JD用户购买意向预测-数据发掘
(一)任务描述:

数据集: 京东2016年算法比赛数据集
过程描述: 通过数据挖掘的技术可视化技术,输出高潜用户和目标商品的匹配结果,为精准营销提供高质量的目标群体。
数据集描述:
JData_User.csv 用户数据集 105,321个用户
JData_Comment.csv 商品评论 558,552条记录
JData_Product.csv 预测商品集合 24,187条记录
JData_Action_201602.csv 2月份行为交互记录 11,485,424条记录
JData_Action_201603.csv 3月份行为交互记录 25,916,378条记录
JData_Action_201604.csv 4月份行为交互记录 13,199,934条记录


(二)数据清洗
导入相关包
import pandas as pd
import numpy as np
from collections import Counter
1.首先检查JData_User中的用户和JData_Action中的用户是否一致
保证行为数据中的所产生的行为均由用户数据中的用户产生(但是可能存在用户在行为数据中无行为)
def user_action_check():
df_user = pd.read_csv('data/JData_User.csv',encoding='gbk')
df_sku = df_user.loc[:,'user_id'].to_frame()
df_month2 = pd.read_csv('data/JData_Action_201602.csv',encoding='gbk')
print ('Is action of Feb. from User file? ', len(df_month2) == len(pd.merge(df_sku,df_month2)))
df_month3 = pd.read_csv('data/JData_Action_201603.csv',encoding='gbk')
print ('Is action of Mar. from User file? ', len(df_month3) == len(pd.merge(df_sku,df_month3)))
df_month4 = pd.read_csv('data/JData_Action_201604.csv',encoding='gbk')
print ('Is action of Apsr. from User file? ', len(df_month4) == len(pd.merge(df_sku,df_month4)))
user_action_check()
out:
Is action of Feb. from User file? True
Is action of Mar. from User file? True
Is action of Apr. from User file? True
结论: User数据集中的用户和交互行为数据集中的用户完全一致
2.检查是否有重复记录
除去各个数据文件中完全重复的记录,可能解释是重复数据是有意义的,比如用户同时购买多件商品,同时添加多个数量的商品到购物车等…
def deduplicate(filepath, filename, newpath):
df_file = pd.read_csv(filepath,encoding='gbk')
before = df_file.shape[0]
df_file.drop_duplicates(inplace=True)
after = df_file.shape[0]
n_dup = before-after
print ('No. of duplicate records for ' + filename + ' is: ' + str(n_dup))
if n_dup != 0:
df_file.to_csv(newpath, index=None)
else:
print ('no duplicate records in ' + filename)
deduplicate('data/JData_Action_201602.csv', 'Feb. action', 'data/JData_Action_201602_dedup.csv')
deduplicate('data/JData_Action_201603.csv', 'Mar. action', 'data/JData_Action_201603_dedup.csv')
deduplicate('data/JData_Action_201604.csv', 'Feb. action', 'data/JData_Action_201604_dedup.csv')
deduplicate('data/JData_Comment.csv', 'Comment', 'data/JData_Comment_dedup.csv')
deduplicate('data/JData_Product.csv', 'Product', 'data/JData_Product_dedup.csv')
deduplicate('data/JData_User.csv', 'User', 'data/JData_User_dedup.csv')
检查重复数据:
df_month2 = pd.read_csv('data/JData_Action_201602.csv',encoding='gbk')
IsDuplicated = df_month2.duplicated()
df_d=df_month2[IsDuplicated]
df_d.groupby('type').count()
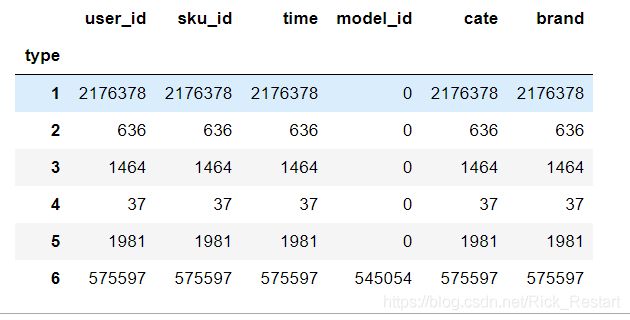
发现重复数据大多数都是由于浏览(1),或者点击(6)产生
3.行为数据中的user_id为浮点型,进行INT类型转换
df_month = pd.read_csv('data\JData_Action_201602.csv',encoding='gbk')
df_month['user_id'] = df_month['user_id'].apply(lambda x:int(x))
print (df_month['user_id'].dtype)
df_month.to_csv('data\JData_Action_201602.csv',index=None)
df_month = pd.read_csv('data\JData_Action_201603.csv',encoding='gbk')
df_month['user_id'] = df_month['user_id'].apply(lambda x:int(x))
print (df_month['user_id'].dtype)
df_month.to_csv('data\JData_Action_201603.csv',index=None)
df_month = pd.read_csv('data\JData_Action_201604.csv',encoding='gbk')
df_month['user_id'] = df_month['user_id'].apply(lambda x:int(x))
print (df_month['user_id'].dtype)
df_month.to_csv('data\JData_Action_201604.csv',index=None)
4.年龄区间的处理
df_user = pd.read_csv('data\JData_User.csv',encoding='gbk')
def tranAge(x):
if x == u'15岁以下':
x='1'
elif x==u'16-25岁':
x='2'
elif x==u'26-35岁':
x='3'
elif x==u'36-45岁':
x='4'
elif x==u'46-55岁':
x='5'
elif x==u'56岁以上':
x='6'
return x
df_user['age']=df_user['age'].apply(tranAge)
print (df_user.groupby(df_user['age']).count())
df_user.to_csv('data\JData_User.csv',index=None)

