文献阅读笔记-MASS: Masked Sequence to Sequence Pre-training for Language Generation
背景
题目:MASS: Masked Sequence to Sequence Pre-training for Language Generation
机构:微软亚洲研究院
作者:Kaitao Song、Xu Tan
发布地方:ICML 2019
面向任务:自然语言理解任务(NLU)的学习表示
论文地址:https://arxiv.org/pdf/1905.02450.pdf
最新成果:WMT19 机器翻译比赛中,MASS在中-英、英-立陶宛两个语言中取得了第一名的成绩
论文代码:https://github.com/microsoft/MASS
摘要
受到BERT的预训练和fine tuning的启发,本文提出MAsked Sequence to Sequence pre-training (MASS)以用encoder-decoder方式进行文本生成。MASS采用encoder-decoder框架以重建一个句子片段:其encoders输入的句子被随机掩盖掉连续数个tokens,其decoder尝试预测该掩盖掉的片段。【这个其实与BERT很像,完形填空的方式,只是这里遮蔽掉的是连续的数个tokens,而BERT只遮蔽一个token】通过这种方式MASS能够联合训练encoder和decoder以提升表征提取的能力和语言建模的能力。再在一系列的零样本或者少样本的生成任务(包括神经机器翻译、文本摘要和对话回答生成这3个任务,具体来说包含了8个数据集)中进行fine tuning,最终MASS获得的结果远超于各个baselines。这些数据集的baselines要么是没有预训练,要么是采用其他的预训练方法。特别地,在BLUE得分中以37.5的accuracy刷新了记录。在无监督的英-法翻译中,甚至超过了早期基于注意力的监督模型(Bahdanau et al., 2015b)。
介绍
BERT 在自然语言理解(比如情感分类、自然语言推理、命名实体识别、SQuAD 阅读理解等)任务中取得了很好的结果,受到了越来越多的关注。然而,在自然语言处理领域,除了自然语言理解任务,还有很多序列到序列的自然语言生成任务,比如机器翻译、文本摘要生成、对话生成等。自然语言生成任务所需要的数据量是巨大的,但是一般情况下的上述自然语言生成任务很多是零样本或是少样本训练集。直接在这些自然语言生成任务上使用BERT是不合适的,这是由于BERT的设计初衷是用于自然语言理解。如此设计,使其一般只有encoder或者decoder。因此,如何为自然语言生成任务(这些任务常常使用encoder-decoder的序列到序列框架)设计预训练模型是极具潜力且至关重要的。
不像BERT或者其他预训练的语言模型,仅仅使用encoder或者decoder,MASS的预训练阶段是联合了encoder和decoder。第一步:在encoder端遮蔽掉连续的数个tokens,预测这些被遮蔽掉的tokens。MASS能够强制encoder理解这些未被遮蔽的tokens,以在decoder端预测这些被遮蔽的tokens。第二步:在decoder端遮蔽掉在source端对应的未被遮蔽的部分,如此在进行下一个token预测的时候,MASS能够强制decoder依赖于source的特征表示,而非target端前之前预测的tokens。这样能够更好地促进encoder和decoder之间的联合训练。
