目标检测与位姿估计(二):YOLOv1超参、评价指标与损失函数的建立
超参
致谢:https://www.cnblogs.com/wujianming-110117/p/12934969.html
1 上一章提到的VOC数据集重新训练的方法中涉及到的class-number,以及fiters=(class+5)x3
2 避免过拟合最重要的参数是:batch_size,YOLOv4中还有一个subdivisions参数,两者是根据GPU的内存决定的

3 图片的大小要是32的倍数
4 max_batches是最大的训练次数,一般为max_batches = class * 2000
5 steps=0.8 * max_batches,0.9 * max_batches
6 如果使用[Gaussian_yolo]层,修改filters为(classes+9)x3,在3个[Gaussian_yolo]层的前一个[convolutional]层为:
评价指标的建立
参考致谢:https://mp.weixin.qq.com/s?__biz=MzIzNDM2OTMzOQ==&mid=2247487059&idx=1&sn=9e2c5ee7923ddd36c889507c70ddb804&chksm=e8f63607df81bf11c4597a116b4812af35570ada98220a283af295c829bb60473089a41d80eb&mpshare=1&scene=23&srcid=0722LIxqziSJe01Uv5ddFGvI&sharer_sharetime=1595423944083&sharer_shareid=7ac210d5394f53b68ccf96c0ef8a72ed#rd
IoU:交并比(intersection over union)A交B / A并B
T,F,P,N:预测值为正例,记为P(Positive)
预测值为反例,记为N(Negative)
预测值与真实值相同,记为T(True)
预测值与真实值相反,记为F(False)
说实话,这个我始终不太明白,不过这样好记一点:TF正不正确,PN预测的是正还是负样本
TP -- 预测值和真实值一样,预测值为正样本(真实值为正样本)
TN -- 预测值和真实值一样,预测值为负样本(真实值为负样本)
FP -- 预测值和真实值不一样,预测值为正样本(真实值为负样本)
FN -- 预测值和真实值不一样,预测值为负样本(真实值为正样本)
GIoU,DIoU,CIoU:https://mp.weixin.qq.com/s/pHIKmVMuakaxyR05GHBmFA
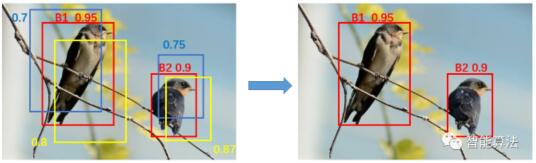
非极大值抑制:NMS(Non-Maximum Suppression)。就是在预测的结果框和相应的置信度中找到置信度比较高的bounding box。对于有重叠在一起的预测框,如果和当前最高分的候选框重叠面积IoU大于一定的阈值的时候,就将其删除,而只保留得分最高的那个。计算步骤是1NMS计算出每一个bounding box的面积,然后根据置信度进行排序,把置信度最大的bounding box作为队列中首个要比较的对象;2 计算其余bounding box与当前最大score的IoU,去除IoU大于设定的阈值的bounding box(认为这些box与得分最大的box表达的物体是一个),保留小的IoU预测框(这些可能属于其他物体);3 然后重复上面的过程,直至候选bounding box为空。多个目标检测目标时:先选取置信度最大的候选框B1,然后根据IoU阈值来去除B1候选框周围的框。然后再选取置信度第二大的候选框B2,再根据IoU阈值去掉B2候选框周围的框。