为了能够进行上述清洗,在此首先构造了简单的用户(user)行为特征和商品(item)行为特征,对应于两张表user_table和item_table:
user_table特征包括:
- user_id(用户id),age(年龄),sex(性别),
- user_lv_cd(用户级别),browse_num(浏览数),
- addcart_num(加购数),delcart_num(删购数),
- buy_num(购买数),favor_num(收藏数),
- click_num(点击数),buy_addcart_ratio(购买加购转化率),
- buy_browse_ratio(购买浏览转化率),
- buy_click_ratio(购买点击转化率),
- buy_favor_ratio(购买收藏转化率)
item_table特征包括:
- sku_id(商品id),attr1,attr2,
- attr3,cate,brand,browse_num,
- addcart_num,delcart_num,
- buy_num,favor_num,click_num,
- buy_addcart_ratio,buy_browse_ratio,
- buy_click_ratio,buy_favor_ratio,
- comment_num(评论数),
- has_bad_comment(是否有差评),
- bad_comment_rate(差评率)
#定义文件名
ACTION_201602_FILE = "data/JData_Action_201602.csv"
ACTION_201603_FILE = "data/JData_Action_201603.csv"
ACTION_201604_FILE = "data/JData_Action_201604.csv"
COMMENT_FILE = "data/JData_Comment.csv"
PRODUCT_FILE = "data/JData_Product.csv"
USER_FILE = "data/JData_User.csv"
USER_TABLE_FILE = "data/User_table.csv"
ITEM_TABLE_FILE = "data/Item_table.csv"
# 功能函数: 对每一个user分组的数据进行统计
def add_type_count(group):
behavior_type = group.type.astype(int)
# 用户行为类别
type_cnt = Counter(behavior_type)
# 1: 浏览 2: 加购 3: 删除
# 4: 购买 5: 收藏 6: 点击
group['browse_num'] = type_cnt[1]
group['addcart_num'] = type_cnt[2]
group['delcart_num'] = type_cnt[3]
group['buy_num'] = type_cnt[4]
group['favor_num'] = type_cnt[5]
group['click_num'] = type_cnt[6]
return group[['user_id', 'browse_num', 'addcart_num',
'delcart_num', 'buy_num', 'favor_num',
'click_num']]
由于用户行为数据量较大,一次性读入可能造成内存错误(Memory Error),因而使用pandas的分块(chunk)读取
#对action数据进行统计
#根据自己调节chunk_size大小
def get_from_action_data(fname, chunk_size=50000):
reader = pd.read_csv(fname, header=0, iterator=True,encoding='gbk')
chunks = []
loop = True
while loop:
try:
# 只读取user_id和type两个字段
chunk = reader.get_chunk(chunk_size)[["user_id", "type"]]
chunks.append(chunk)
except StopIteration:
loop = False
print("Iteration is stopped")
# 将块拼接为pandas dataframe格式
df_ac = pd.concat(chunks, ignore_index=True)
# 按user_id分组,对每一组进行统计,as_index 表示无索引形式返回数据
df_ac = df_ac.groupby(['user_id'], as_index=False).apply(add_type_count)
# 将重复的行丢弃
df_ac = df_ac.drop_duplicates('user_id')
return df_ac
将各个action数据的统计量进行聚合
主要观察行为对转化率的影响
def merge_action_data():
df_ac = []
df_ac.append(get_from_action_data(fname=ACTION_201602_FILE))
df_ac.append(get_from_action_data(fname=ACTION_201603_FILE))
df_ac.append(get_from_action_data(fname=ACTION_201604_FILE))
df_ac = pd.concat(df_ac, ignore_index=True)
# 用户在不同action表中统计量求和
df_ac = df_ac.groupby(['user_id'], as_index=False).sum()
# 构造转化率字段
df_ac['buy_addcart_ratio'] = df_ac['buy_num'] / df_ac['addcart_num']
df_ac['buy_browse_ratio'] = df_ac['buy_num'] / df_ac['browse_num']
df_ac['buy_click_ratio'] = df_ac['buy_num'] / df_ac['click_num']
df_ac['buy_favor_ratio'] = df_ac['buy_num'] / df_ac['favor_num']
# 将大于1的转化率字段置为1(100%)
df_ac.ix[df_ac['buy_addcart_ratio'] > 1., 'buy_addcart_ratio'] = 1.
df_ac.ix[df_ac['buy_browse_ratio'] > 1., 'buy_browse_ratio'] = 1.
df_ac.ix[df_ac['buy_click_ratio'] > 1., 'buy_click_ratio'] = 1.
df_ac.ix[df_ac['buy_favor_ratio'] > 1., 'buy_favor_ratio'] = 1.
return df_ac
从FJData_User表中抽取需要的字段
def get_from_jdata_user():
df_usr = pd.read_csv(USER_FILE, header=0)
df_usr = df_usr[["user_id", "age", "sex", "user_lv_cd"]]
return df_usr
user_base = get_from_jdata_user()
user_behavior = merge_action_data()
连接成一张表,类似于SQL的左连接(left join)
user_behavior = pd.merge(user_base, user_behavior, on=['user_id'], how='left')
# 保存为user_table.csv
user_behavior.to_csv(USER_TABLE_FILE, index=False)
user_table = pd.read_csv(USER_TABLE_FILE)
user_table.head()