MASS仅仅需要预训练一个模型,然后再下游的多种任务中进行微调即可。本文使用transformer作为序列到序列的基本model,在WMT的单一语言语料上进行预训练,之后在下游的3个语言生成任务: 机器神经翻译(NMT)、文本摘要和对话回答生成 中进行微调。考虑到下游任务中有跨语言任务NMT,MASS在预训练过程中使用多种语言。本文尝试在3个任务中使用low-resource setting(即使用较少的数据量),同时也在NMT任务上尝试零训练样本(zero-resource setting)的无监督学习。 对于NMT任务是采用WMT14中的英-法数据集、WMT16中的英-德和WMT16的英语-罗马数据集。对于无监督的NMT,直接将预训练后的模型作用于单语种数据集,并设置back-translation loss(而不用采用additional denoising auto-encoder loss)。至于low-resource的NMT,直接在给定的少量训练集上对预训练的模型进行微调。对于另外2个任务,我们采用以下的方式:(1)文本摘要任务上采用Gigaword 语料(2)在会话式答案生成任务上采用Cornell Movie Dialog语料。MASS能够在所有这些任务上(包括零样本和少样本)获得性能上的提升,从而证明了本文模型在一系列的生成任务上的有效性和通用性。
本文的贡献如下:
(1)提出MASS, 一个面向语言生成任务的屏蔽序列到序列预训练模型
(2)将MASS应用到一系列的语言生成任务上,包括NMT、文本摘要生成和对话回答生成,并取得显著了性能提升,从而证明了本文方法的有效性。特别是,在2个无监督NMT数据集:English-French 和English-German上取得了SOTA得分(在BLEU得分上)。该BLEU score分别超出此前最优得分4个百分点(English-French)和1个百分点(French-English)。此外,该模型还击败了早期带注意力机制的有监督NMT模型(Bahdanau et al., 2015b)。本文的代码也将会在GitHub上公布。
相关工作
NLP中的预训练
自然语言生成任务中,目前主流的方法是编码器 - 注意力 -解码器框架, 如下图所示。

编码器(Encoder)将源序列文本 X 编码成隐藏向量序列,然后解码器(Decoder)通过注意力机制(Attention)抽取编码的隐藏向量序列信息,自回归地生成目标序列文本 Y。
BERT通常只训练一个编码器用于自然语言理解,而 GPT 的语言模型通常是训练一个解码器。如果要将 BERT 或者 GPT 用于序列到序列的自然语言生成任务,通常只有分开预训练编码器和解码器,因此编码器 - 注意力 - 解码器结构没有被联合训练, 记忆力机制也不会被预训练,而解码器对编码器的注意力机制在这类任务中非常重要,因此BERT和 GPT 在这类任务中只能达到次优效果。
MASS
专门针对序列到序列的自然语言生成任务,微软亚洲研究院提出了新的预训练方法:屏蔽序列到序列预训练(MASS: Masked Sequence to Sequence Pre-training)。MASS 对句子随机屏蔽一个长度为 k 的连续片段,然后通过编码器 - 注意力 - 解码器模型预测生成该片段。
屏蔽序列到序列预训练 MASS 模型框架:
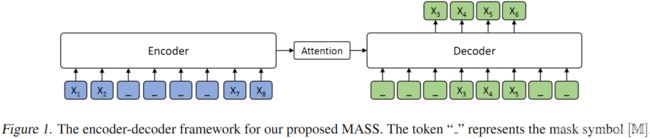
如上图所示,编码器端的第 3-6 个词被屏蔽掉,然后解码器端只预测这几个连续的词,而屏蔽掉其它词,图中 “_” 代表被屏蔽的词。
MASS 预训练有以下几大优势:
(1)解码器端其它词(在编码器端未被屏蔽掉的词)都被屏蔽掉,以鼓励解码器从编码器端提取信息来帮助连续片段的预测,这样能促进编码器 - 注意力 - 解码器结构的联合训练;
(2)为了给解码器提供更有用的信息,编码器被强制去抽取未被屏蔽掉词的语义,以提升编码器理解源序列文本的能力;
(3)让解码器预测连续的序列片段,以提升解码器的语言建模能力。
统一的预训练框架
MASS 有一个重要的超参数 k(屏蔽的连续片段长度),通过调整 k 的大小,MASS 能包含 BERT 中的屏蔽语言模型训练方法以及 GPT 中标准的语言模型预训练方法,使 MASS 成为一个通用的预训练框架。
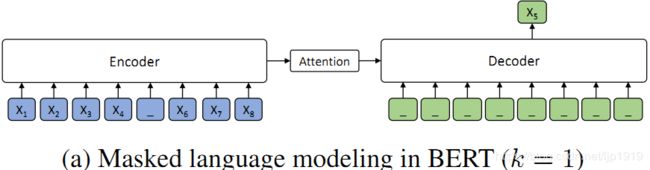
当 k=1 时,根据 MASS 的设定,编码器端屏蔽一个单词,解码器端预测一个单词,如下图所示。解码器端没有任何输入信息,这时 MASS 和 BERT 中的屏蔽语言模型的预训练方法等价。
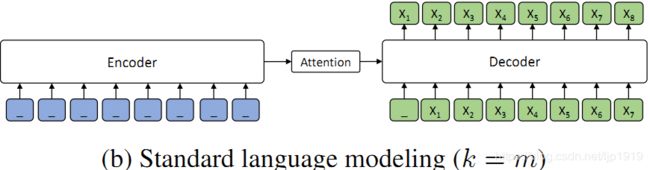