准确率:(accuracy)是最常用的一种。accuracy = (TP+TN)/(TP+TN+FP+FN) 分对的样本占总数的比例。公式中的TP+TN即为所有的正确预测为正样本的数据与正确预测为负样本的数据的总和,TP+TN+FP+FN即为总样本的个数。
精度:(precision)描述的是“找的对”的比例,precision = TP/( TP+FP)。找到的所有正样本中,有多少找对了。
召回率/TPR:(recall&true positive rate又叫灵敏度):描述的是“找的全”的比例,recall/TPR = TP/(TP+FN),其中TP+FN即为所有真正为正样本的数据。所有正样本中有多少被找全了。
FPR:与TPR相反指实际负例中,错误的判断为正例的比例,这个值往往越小越好,FPR = FP/(FP+TN)。
F1分数:F1 = 2TP/(2TP+FP+FN),相当于召回率和精度的调和平均数,F1代表认为召回率和精度同样重要,加权调和平均时则有所侧重,F2分数认为召回率的重要程度是精度的2倍,而F0.5分数认为召回率的重要程度是精度的一半。更一般地,我们可以定义Fβ(precision和recall权重可调的F1 score):Fβ = ((1+β*β)*precision*recall) / (β*β*precision + recall)
PR曲线:横坐标为召回率,纵坐标为精度的曲线。
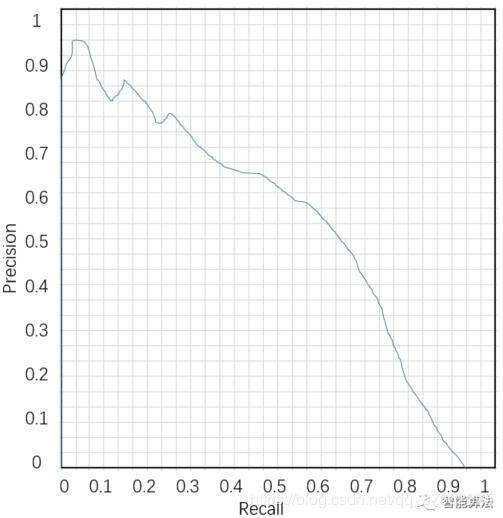
AP:平均准确率,是对不同召回率点上的准确率进行平均,在PR曲线上表现为PR曲线下的面积。显然AP与PR曲线共存,PR曲线最大的问题是对正负样本分布比较敏感,比如当负样本增加10倍后,在recall不变的情况下,必然召回了更多的负样本,所以精度就会大幅下降。对于不同正负样本比例的测试集,PR曲线的变化就会非常大。
ROC曲线:Receiver Operating Characteristic Curve,曲线横坐标为FPR,纵坐标为TPR。
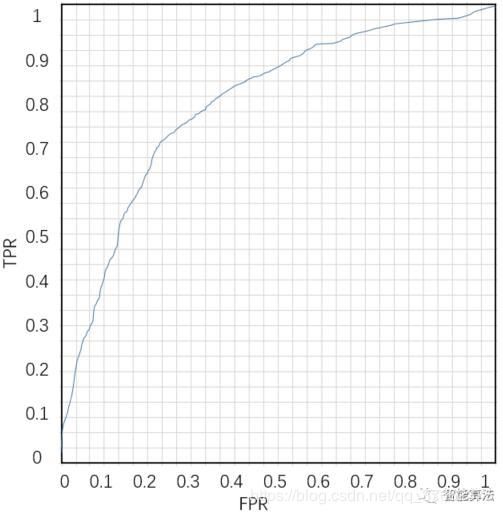
AUC:Area under curve,即ROC曲线下面积,计算方式为ROC曲线的微积分值。其物理意义可以表示为:随机给定一正一负两个样本,将正样本排在负样本之前的概率,因此AUC越大,说明正样本越有可能被排在负样本之前,即正样本分类结果越好。ROC曲线有个很好的特性,当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变。ROC曲线可以反映二分类器的总体分类性能,但是无法直接从图中识别出分类最好的阈值,事实上最好的阈值也是视具体的场景所定。ROC曲线一定在y=x之上,否则就是一个不好的分类器。
mAP:mean average precision,意思是平均精度均值。AP就是PR曲线下面的面积,是指不同召回率下的精度的平均值。然而,在目标检测中,一个模型通常会检测很多种物体,那么每一类都能绘制一个PR曲线,进而计算出一个AP值。那么多个类别的AP值的平均就是mAP.