构建Item_table
读取Product中商品
def get_from_jdata_product():
df_item = pd.read_csv(PRODUCT_FILE, header=0,encoding='gbk')
return df_item
对每一个商品分组进行统计
def add_type_count(group):
behavior_type = group.type.astype(int)
type_cnt = Counter(behavior_type)
group['browse_num'] = type_cnt[1]
group['addcart_num'] = type_cnt[2]
group['delcart_num'] = type_cnt[3]
group['buy_num'] = type_cnt[4]
group['favor_num'] = type_cnt[5]
group['click_num'] = type_cnt[6]
return group[['sku_id', 'browse_num', 'addcart_num',
'delcart_num', 'buy_num', 'favor_num',
'click_num']]
对action中的数据进行统计
def get_from_action_data(fname, chunk_size=50000):
reader = pd.read_csv(fname, header=0, iterator=True)
chunks = []
loop = True
while loop:
try:
chunk = reader.get_chunk(chunk_size)[["sku_id", "type"]]
chunks.append(chunk)
except StopIteration:
loop = False
print("Iteration is stopped")
df_ac = pd.concat(chunks, ignore_index=True)
df_ac = df_ac.groupby(['sku_id'], as_index=False).apply(add_type_count)
# Select unique row
df_ac = df_ac.drop_duplicates('sku_id')
return df_ac
#获取评论中的商品数据,如果存在某一个商品有两个日期的评论,取最晚的那一个
def get_from_jdata_comment():
df_cmt = pd.read_csv(COMMENT_FILE, header=0)
df_cmt['dt'] = pd.to_datetime(df_cmt['dt'])
# find latest comment index
idx = df_cmt.groupby(['sku_id'])['dt'].transform(max) == df_cmt['dt']
df_cmt = df_cmt[idx]
return df_cmt[['sku_id', 'comment_num',
'has_bad_comment', 'bad_comment_rate']]
def merge_action_data():
df_ac = []
df_ac.append(get_from_action_data(fname=ACTION_201602_FILE))
df_ac.append(get_from_action_data(fname=ACTION_201603_FILE))
df_ac.append(get_from_action_data(fname=ACTION_201604_FILE))
df_ac = pd.concat(df_ac, ignore_index=True)
df_ac = df_ac.groupby(['sku_id'], as_index=False).sum()
df_ac['buy_addcart_ratio'] = df_ac['buy_num'] / df_ac['addcart_num']
df_ac['buy_browse_ratio'] = df_ac['buy_num'] / df_ac['browse_num']
df_ac['buy_click_ratio'] = df_ac['buy_num'] / df_ac['click_num']
df_ac['buy_favor_ratio'] = df_ac['buy_num'] / df_ac['favor_num']
df_ac.ix[df_ac['buy_addcart_ratio'] > 1., 'buy_addcart_ratio'] = 1.
df_ac.ix[df_ac['buy_browse_ratio'] > 1., 'buy_browse_ratio'] = 1.
df_ac.ix[df_ac['buy_click_ratio'] > 1., 'buy_click_ratio'] = 1.
df_ac.ix[df_ac['buy_favor_ratio'] > 1., 'buy_favor_ratio'] = 1.
return df_ac
item_base = get_from_jdata_product()
item_behavior = merge_action_data()
item_comment = get_from_jdata_comment()
# SQL: left join
item_behavior = pd.merge(
item_base, item_behavior, on=['sku_id'], how='left')
item_behavior = pd.merge(
item_behavior, item_comment, on=['sku_id'], how='left')
item_behavior.to_csv(ITEM_TABLE_FILE, index=False)
item_table = pd.read_csv(ITEM_TABLE_FILE)
item_table.head()
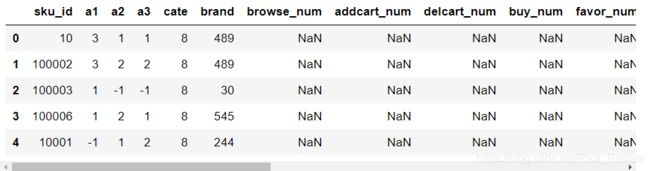
出现太多nan主要是该商品并没有被用户点击浏览等行为。
5.用户清洗
df_user = pd.read_csv('data/User_table.csv',header=0)
pd.options.display.float_format = '{:,.3f}'.format #输出格式设置,保留三位小数
df_user.describe()
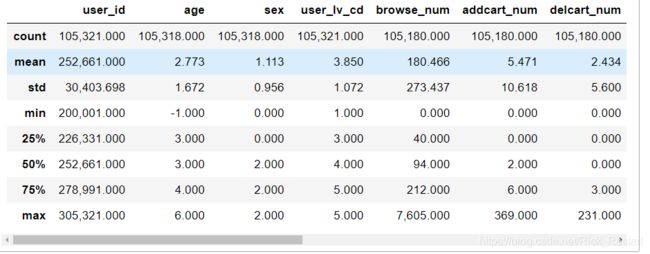
由上述统计信息发现: 第一行中根据User_id统计发现有105321个用户,发现有3个用户没有age,sex字段,而且根据浏览、加购、删购、购买等记录却只有105180条记录,说明存在用户无任何交互记录,因此可以删除上述用户。
删除没有age,sex字段的用户
df_user[df_user['age'].isnull()]
delete_list = df_user[df_user['age'].isnull()].index
df_user.drop(delete_list,axis=0,inplace=True)
删除无交互记录的用户
df_naction = df_user[(df_user['browse_num'].isnull()) & (df_user['addcart_num'].isnull()) & (df_user['delcart_num'].isnull()) & (df_user['buy_num'].isnull()) & (df_user['favor_num'].isnull()) & (df_user['click_num'].isnull())]
df_user.drop(df_naction.index,axis=0,inplace=True)
print (len(df_user))
out: 75694
删除无购买记录的用户
df_user = df_user[df_user['buy_num']!=0]
df_user.describe()