当 k=m(m 为序列长度)时,根据 MASS 的设定,编码器屏蔽所有的单词,解码器预测所有单词,如下图所示, 由于编码器端所有词都被屏蔽掉,解码器的注意力机制相当于没有获取到信息,在这种情况下 MASS 等价于 GPT 中的标准语言模型。
MASS 在不同 K 下的概率形式如下表所示,其中 m 为序列长度,u 和 v 为屏蔽序列的开始和结束位置,x^u:v 表示从位置 u 到 v 的序列片段,x^\u:v 表示该序列从位置 u 到 v 被屏蔽掉。可以看到,当K=1 或者 m 时,MASS 的概率形式分别和 BERT 中的屏蔽语言模型以及 GPT 中的标准语言模型一致。

讨论
与BERT和GPT的不同:
标准的语言模型中最典型的代表是ELMo和GPT,自然语言理解中最具代表性的是BERT。BERT使用一个encoder去提取单个句子或者句子对的表征。标准的语言模型和和BERT都仅仅分别预训练encoder或者decoder。虽然它们可以在自然语言理解任务上取得令人瞩目的成果,但是在自然语言生成任务上显得不合时宜。这是由于自然语言生成一般利用encoder-decoder框架,其生成的语言序列是条件概率。
MASS在自然语言生成任务上联合了预训练的encoder和decoder。首先,通过seq2seq框架仅仅预测被屏蔽掉的tokens。MASS强制要求encoder理解透彻未被屏蔽的tokens含义,同时激励decoder从encoder这里抽取有意义的信息。其次,通过预测连续的tokens而非离散的tokens,decoder端能够构建更好的语言建模能力。第三,在decoder端对于在encoder端未被屏蔽的input tokens进行屏蔽(即,在decoder的inputs上放弃先验信息)。例如,当想要预测 x 3 , x 4 , x 5 , x 6 x_3,x_4,x_5,x_6 x3,x4,x5,x6,只有 x 3 , x 4 , x 5 x_3,x_4,x_5 x3,x4,x5作为decoder端的输入,其他的tokens被遮蔽掉。这促使decoder端从encoder端抽取更多有用信息,而不是使用此前tokens中的丰富信息。
实验及其结果
MASS的预训练
模型配置:
以Transformer为基本的模型结构,Transformer是由4层encoder+4层decoder+512 embedding/hidden size + 2048 feed-forward filter size。文本摘要和对话生成是单语种任务,NMT涉及多语言,所以除了英语之外,还需要预训练一个多语种模型。本文考虑了English, German, French 和 Romanian,其中英语在所有的下游任务中都会被用到,其他语种只会在NMT任务中用到。此外,为了区分不同的语种,在输入的句子中增加了一个language embedding。
预训练的细节:
对于被屏蔽掉的token用以特定字符取代,其他的处理与BERT的一样(80%的随机替换,10%的随机其他token,10%的未屏蔽)。此外本文还研究了不同的屏蔽长度k对accuracy的影响,这点后面补充结果。为了降低内存占用和计算时长,本文设计去掉decoder端的padding,但是保持unmasked tokens的positional embedding(即,如果前2个token被屏蔽,第3个token的positional embedding仍然是2,而不是0)。这种方式可以在维持accuracy不变的前提下,在decoder端降低大约50%的计算量。本文采用的优化器是Adam,其学习率是 1 0 − 4 10^{-4} 10−4,训练的机器设备是4张 NVIDIA P100 GPU,每个mini-batch有32*4 个句子。
本文通过NMT、文本摘要和对话生成任务来验证MASS的有效性。同时探索少样本下MASS的性能表现。对于NMT,主要是探索在零样本下MASS的无监督表现结果。具体的实验结果随后详细介绍。
4.2 在NMT上微调
主要实验MASS在无监督NMT上的表现和少样本NMT上的表现。
实验设置:
对于无监督的NMT是没有双语数据来对预训练模型微调的,因此只能使用在预训练阶段中的单语种数据。本文这里使用回译方法(而不是使用denoising auto-encoder,即降噪自编码器)以生成伪双语种数据以用于训练。在微调阶段,不同的翻译方向共享模型,如English-German和German-English。微调过程使用的是Adam优化器,其初始的学习率是 1 0 − 4 10^{-4} 10−4。
无监督NMT的实验结果:
在无监督NMT任务上与此前的模型对比,结果如下:
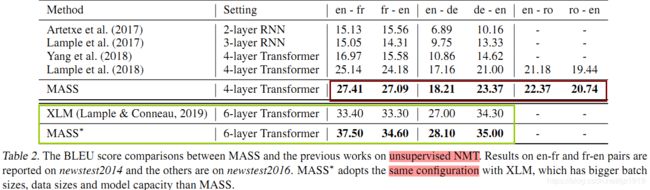
在无监督翻译任务上,我们和当前最强的 Facebook XLM 作比较(XLM 用 BERT中的屏蔽预训练模型, 以及标准语言模型来分别预训练编码器和解码器)。可以看到,MASS 的预训练方法在 WMT14 英语 - 法语、WMT16 英语 - 德语一共 4 个翻译方向上的表现都优于 XLM。MASS 在英语 - 法语无监督翻译上的效果已经远超早期有监督的编码器 - 注意力 - 解码器模型,同时极大缩小了和当前最好的有监督模型之间的差距。
MASS和其他预训练模型的对比:
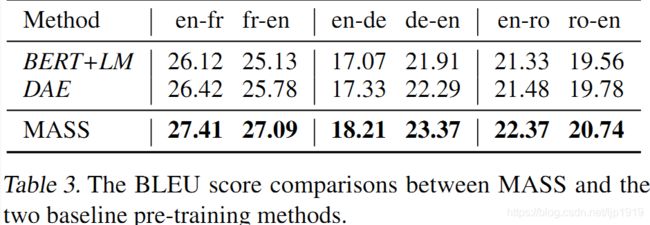
这里选用的预训练模型有BERT+LM和去噪自编码器(DAE)。在BERT中采用遮蔽语言模型以预训练encoder,再采用标准的语言模型预训练decoder。在预训练decoder时候,我们并不采用屏蔽的语言模型。这是由于多数的自然语言生成任务都是自回归的,其双向的语言模型适用。第2个baseline是DAE,DAE是预训练encoder和decoder。这2个Baselines预训练后,在无监督的翻译对上进行微调,其策略与之前介绍的MASS相同。
从table 3可以看出,DAE的BLEU得分比BERT+LM更高,而MASS在所有的数据上都一枝独秀。DAE采用了一些降噪方法,如随机遮蔽tokens或者互换相邻的tokens,其decoder能够很容易通过encoder-decoder attention学习到未遮蔽的tokens含义。另一方面,DAE的decoder端能够充分利用输入的所有句子,这使得下一个token的预测(类似语言模型)变得容易许多。这也就无需强制decoder从encoder端学习到更多有用的表征。
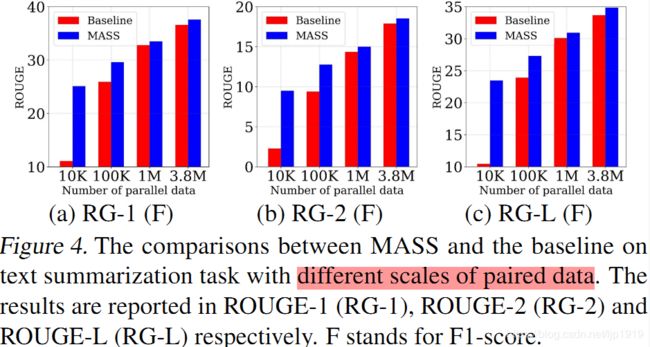
低资源机器翻译:
低资源机器翻译指的是监督数据有限情况下的机器翻译。我们在 WMT14 英语 - 法语、WMT16 英语 - 德语上的不同低资源场景上(分别只有 10K、100K、1M 的监督数据)验证我们方法的有效性,结果如下所示。

从上图可以看出,在少训练样本下,MASS多数是以碾压式的方式取胜的,数据量越少,MASS多出的得分越高。
4.3 在文本摘要上微调
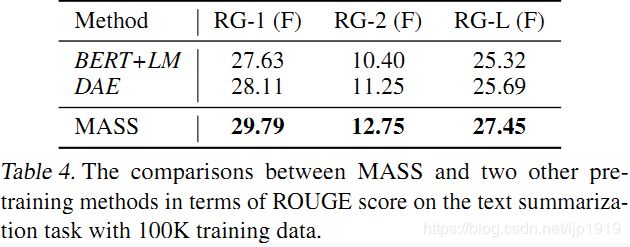
在文本摘要生成(Gigaword Corpus)任务上,我们将 MASS 同 BERT+LM(编码器用 BERT 预训练,解码器用标准语言模型 LM 预训练)以及 DAE(去噪自编码器)进行了比较。从下表可以看到,MASS 的效果明显优于 BERT+LM 以及 DAE。
MASS在不同数据量上各个指标的结果:
MASS和其他预训练模型的对比:
4.4 在对话生成上微调
在对话生成(Cornell Movie Dialog Corpus)任务上,我们将 MASS 同 BERT+LM 进行了比较,结果如下表所示。MASS 的 PPL 低于 BERT+LM。

4.5 MASS的分析
我们通过实验分析了屏蔽 MASS 模型中不同的片段长度(k)进行预训练的效果,如下图所示。

当 k 取大约句子长度一半时(50% m),下游任务能达到最优性能。屏蔽句子中一半的词可以很好地平衡编码器和解码器的预训练,过度偏向编码器(k=1,即 BERT)或者过度偏向解码器(k=m,即 LM/GPT)都不能在该任务中取得最优的效果,由此可以看出 MASS 在序列到序列的自然语言生成任务中的优势。