+ actions['cate_10_type5'] + actions['cate_11_type5'])
actions['cate8_type6_percentage'] = np.log(1 + actions['cate_8_type6']) - np.log(
1 + actions['cate_8_type6'] + actions['cate_4_type6'] + actions['cate_5_type6']
+ actions['cate_6_type6'] + actions['cate_7_type6'] + actions['cate_9_type6']
+ actions['cate_10_type6'] + actions['cate_11_type6'])
actions['user_id'] = actions.index
actions = actions[['user_id', 'cate8_percentage', 'cate4_percentage', 'cate5_percentage', 'cate6_percentage',
'cate7_percentage', 'cate9_percentage', 'cate10_percentage', 'cate11_percentage', 'cate8_type1_percentage',
'cate8_type2_percentage', 'cate8_type3_percentage', 'cate8_type4_percentage', 'cate8_type5_percentage', 'cate8_type6_percentage']]
actions.reset_index(inplace = True, drop = True)
return actions
5.7 累积商品特征
def get_accumulate_product_feat(start_date, end_date, all_actions):
actions = get_time_action(start_date, end_date, all_actions)
df = pd.get_dummies(actions['type'], prefix = 'product_action')
# 按照商品-日期分组,计算某个时间段该商品的各项行为的标准差
actions['date'] = pd.to_datetime(actions['time']).apply(lambda x: x.date())
actions = pd.concat([actions[['sku_id', 'date']], df], axis = 1)
actions = actions.groupby(['sku_id'], as_index = False).sum()
days_interal = (datetime.strptime(end_date, '%Y-%m-%d') - datetime.strptime(start_date, '%Y-%m-%d')).days
actions['product_action_1_ratio'] = np.log(1+ actions['product_action_4.0']) - np.log(1 + actions['product_action_1.0'])
actions['product_action_2_ratio'] = np.log(1+ actions['product_action_4.0']) - np.log(1 + actions['product_action_2.0'])
actions['product_action_3_ratio'] = np.log(1+ actions['product_action_4.0']) - np.log(1 + actions['product_action_3.0'])
actions['product_action_4_ratio'] = np.log(1+ actions['product_action_4.0']) - np.log(1 + actions['product_action_4.0'])
actions['product_action_6_ratio'] = np.log(1+ actions['product_action_4.0']) - np.log(1 + actions['product_action_6.0'])
# 计算各种行为的均值
actions['product_action_1_mean']= actions['product_action_1.0'] / days_interal
actions['product_action_2_mean']= actions['product_action_2.0'] / days_interal
actions['product_action_3_mean']= actions['product_action_3.0'] / days_interal
actions['product_action_4_mean']= actions['product_action_4.0'] / days_interal
actions['product_action_5_mean']= actions['product_action_5.0'] / days_interal
actions['product_action_6_mean']= actions['product_action_6.0'] / days_interal
return actions
5.8 类别特征
def get_accumulate_cate_feat(start_date, end_date, all_actions):
actions = get_time_action(start_date, end_date, all_actions)
actions['date'] = pd.to_datetime(actions['time']).apply(lambda x: x.date())
df = pd.get_dummies(actions['type'], prefix = 'cate_action')
actions = pd.concat([actions[['cate', 'date']], df], axis = 1)
# 按照类别分组,统计各个商品类别下行为的转化率
actions = actions.groupby('cate', as_index = False).sum()
days_interal = (datetime.strptime(end_date, '%Y-%m-%d') - datetime.strptime(start_date, '%Y-%m-%d')).days
actions['cate_action_1_ratio'] = np.log(1 + actions['cate_action_4.0']) - np.log(1 + actions['cate_action_1.0'])
actions['cate_action_2_ratio'] = np.log(1 + actions['cate_action_4.0']) - np.log(1 + actions['cate_action_2.0'])