删除爬虫及惰性用户
由上表所知,浏览购买转换比和点击购买转换比均值为0.018,0.030。这里假设浏览购买转换比和点击购买转换比小于0.0005的用户为惰性用户
bindex = df_user[df_user['buy_browse_ratio']<0.0005].index
print (len(bindex))
df_user.drop(bindex,axis=0,inplace=True)
out:90
cindex = df_user[df_user['buy_click_ratio']<0.0005].index
print (len(cindex))
df_user.drop(cindex,axis=0,inplace=True)
out:323
df_user.describe()

最后这29070个用户为最终预测用户数据集
(三)数据可视化
# 导入相关包
%matplotlib inline
# 绘图包
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
#定义文件名
ACTION_201602_FILE = "data/JData_Action_201602.csv"
ACTION_201603_FILE = "data/JData_Action_201603.csv"
ACTION_201604_FILE = "data/JData_Action_201604.csv"
COMMENT_FILE = "data/JData_Comment.csv"
PRODUCT_FILE = "data/JData_Product.csv"
USER_FILE = "data/JData_User.csv"
USER_TABLE_FILE = "data/User_table.csv"
ITEM_TABLE_FILE = "data/Item_table.csv"
1.观察周一到周日各天购买情况
提取购买(type=4)的行为数据
def get_from_action_data(fname, chunk_size=50000):
reader = pd.read_csv(fname, header=0, iterator=True)
chunks = []
loop = True
while loop:
try:
chunk = reader.get_chunk(chunk_size)[
["user_id", "sku_id", "type", "time"]]
chunks.append(chunk)
except StopIteration:
loop = False
print("Iteration is stopped")
df_ac = pd.concat(chunks, ignore_index=True)
# type=4,为购买
df_ac = df_ac[df_ac['type'] == 4]
return df_ac[["user_id", "sku_id", "time"]]
df_ac = []
df_ac.append(get_from_action_data(fname=ACTION_201602_FILE))
df_ac.append(get_from_action_data(fname=ACTION_201603_FILE))
df_ac.append(get_from_action_data(fname=ACTION_201604_FILE))
df_ac = pd.concat(df_ac, ignore_index=True)
print(df_ac.dtypes)

将time字段转换为datetime类型
使用lambda匿名函数将时间time转换为星期(周一为1, 周日为7)
df_ac['time'] = pd.to_datetime(df_ac['time'])
df_ac['time'] = df_ac['time'].apply(lambda x: x.weekday() + 1)
df_ac.head()
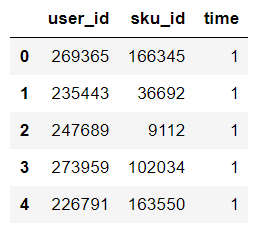
周一到周日每天购买的用户个数
df_user = df_ac.groupby('time')['user_id'].nunique()
df_user = df_user.to_frame().reset_index()
df_user.columns = ['weekday', 'user_num']
周一到周日每天购买的商品个数
df_item = df_ac.groupby('time')['sku_id'].nunique()
df_item = df_item.to_frame().reset_index()
df_item.columns = ['weekday', 'item_num']
周一到周日每天购买记录个数
df_ui = df_ac.groupby('time', as_index=False).size()
df_ui = df_ui.to_frame().reset_index()
df_ui.columns = ['weekday', 'user_item_num']
画图:
# 条形宽度
bar_width = 0.2
# 透明度
opacity = 0.4
plt.bar(df_user['weekday'], df_user['user_num'], bar_width,
alpha=opacity, color='c', label='user')
plt.bar(df_item['weekday']+bar_width, df_item['item_num'],
bar_width, alpha=opacity, color='g', label='item')
plt.bar(df_ui['weekday']+bar_width*2, df_ui['user_item_num'],
bar_width, alpha=opacity, color='m', label='user_item')
plt.xlabel('weekday')
plt.ylabel('number')
plt.title('A Week Purchase Table')
plt.xticks(df_user['weekday'] + bar_width * 3 / 2., (1,2,3,4,5,6,7))
plt.tight_layout()
plt.legend(prop={'size':10})