mAP衡量的是学出的模型在所有类别上的好坏,是目标检测中一个最为重要的指标,一般看论文或者评估一个目标检测模型,都会看这个值,这个值是在0-1之间,越大越好。
一般来说mAP针对整个数据集而言的,AP针对数据集中某一个类别而言的,而percision和recall针对单张图片某一类别的。
损失函数的建立
常规(正常的)训练趋势应该是

可能作为调参的依据
1 通常情况下,为每个类别迭代2000次是足够的,且总的迭代次数不能低于4000次。
2 在训练过程中,你会看到一系列训练误差,当0.XXXXXXX avg这个参数不再下降时,就该停止训练了
Region Avg IOU: 0.798363, Class: 0.893232, Obj: 0.700808, No Obj: 0.004567, Avg Recall: 1.000000, count: 8 Region Avg IOU: 0.800677, Class: 0.892181, Obj: 0.701590, No Obj: 0.004574, Avg Recall: 1.000000, count: 8 9002: 0.211667, 0.60730 avg, 0.001000 rate, 3.868000 seconds, 576128 images Loaded: 0.000000 seconds
- 9002 - 迭代数量(batch数量)
- 0.60730 avg - 平均损失(误差),越低越好
3 利用-map参数查看mAP评价指标,或者在训练时自动保存的权重上执行测试命令
- ./darknet detector map data/obj.data cfg/yolo-obj.cfg backup\yolo-obj_7000.weights
- ./darknet detector map data/obj.data cfg/yolo-obj.cfg backup\yolo-obj_8000.weights
- ./darknet detector map data/obj.data cfg/yolo-obj.cfg backup\yolo-obj_9000.weights
下面介绍一下YOLOv1的损失函数的构成以及基于此在YOLOv4上的改进
YOLOv1算法最后输出的检测结果为7x7x30的形式,其中30个值分别包括2个候选框的位置,有无包含物体的置信度,以及网格中包含20个物体类别的概率三部分。也就是说YOLOv1的损失包括3部分误差:位置误差,置信度(confidence)误差,分类误差。
我们知道,如果8维的localization error,两个置信度error和20维的classification error同等重要显然是不合理的;还有如果一个网格中没有object(一幅图中这种网格很多),那么就会将这些网格中的box的confidence push到0,相比于较少的有object的网格,这种做法是overpowering(强烈震荡)的,这会导致网络不稳定甚至发散。损失函数的设计目标就是让坐标(x,y,w,h),confidence,classification这个三个方面达到很好的平衡。YOLO-V1算法中简单的全部采用了sum-squared error loss来做这件事,也就是使用权重系数来进行平衡,对于不同的损失用不同的权重,我们来逐个看:

位置损失
从上图可以看出,坐标损失也分为两部分,坐标中心误差和位置宽高的误差,其中![]() 表示第
表示第i个网格中的第j个预测框是否负责obj这个物体的预测,只有当某个box predictor对某个ground truth box负责的时候,才会对box的coordinate error进行惩罚,而对哪个ground truth box负责就看其预测值和ground truth box的IoU是不是在那个网格的所有box中最大。(就是7x7方格的选择问题,非极大值抑制)
但这里有个问题:对于中心点的损失直接用了均方误差,但是对于宽高为什么用了平方根呢?这里是这样的,我们先来看下图:

上图中,蓝色为bounding box,红色框为真实标注,如果W和h没有平方根的话,那么bounding box跟两个真实标注的位置loss是相同的。但是从面积看来B框是A框的25倍,C框是B框的81/25倍。B框跟A框的大小偏差更大,所以不应该有相同的loss。
如果W和h加上平方根,那么B对A的位置loss约为3.06,B对C的位置loss约为1.17,B对A的位置loss的值更大,这更加符合我们的实际判断。所以,算法对位置损失中的宽高损失加上了平方根。
而公式中的![]() 为位置损失的权重系数,在
为位置损失的权重系数,在pascal VOC训练中取5。
置信度损失
这里分成了两部分,一部分是包含物体时置信度的损失,一个是不包含物体时置信度的值。
置信度的定义:\[confidence = Pr{\rm{(}}Object{\rm{)}}*IOU_{pred}^{truth}\]
其中前一项表示有无人工标记的物体落入网格内,如果有,则为1,否则为0.第二项代表bounding box和真实标记的box之间的IoU。值越大则box越接近真实位置。(IoU揭示的是重合部分的大小)confidence是针对bounding box的,由于每个网格有两个bounding box,所以每个网格会有两个confidence与之相对应。
从损失函数上看,当网格i中的第j个预测框包含物体的时候,用上面的置信度损失,而不包含物体的时候,用下面的损失函数。对没有object的box的confidence loss,赋予小的loss weight(而不是0,否则会overpowering),![]() 在
在pascal VOC训练中取0.5。有object的box的confidence loss和类别的loss的loss weight正常取1。
类别损失
类别损失这里也用了均方误差,实际上,感觉这里用交叉熵更好一些。其中![]() 表示有无
表示有无object的中心点落到网格i中,如果网格中包含有物体object的中心的话,那么就负责预测该object的概率。
总结
总体来说,对于不同的任务重要程度不同,所以也应该给与不同的loss weight:
-
每个网格两个预测框坐标比较重要,给这些损失赋予更大的
loss weight,在pascal VOC中取值为5. -
对没有
object的box的confidence loss,赋予较小的loss weight,在pascal VOC训练中取0.5.对有object的box的confidence loss和类别的loss weight正常取值为1. -
class error归一化为1