actions['cate_action_3_ratio'] = np.log(1 + actions['cate_action_4.0']) - np.log(1 + actions['cate_action_3.0'])
actions['cate_action_5_ratio'] = np.log(1 + actions['cate_action_4.0']) - np.log(1 + actions['cate_action_5.0'])
actions['cate_action_6_ratio'] = np.log(1 + actions['cate_action_4.0']) - np.log(1 + actions['cate_action_6.0'])
# 按照类别分组,统计各个商品类别下行为在一段时间的均值
actions['cate_action_1_mean'] = actions['cate_action_1.0'] / days_interal
actions['cate_action_2_mean'] = actions['cate_action_2.0'] / days_interal
actions['cate_action_3_mean'] = actions['cate_action_3.0'] / days_interal
actions['cate_action_4_mean'] = actions['cate_action_4.0'] / days_interal
actions['cate_action_5_mean'] = actions['cate_action_5.0'] / days_interal
actions['cate_action_6_mean'] = actions['cate_action_6.0'] / days_interal
return actions
六. 构造训练集/测试集
6.1 标签
def get_labels(start_date, end_date, all_actions):
actions = get_time_action(start_date, end_date, all_actions)
actions = actions[(actions['type'] == 4) & (actions['cate'] == 8)]
actions = actions.groupby(['user_id', 'sku_id'], as_index = False).sum()
actions['label'] = 1
actions = actions[['user_id', 'sku_id', 'label']]
return actions
6.2 构造测试集
def make_actions(user, product, all_actions, train_start_date):
train_end_date = datetime.strptime(train_start_date, '%Y-%m-%d') + timedelta(days = 3)
train_end_date = train_end_date.strftime('%Y-%m-%d')
print(train_end_date)
start_days = datetime.strptime(train_end_date, '%Y-%m-%d') - timedelta(days = 30)
start_days = start_days.strftime('%Y-%m-%d')
user_acc = get_recent_user_feat(train_end_date, all_actions) # 用户近期行为特征
user_cate = get_user_cate_feature(train_start_date, train_end_date, all_actions) # 用户对同类别下各种商品的行为特征
product_acc = get_accumulate_product_feat(start_days, train_end_date, all_actions) # 累积商品特征
cate_acc = get_accumulate_cate_feat(start_days, train_end_date, all_actions) # 类别特征
comment_acc = get_comments_product_feat(train_end_date) # 评论特征
# 标记
test_start_date = train_end_date
test_end_date = datetime.strptime(test_start_date, '%Y-%m-%d') + timedelta(days = 5)
test_end_date = test_end_date.strftime('%Y-%m-%d')
labels = get_labels(test_start_date, test_end_date, all_actions)
actions = None
for i in (3, 5, 7, 10, 15, 21, 30):
start_days = datetime.strptime(train_end_date, '%Y-%m-%d') - timedelta(days = i)
start_days = start_days.strftime('%Y-%m-%d')
if actions is None:
actions = get_action_feat(start_days, train_end_date, all_actions, i)
else:
actions = pd.merge(actions, get_action_feat(start_days, train_end_date, all_actions, i), how = 'left',
on = ['user_id', 'sku_id', 'cate'])
actions = pd.merge(actions, user, how = 'left', on = 'user_id')
actions = pd.merge(actions, user_acc, how = 'left', on = 'user_id')
actions = pd.merge(actions, user_cate, how = 'left', on = 'user_id')
actions = pd.merge(actions, product, how = 'left', on = ['sku_id', 'cate'])
actions = pd.merge(actions, product_acc, how = 'left', on = 'sku_id')
actions = pd.merge(actions, cate_acc, how = 'left', on = 'cate')
actions = pd.merge(actions, comment_acc, how = 'left', on = 'sku_id')
actions = pd.merge(actions, labels, how = 'left', on = ['user_id', 'sku_id'])
actions = actions.fillna(0)
action_postive = actions[actions['label'] == 1]