分析:周六,周日购买的人数和购买记录都较少,购买商品数大体差不多
2.观察一个月中各天购买量
2016年2月
将time字段转换为datetime类型并使用lambda匿名函数将时间time转换为天
df_ac = get_from_action_data(fname=ACTION_201602_FILE)
df_ac['time'] = pd.to_datetime(df_ac['time']).apply(lambda x: x.day)
df_ac.head()

df_ac.tail()
df_user = df_ac.groupby('time')['user_id'].nunique()
df_user = df_user.to_frame().reset_index()
df_user.columns = ['day', 'user_num']
df_item = df_ac.groupby('time')['sku_id'].nunique()
df_item = df_item.to_frame().reset_index()
df_item.columns = ['day', 'item_num']
df_ui = df_ac.groupby('time', as_index=False).size()
df_ui = df_ui.to_frame().reset_index()
df_ui.columns = ['day', 'user_item_num']
# 条形宽度
bar_width = 0.2
# 透明度
opacity = 0.4
# 天数
day_range = range(1,len(df_user['day']) + 1, 1)
# 设置图片大小
plt.figure(figsize=(14,10))
plt.bar(df_user['day'], df_user['user_num'], bar_width,
alpha=opacity, color='c', label='user')
plt.bar(df_item['day']+bar_width, df_item['item_num'],
bar_width, alpha=opacity, color='g', label='item')
plt.bar(df_ui['day']+bar_width*2, df_ui['user_item_num'],
bar_width, alpha=opacity, color='m', label='user_item')
plt.xlabel('day')
plt.ylabel('number')
plt.title('February Purchase Table')
plt.xticks(df_user['day'] + bar_width * 3 / 2., day_range)
# plt.ylim(0, 80)
plt.tight_layout()
plt.legend(prop={'size':9})

分析: 2月份5,6,7,8,9,10 这几天购买量非常少,春节期间大部分快递不送导致购买量比较少。
2016年3月
df_ac = get_from_action_data(fname=ACTION_201603_FILE)
# 将time字段转换为datetime类型并使用lambda匿名函数将时间time转换为天
df_ac['time'] = pd.to_datetime(df_ac['time']).apply(lambda x: x.day)
df_user = df_ac.groupby('time')['user_id'].nunique()
df_user = df_user.to_frame().reset_index()
df_user.columns = ['day', 'user_num']
df_item = df_ac.groupby('time')['sku_id'].nunique()
df_item = df_item.to_frame().reset_index()
df_item.columns = ['day', 'item_num']
df_ui = df_ac.groupby('time', as_index=False).size()
df_ui = df_ui.to_frame().reset_index()
df_ui.columns = ['day', 'user_item_num']
# 条形宽度
bar_width = 0.2
# 透明度
opacity = 0.4
# 天数
day_range = range(1,len(df_user['day']) + 1, 1)
# 设置图片大小
plt.figure(figsize=(14,10))
plt.bar(df_user['day'], df_user['user_num'], bar_width,
alpha=opacity, color='c', label='user')
plt.bar(df_item['day']+bar_width, df_item['item_num'],
bar_width, alpha=opacity, color='g', label='item')
plt.bar(df_ui['day']+bar_width*2, df_ui['user_item_num'],
bar_width, alpha=opacity, color='m', label='user_item')
plt.xlabel('day')
plt.ylabel('number')
plt.title('March Purchase Table')
plt.xticks(df_user['day'] + bar_width * 3 / 2., day_range)
# plt.ylim(0, 80)
plt.tight_layout()
plt.legend(prop={'size':9})

分析:3月份14,15,16可能是315打假搞活动,导致购买量大增。购物记录多于2月份。
2016年4月
df_ac = get_from_action_data(fname=ACTION_201604_FILE)
# 将time字段转换为datetime类型并使用lambda匿名函数将时间time转换为天
df_ac['time'] = pd.to_datetime(df_ac['time']).apply(lambda x: x.day)
df_user = df_ac.groupby('time')['user_id'].nunique()
df_user = df_user.to_frame().reset_index()
df_user.columns = ['day', 'user_num']
df_item = df_ac.groupby('time')['sku_id'].nunique()
df_item = df_item.to_frame().reset_index()
df_item.columns = ['day', 'item_num']
df_ui = df_ac.groupby('time', as_index=False).size()
df_ui = df_ui.to_frame().reset_index()
df_ui.columns = ['day', 'user_item_num']
# 条形宽度
bar_width = 0.2
# 透明度
opacity = 0.4
# 天数
day_range = range(1,len(df_user['day']) + 1, 1)
# 设置图片大小
plt.figure(figsize=(14,10))
plt.bar(df_user['day'], df_user['user_num'], bar_width,
alpha=opacity, color='c', label='user')
plt.bar(df_item['day']+bar_width, df_item['item_num'],
bar_width, alpha=opacity, color='g', label='item')
plt.bar(df_ui['day']+bar_width*2, df_ui['user_item_num'],
bar_width, alpha=opacity, color='m', label='user_item')
plt.xlabel('day')
plt.ylabel('number')
plt.title('April Purchase Table')
plt.xticks(df_user['day'] + bar_width * 3 / 2., day_range)
# plt.ylim(0, 80)
plt.tight_layout()
plt.legend(prop={'size':9})