action_negative = actions[actions['label'] == 0]
del actions
neg_len = len(action_postive) * 10
action_negative = action_negative.sample(n = neg_len)
action_sample = pd.concat([action_postive, action_negative], ignore_index = True)
return action_sample
def make_train_set(train_start_date, setNums, f_path, all_actions):
train_actions = None
user = get_basic_user_feat()
product = get_basic_product_feat()
for i in range(setNums):
if train_actions is None:
train_actions = make_actions(user, product, all_actions, train_start_date)
else:
train_actions = pd.concat([train_actions, make_actions(user, product, all_actions, train_start_date)], ignore_index = True)
# 接下来每次移动一天
train_start_date = datetime.strptime(train_start_date, '%Y-%m-%d') + timedelta(days = 1)
train_start_date = train_start_date.strftime('%Y-%m-%d')
print('Round {0} / {1} over!'.format(i+1, setNums))
train_actions.to_csv(f_path, index = False)
train_start_date = '2016-02-01'
make_train_set(train_start_date, 20, 'train_set.csv',all_actions)
6.3 构造验证集(线下测试集)
def make_val_answer(val_start_date, val_end_date, all_actions, label_val_s1_path):
actions = get_time_action(val_start_date, val_end_date, all_actions)
actions = actions[(actions['type'] == 4) & (actions['cate'] == 8)]
actions = actions[['user_id', 'sku_id']]
actions = actions.drop_duplicates()
actions.to_csv(label_val_s1_path, index = False)
def make_val_set(train_start_date, train_end_date, val_s1_path):
start_days = datetime.strptime(train_end_date, '%Y-%m-%d') - timedelta(days = 30)
start_days = start_days.strftime('%Y-%m-%d')
all_actions = get_all_action()
user = get_basic_user_feat() # 用户基本特征
product = get_basic_product_feat() # 商品基本特征
user_acc = get_recent_user_feat(train_end_date, all_actions)
user_cate = get_user_cate_feature(train_start_date, train_end_date, all_actions)
product_acc = get_accumulate_product_feat(start_days, train_end_date, all_actions)
cate_acc = get_accumulate_cate_feat(start_days, train_end_date, all_actions)
comment_acc = get_comments_product_feat(train_end_date)
actions = None
for i in (3, 5, 7, 10, 15, 21, 30):
start_days = datetime.strptime(train_end_date, '%Y-%m-%d') - timedelta(days = i)
start_days = start_days.strftime('%Y-%m-%d')
if actions is None:
actions = get_action_feat(start_days, train_end_date, all_actions, i)
else:
actions = pd.merge(actions, get_action_feat(start_days, train_end_date, all_actions, i),
how = 'left', on = ['user_id', 'sku_id', 'cate'])
actions = pd.merge(actions, user, how = 'left', on = 'user_id')
actions = pd.merge(actions, user_acc, how = 'left', on = 'user_id')
actions = pd.merge(actions, user_cate, how = 'left', on = 'user_id')
actions = pd.merge(actions, product, how = 'left', on = ['sku_id', 'cate'])
actions = pd.merge(actions, product_acc, how = 'left', on = 'sku_id')
actions = pd.merge(actions, cate_acc, how = 'left', on = 'cate')
actions = pd.merge(actions, comment_acc, how = 'left', on = 'sku_id')
actions = actions.fillna(0)
val_start_date = train_end_date
val_end_date = datetime.strptime(val_start_date, '%Y-%m-%d') + timedelta(days = 5)
val_end_date = val_end_date.strftime('%Y-%m-%d')
make_val_answer(val_start_date, val_end_date, all_actions, 'label_' + val_s1_path)