各个月都好像有商品销售量大增的样子。
商品类别销售统计
3.周一到周日各商品类别销售情况
跟上面代码类似
# 从行为记录中提取商品类别数据
def get_from_action_data(fname, chunk_size=50000):
reader = pd.read_csv(fname, header=0, iterator=True)
chunks = []
loop = True
while loop:
try:
chunk = reader.get_chunk(chunk_size)[
["cate", "brand", "type", "time"]]
chunks.append(chunk)
except StopIteration:
loop = False
print("Iteration is stopped")
df_ac = pd.concat(chunks, ignore_index=True)
# type=4,为购买
df_ac = df_ac[df_ac['type'] == 4]
return df_ac[["cate", "brand", "type", "time"]]
df_ac = []
df_ac.append(get_from_action_data(fname=ACTION_201602_FILE))
df_ac.append(get_from_action_data(fname=ACTION_201603_FILE))
df_ac.append(get_from_action_data(fname=ACTION_201604_FILE))
df_ac = pd.concat(df_ac, ignore_index=True)
将time字段转换为datetime类型
使用lambda匿名函数将时间time转换为星期(周一为1, 周日为7)
df_ac['time'] = pd.to_datetime(df_ac['time'])
df_ac['time'] = df_ac['time'].apply(lambda x: x.weekday() + 1)
观察有几个类别商品
df_ac.groupby(df_ac['cate']).count()
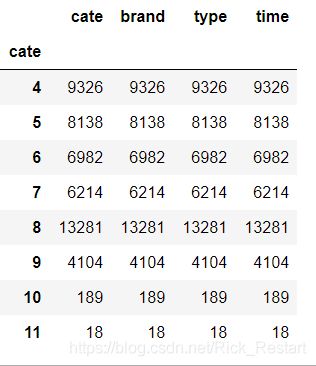
第8大类数量比较多,10跟11的大类数量比较少,其余的都比较平均。
周一到周日每天购买商品类别数量统计
df_product = df_ac['brand'].groupby([df_ac['time'],df_ac['cate']]).count()
df_product=df_product.unstack()
df_product.plot(kind='bar',title='Cate Purchase Table in a Week',figsize=(14,10))

分析:星期二买类别8的最多,星期天最少。
4.每月各类商品销售情况(只关注商品8)
2016年2,3,4月
df_ac2 = get_from_action_data(fname=ACTION_201602_FILE)
# 将time字段转换为datetime类型并使用lambda匿名函数将时间time转换为天
df_ac2['time'] = pd.to_datetime(df_ac2['time']).apply(lambda x: x.day)
df_ac3 = get_from_action_data(fname=ACTION_201603_FILE)
# 将time字段转换为datetime类型并使用lambda匿名函数将时间time转换为天
df_ac3['time'] = pd.to_datetime(df_ac3['time']).apply(lambda x: x.day)
df_ac4 = get_from_action_data(fname=ACTION_201604_FILE)
# 将time字段转换为datetime类型并使用lambda匿名函数将时间time转换为天
df_ac4['time'] = pd.to_datetime(df_ac4['time']).apply(lambda x: x.day)
dc_cate2 = df_ac2[df_ac2['cate']==8]
dc_cate2 = dc_cate2['brand'].groupby(dc_cate2['time']).count()
dc_cate2 = dc_cate2.to_frame().reset_index()
dc_cate2.columns = ['day', 'product_num']
dc_cate3 = df_ac3[df_ac3['cate']==8]
dc_cate3 = dc_cate3['brand'].groupby(dc_cate3['time']).count()
dc_cate3 = dc_cate3.to_frame().reset_index()
dc_cate3.columns = ['day', 'product_num']
dc_cate4 = df_ac4[df_ac4['cate']==8]
dc_cate4 = dc_cate4['brand'].groupby(dc_cate4['time']).count()
dc_cate4 = dc_cate4.to_frame().reset_index()
dc_cate4.columns = ['day', 'product_num']
# 条形宽度
bar_width = 0.2
# 透明度
opacity = 0.4
# 天数
day_range = range(1,len(dc_cate3['day']) + 1, 1)
# 设置图片大小
plt.figure(figsize=(14,10))
plt.bar(dc_cate2['day'], dc_cate2['product_num'], bar_width,
alpha=opacity, color='c', label='February')
plt.bar(dc_cate3['day']+bar_width, dc_cate3['product_num'],
bar_width, alpha=opacity, color='g', label='March')
plt.bar(dc_cate4['day']+bar_width*2, dc_cate4['product_num'],
bar_width, alpha=opacity, color='m', label='April')
plt.xlabel('day')
plt.ylabel('number')
plt.title('Cate-8 Purchase Table')
plt.xticks(dc_cate3['day'] + bar_width * 3 / 2., day_range)
# plt.ylim(0, 80)
plt.tight_layout()
plt.legend(prop={'size':9})

分析:2月份对类别8商品的购买普遍偏低,可能受春节影响。3,4月份普遍偏高,3月15日购买极其多!可以对比3月份的销售记录,发现类别8将近占了3月15日总销售的一半!同时发现,3,4月份类别8销售记录在前半个月特别相似,除了4月8号,9号和3月15号。
5.查看特定用户对特定商品的的轨迹
def spec_ui_action_data(fname, user_id, item_id, chunk_size=100000):
reader = pd.read_csv(fname, header=0, iterator=True)
chunks = []
loop = True
while loop:
try:
chunk = reader.get_chunk(chunk_size)[
["user_id", "sku_id", "type", "time"]]
chunks.append(chunk)
except StopIteration:
loop = False
print("Iteration is stopped")
df_ac = pd.concat(chunks, ignore_index=True)
df_ac = df_ac[(df_ac['user_id'] == user_id) & (df_ac['sku_id'] == item_id)]
return df_ac
def explore_user_item_via_time():
user_id = 266079
item_id = 138778
df_ac = []
df_ac.append(spec_ui_action_data(ACTION_201602_FILE, user_id, item_id))
df_ac.append(spec_ui_action_data(ACTION_201603_FILE, user_id, item_id))
df_ac.append(spec_ui_action_data(ACTION_201604_FILE, user_id, item_id))
df_ac = pd.concat(df_ac, ignore_index=False)
print(df_ac.sort_values(by='time'))
explore_user_item_via_time()