actions.to_csv(val_s1_path, index = False)
make_val_set('2016-02-21', '2016-02-24', 'val_1.csv')
6.4 构造测试集
def make_test_set(train_start_date, train_end_date):
start_days = datetime.strptime(train_end_date, '%Y-%m-%d') - timedelta(days = 30)
start_days = start_days.strftime('%Y-%m-%d')
all_actions = get_all_action()
user = get_basic_user_feat()
product = get_basic_product_feat()
user_acc = get_recent_user_feat(train_end_date, all_actions)
user_cate = get_user_cate_feature(train_start_date, train_end_date, all_actions)
product_acc = get_accumulate_product_feat(start_days, train_end_date, all_actions)
cate_acc = get_accumulate_cate_feat(start_days, train_end_date, all_actions)
comment_acc = get_comments_product_feat(train_end_date)
actions = None
for i in (3, 5, 7, 10, 15, 21, 30):
start_days = datetime.strptime(train_end_date, '%Y-%m-%d') - timedelta(days = i)
start_days = start_days.strftime('%Y-%m-%d')
if actions is None:
actions = get_action_feat(start_days, train_end_date, all_actions, i)
else:
actions = pd.merge(actions, get_action_feat(start_days, train_end_date, all_actions, i),
how = 'left', on = ['user_id', 'sku_id', 'cate'])
actions = pd.merge(actions, user, how = 'left', on = 'user_id')
actions = pd.merge(actions, user_acc, how = 'left', on = 'user_id')
actions = pd.merge(actions, user_cate, how = 'left', on = 'user_id')
actions = pd.merge(actions, product, how = 'left', on = ['sku_id', 'cate'])
actions = pd.merge(actions, product_acc, how = 'left', on = 'sku_id')
actions = pd.merge(actions, cate_acc, how = 'left', on = 'cate')
actions = pd.merge(actions, comment_acc, how = 'left', on = 'sku_id')
actions = actions.fillna(0)
actions.to_csv('test_set.csv', index = False)
make_test_set('2016-04-13', '2016-04-16')
七. Xgboost建模
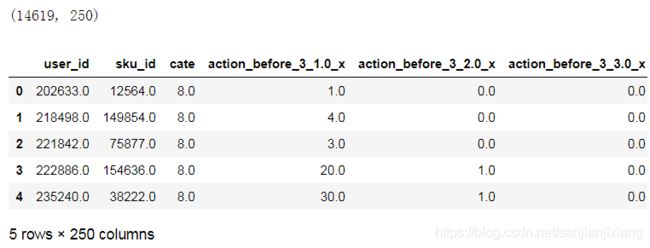
data = pd.read_csv('train_set.csv')
data_x = data.loc[:, data.columns != 'label']
data_y = data.loc[:, data.columns == 'label']
print(data_x.shape)
data_x.head()
from sklearn.model_selection import train_test_split
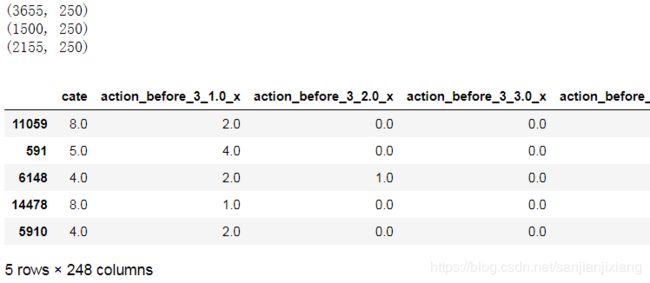
x_train, x_test, y_train, y_test = train_test_split(data_x, data_y, test_size = 0.25, random_state = 42)
print(x_test.shape)
x_val = x_test.iloc[:1500, :]
y_val = y_test.iloc[:1500, :]
print(x_val.shape)
x_test = x_test.iloc[1500:, :]
y_test = y_test.iloc[1500:, :]
print(x_test.shape)
del x_train['user_id']
del x_train['sku_id']
del x_val['user_id']
del x_val['sku_id']
x_train.head()
import xgboost as xgb
dtrain = xgb.DMatrix(x_train, label = y_train)
dvalid = xgb.DMatrix(x_val, label = y_val)
param = {'n_estimators': 4000, 'max_depth': 3, 'min_child_weight': 5, 'gamma': 0,
'subsample': 1.0, 'colsample_bytree': 0.8, 'scale_pos_weight':10,
'eta': 0.1, 'silent': 1, 'objective': 'binary:logistic','eval_metric':'auc'}
num_round = param['n_estimators']
plst = param.items()
evallist = [(dtrain, 'train'), (dvalid, 'eval')]
bst = xgb.train(plst, dtrain, num_round, evallist, early_stopping_rounds = 10)
bst.save_model('bst.model')
bst.attributes()
{‘best_iteration’: ‘125’, ‘best_msg’: ‘[125]\ttrain-auc:0.984232\teval-auc:0.972103’,
‘best_score’: ‘0.972103’}
def create_feature_map(featrues):
outfile = open(r'xgb.fmap', 'w')
i = 0
for feat in features:
outfile.write('{0} \t {1} \tq\n'.format(i, feat))
i += 1
outfile.close()
features = list(x_train.columns[:])
create_feature_map(features)
import operator
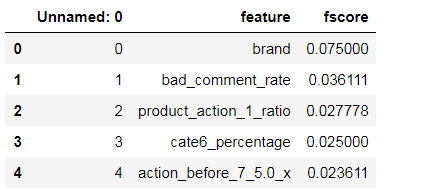
def feature_importance(bst_xgb):
importance = bst_xgb.get_fscore(fmap = r'xgb.fmap')
importance = sorted(importance.items(), key = operator.itemgetter(1), reverse = True)
df = pd.DataFrame(importance, columns = ['feature', 'fscore'])
df['fscore'] = df['fscore'] / df['fscore'].sum()
file_name = 'feature_importance_' + str(datetime.now().date())[5:] + '.csv'
df.to_csv(file_name)
feature_importance(bst)
importances = pd.read_csv('feature_importance_06-21.csv')
importances.sort_values('fscore', inplace = True, ascending = False)
importances.head()
users = x_test[['user_id', 'sku_id', 'cate']].copy()
del x_test['user_id']
del x_test['sku_id']
x_test_DMatrix = xgb.DMatrix(x_test)
y_pred = bst.predict(x_test_DMatrix, ntree_limit = bst.best_ntree_limit)
x_test['pred_label'] = y_pred
x_test.head()
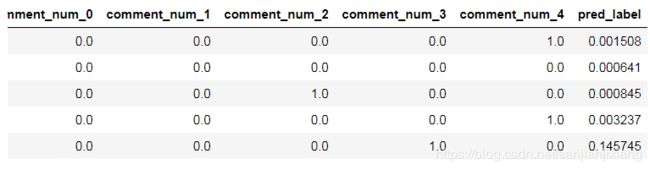
def label(column):
if column['pred_label'] > 0.5:
column['pred_label'] = 1
else:
column['pred_label'] = 0
return column
x_test = x_test.apply(label, axis = 1)
x_test.head()
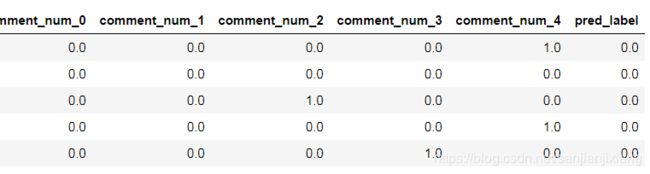
x_test['true_label'] = y_test
x_test.head()
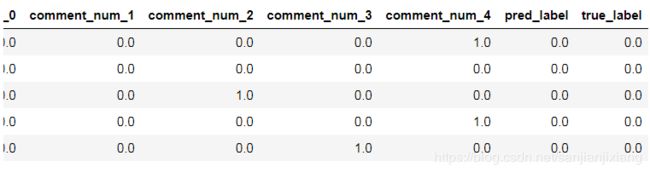
x_test['user_id'] = users['user_id']
x_test['sku_id'] = users['sku_id']
# 所有购买用户
all_user_set = x_test[x_test['true_label'] == 1]['user_id'].unique()
print(len(all_user_set))
# 所有预测购买的用户
all_user_test_set = x_test[x_test['pred_label'] == 1]['user_id'].unique()
print(len(all_user_test_set))
all_user_test_item_pair = x_test[x_test['pred_label'] == 1]['user_id'].map(str) + '-' + x_test[x_test['pred_label'] == 1]['sku_id'].map(str)
all_user_test_item_pair = np.array(all_user_test_item_pair)
print(len(all_user_test_item_pair))
188
366
394
pos, neg = 0, 0
for user_id in all_user_test_set:
if user_id in all_user_set:
pos += 1
else:
neg += 1
all_user_acc = 1.0 * pos / (pos + neg)
all_user_recall = 1.0 * pos / len(all_user_set)
print('所有用户中预测购买用户的准确率为 ' + str(all_user_acc))
print('所有用户中预测购买用户的召回率为 ' + str(all_user_recall))
所有用户中预测购买用户的准确率为 0.48633879781420764
所有用户中预测购买用户的召回率为 0.9468085106382979
#所有实际商品对
all_user_item_pair = x_test[x_test['true_label'] == 1]['user_id'].map(str) + '-' + x_test[x_test['true_label'] == 1]['sku_id'].map(str)
all_user_item_pair = np.array(all_user_item_pair)
# print(len(all_user_item_pair))
pos, neg = 0, 0
for user_item_pair in all_user_test_item_pair:
print(user_item_pair)
if user_item_pair in all_user_item_pair:
pos += 1
else:
neg += 1
all_item_acc = 1.0 * pos / (pos + neg)
all_item_recall = 1.0 * pos / len(all_user_item_pair)
print('所有用户中预测购买用户的准确率为 ' + str(all_item_acc))
print('所有用户中预测购买用户的召回率为 ' + str(all_item_recall))
F1 = 6.0 * all_user_recall * all_user_acc / (5.0 * all_user_recall + all_user_acc)
F2 = 5.0 * all_item_acc * all_item_recall / (2.0 * all_item_recall + 3.0 * all_item_acc)
score = 0.4 * F1 + 0.6 * F2
print('F1 = ' + str(F1))
print('F2 = ' + str(F2))
print('score = ' + str(score))
所有用户中预测购买用户的准确率为 0.5177664974619289
所有用户中预测购买用户的召回率为 0.9532710280373832
F1 = 0.5292368681863231
F2 = 0.7132867132867132
score = 0.6396667752465572