(四)特征工程
import time
from datetime import datetime
from datetime import timedelta
import pandas as pd
import pickle
import os
import math
import numpy as np
test = pd.read_csv('data/JData_Action_201602.csv')
test[['user_id','sku_id','model_id','type','cate','brand']] = test[['user_id','sku_id','model_id','type','cate','brand']].astype('float32')
test.dtypes
test.info()
RangeIndex: 11485424 entries, 0 to 11485423
Data columns (total 7 columns):
user_id float32
sku_id float32
time object
model_id float32
type float32
cate float32
brand float32
dtypes: float32(6), object(1)
memory usage: 350.5+ MB
test = pd.read_csv('data/JData_Action_201602.csv')
#test[['user_id','sku_id','model_id','type','cate','brand']] = test[['user_id','sku_id','model_id','type','cate','brand']].astype('float32')
test.dtypes
test.info()
RangeIndex: 11485424 entries, 0 to 11485423
Data columns (total 7 columns):
user_id int64
sku_id int64
time object
model_id float64
type int64
cate int64
brand int64
dtypes: float64(1), int64(5), object(1)
memory usage: 613.4+ MB
数据类型转换,减小文件大小
action_1_path = r'data/JData_Action_201602.csv'
action_2_path = r'data/JData_Action_201603.csv'
action_3_path = r'data/JData_Action_201604.csv'
comment_path = r'data/JData_Comment.csv'
product_path = r'data/JData_Product.csv'
user_path = r'data/JData_User.csv'
comment_date = [
"2016-02-01", "2016-02-08", "2016-02-15", "2016-02-22", "2016-02-29",
"2016-03-07", "2016-03-14", "2016-03-21", "2016-03-28", "2016-04-04",
"2016-04-11", "2016-04-15"
]
def get_actions_1():
action = pd.read_csv(action_1_path)
action[['user_id','sku_id','model_id','type','cate','brand']] = action[['user_id','sku_id','model_id','type','cate','brand']].astype('float32')
return action
def get_actions_2():
action = pd.read_csv(action_1_path)
action[['user_id','sku_id','model_id','type','cate','brand']] = action[['user_id','sku_id','model_id','type','cate','brand']].astype('float32')
return action
def get_actions_3():
action = pd.read_csv(action_1_path)
action[['user_id','sku_id','model_id','type','cate','brand']] = action[['user_id','sku_id','model_id','type','cate','brand']].astype('float32')
return action
# 读取并拼接所有行为记录文件
def get_all_action():
action_1 = get_actions_1()
action_2 = get_actions_2()
action_3 = get_actions_3()
actions = pd.concat([action_1, action_2, action_3]) # type: pd.DataFrame
return actions
# 获取某个时间段的行为记录
def get_actions(start_date, end_date, all_actions):
"""
:param start_date:
:param end_date:
:return: actions: pd.Dataframe
"""
actions = all_actions[(all_actions.time >= start_date) & (all_actions.time < end_date)].copy()
return actions
1.用户特征
用户基本特征
获取基本的用户特征,基于用户本身属性多为类别特征的特点,对age,sex,usr_lv_cd进行独热编码操作,对于用户注册时间暂时不处理
针对年龄的中文字符问题处理,首先是读入的时候编码,填充空值,然后将其数值化,最后独热编码,此外对于sex也进行了数值类型转换
from sklearn import preprocessing
def get_basic_user_feat():
user = pd.read_csv(user_path, encoding='gbk')
user.dropna(axis=0, how='any',inplace=True)
user['sex'] = user['sex'].astype(int)
user['age'] = user['age'].astype(int)
le = preprocessing.LabelEncoder()
age_df = le.fit_transform(user['age'])
age_df = pd.get_dummies(age_df, prefix='age')
sex_df = pd.get_dummies(user['sex'], prefix='sex')
user_lv_df = pd.get_dummies(user['user_lv_cd'], prefix='user_lv_cd')
user = pd.concat([user['user_id'], age_df, sex_df, user_lv_df], axis=1)
return user
2.商品特征
商品基本特征
根据商品文件获取基本的特征,针对属性a1,a2,a3进行独热编码,商品类别和品牌直接作为特征
def get_basic_product_feat():
product = pd.read_csv(product_path)
attr1_df = pd.get_dummies(product["a1"], prefix="a1")
attr2_df = pd.get_dummies(product["a2"], prefix="a2")
attr3_df = pd.get_dummies(product["a3"], prefix="a3")
product = pd.concat([product[['sku_id', 'cate', 'brand']], attr1_df, attr2_df, attr3_df], axis=1)
return product
3.评论特征
分时间段,对评论数进行独热编码
def get_comments_product_feat(end_date):
comments = pd.read_csv(comment_path)
comment_date_end = end_date
comment_date_begin = comment_date[0]
for date in reversed(comment_date):
if date < comment_date_end:
comment_date_begin = date
break
comments = comments[comments.dt==comment_date_begin]
df = pd.get_dummies(comments['comment_num'], prefix='comment_num')
# 为了防止某个时间段不具备评论数为0的情况(测试集出现过这种情况)
for i in range(0, 5):
if 'comment_num_' + str(i) not in df.columns:
df['comment_num_' + str(i)] = 0
df = df[['comment_num_0', 'comment_num_1', 'comment_num_2', 'comment_num_3', 'comment_num_4']]
comments = pd.concat([comments, df], axis=1) # type: pd.DataFrame
#del comments['dt']
#del comments['comment_num']
comments = comments[['sku_id', 'has_bad_comment', 'bad_comment_rate','comment_num_0', 'comment_num_1',
'comment_num_2', 'comment_num_3', 'comment_num_4']]
return comments
train_start_date = '2016-02-01'
train_end_date = datetime.strptime(train_start_date, '%Y-%m-%d') + timedelta(days=3)
train_end_date = train_end_date.strftime('%Y-%m-%d')
day = 3
start_date = datetime.strptime(train_end_date, '%Y-%m-%d') - timedelta(days=day)
start_date = start_date.strftime('%Y-%m-%d')
4.行为特征
分时间段
对行为类别进行独热编码
分别按照用户-类别行为分组和用户-类别-商品行为分组统计,然后计算
用户对同类别下其他商品的行为计数
针对用户对同类别下目标商品的行为计数与该时间段的行为均值作差
def get_action_feat(start_date, end_date, all_actions, i):
actions = get_actions(start_date, end_date, all_actions)
actions = actions[['user_id', 'sku_id', 'cate','type']]
# 不同时间累积的行为计数(3,5,7,10,15,21,30)
df = pd.get_dummies(actions['type'], prefix='action_before_%s' %i)
before_date = 'action_before_%s' %i
actions = pd.concat([actions, df], axis=1) # type: pd.DataFrame
# 分组统计,用户-类别-商品,不同用户对不同类别下商品的行为计数
actions = actions.groupby(['user_id', 'sku_id','cate'], as_index=False).sum()
# 分组统计,用户-类别,不同用户对不同商品类别的行为计数
user_cate = actions.groupby(['user_id','cate'], as_index=False).sum()
del user_cate['sku_id']
del user_cate['type']
actions = pd.merge(actions, user_cate, how='left', on=['user_id','cate'])
#本类别下其他商品点击量
# 前述两种分组含有相同名称的不同行为的计数,系统会自动针对名称调整添加后缀,x,y,所以这里作差统计的是同一类别下其他商品的行为计数
actions[before_date+'_1.0_y'] = actions[before_date+'_1.0_y'] - actions[before_date+'_1.0_x']
actions[before_date+'_2.0_y'] = actions[before_date+'_2.0_y'] - actions[before_date+'_2.0_x']
actions[before_date+'_3.0_y'] = actions[before_date+'_3.0_y'] - actions[before_date+'_3.0_x']
actions[before_date+'_4.0_y'] = actions[before_date+'_4.0_y'] - actions[before_date+'_4.0_x']
actions[before_date+'_5.0_y'] = actions[before_date+'_5.0_y'] - actions[before_date+'_5.0_x']
actions[before_date+'_6.0_y'] = actions[before_date+'_6.0_y'] - actions[before_date+'_6.0_x']
# 统计用户对不同类别下商品计数与该类别下商品行为计数均值(对时间)的差值
actions[before_date+'minus_mean_1'] = actions[before_date+'_1.0_x'] - (actions[before_date+'_1.0_x']/i)
actions[before_date+'minus_mean_2'] = actions[before_date+'_2.0_x'] - (actions[before_date+'_2.0_x']/i)
actions[before_date+'minus_mean_3'] = actions[before_date+'_3.0_x'] - (actions[before_date+'_3.0_x']/i)
actions[before_date+'minus_mean_4'] = actions[before_date+'_4.0_x'] - (actions[before_date+'_4.0_x']/i)
actions[before_date+'minus_mean_5'] = actions[before_date+'_5.0_x'] - (actions[before_date+'_5.0_x']/i)
actions[before_date+'minus_mean_6'] = actions[before_date+'_6.0_x'] - (actions[before_date+'_6.0_x']/i)
del actions['type']
# 保留cate特征
# del actions['cate']
return actions