MyDLNote-Enhancement: CVPR2020 基于不变表示学习的非监督图像修复算法
MyDLNote-Enhancement: CVPR2020 Learning Invariant Representation for Unsupervised Image Restoration

[paper] : https://arxiv.org/pdf/2003.12769.pdf
[github] : https://github.com/Wenchao-Du/LIR-for-Unsupervised-IR
参考文章:Diverse Image-to-Image Translation via Disentangled Representations ECCV 2018
Abstract
Recently, cross domain transfer has been applied for unsupervised image restoration tasks. However, directly applying existing frameworks would lead to domain-shift problems in translated images due to lack of effective supervision.
motivition:近年来,跨域图像翻译(cross domain transfer)应用于无监督图像恢复任务。但是,由于缺乏有效的监督,直接应用现有框架会导致翻译后的图像出现域迁移(domain-shift)问题。
Instead, we propose an unsupervised learning method that explicitly learns invariant presentation from noisy data and reconstructs clear observations. To do so, we introduce discrete disentangling representation and adversarial domain adaption into general domain transfer framework, aided by extra self-supervised modules including background and semantic consistency constraints, learning robust representation under dual domain constraints, such as feature and image domains.
本文方法:提出了一种无监督学习方法,从噪声数据学习不变量表示和重建清晰的图像。
具体细节:在 domain transfer framework 中引入离散 disentangling representation 和 adversarial domain adaption 引入一般的域转移框架中,并借助额外的自监督模块,包括背景和语义一致性约束,学习双重域(如特征域和图像域)约束下的鲁棒表示。
Experiments on synthetic and real noise removal tasks show the proposed method achieves comparable performance with other state-of-the-art supervised and unsupervised methods, while having faster and stable convergence than other domain adaption methods.
实验结果:
1. 人工合成数据集、真实数据集效果优于 监督和无监督 SOTA 算法;
2. 与其它 domain adaption methods 相比,运行速度快
3. 与其它 domain adaption methods 相比,收敛速度稳定
Introduction
引言就像漏斗。本文第一段,先用几句介绍大背景,告诉读者是做哪个领域的工作。紧接着,缩小研究方向到 DNNs 和 GAN,这两种模型下,传统的方法是什么,问题是什么。
Image restoration > DNNs/GAN 监督学习方法 > 监督学习的问题
Image restoration (IR) attempts to reconstruct clean signals from their corrupted observations, which is known to be an ill-posed inverse problem. By accommodating different types of corruption distributions, the same mathematical model applies to problems such as image denoising, super-resolution and deblurring. Recently, deep neural networks (DNNs) and generative adversarial networks (GANs) [10] have shown their superior performance in various lowlevel vision tasks. Nonetheless, most of these methods need paired training data for specific tasks, which limits their generality, scalability and practicality in real-world multimedia applications. In addition, strong supervision may suffer from the overfitting training and lower generalization to real image corruption types.
研究大方向背景和大方向问题:
背景:图像恢复 (IR) 试图从损坏的观测数据中重建干净的信号,这是一个病态的逆问题。通过适应不同类型的污染分布(corruption distributions),同一数学模型适用于图像去噪、超分辨率和去模糊等问题。近年来,深度神经网络 (DNNs) 和生成对抗网络(GANs) [10] 在各种低层次视觉任务中表现出了优异的性能。
问题:尽管如此,这些方法中的大多数都 需要针对特定任务的成对训练数据,限制了它们在实际多媒体应用中的通用性、可扩展性和实用性。此外,监督力度大可能会导致训练过度拟合和对真实图像污染类型的泛化能力低。
-----------------------------------
下面的内容就是,既然监督学习有问题,就有了先前的无监督的方法,但是这些无监督方法还有问题。这就是本文要解决的根本问题(motivation)。
More recently, the domain transfer based unsupervised learning methods have attracted lots of attention due to the great progress [9, 18, 20, 21, 40] achieved in style transfer, attribute editing and image translation, e.g., CycleGAN [40], UNIT [21] and DRIT [18]. Although these methods have been expanded to specific restoration tasks, they could not reconstruct the high-quality images due to losing finer details or inconsistency backgrounds, as shown in Fig. 1. Different from DNNs based supervised models, which aim at learning a powerful mapping between the noisy and clean images. Directly applying existing domain-transfer methods is unsuitable for generalized image inverse problems due to the following reasons:
- Indistinct Domain Boundary.
Image translation aims to learn abstract shared-representations from unpaired data with clear domain characteristics, such as horse-to-zebra, day-to-night, etc. On the contrary, varying noise levels and complicated backgrounds blur domain boundaries between unpaired inputs.
- Weak Representation.
Unsupervised domain-adaption methods extract high-level representations from unpaired data by shared-weight encoder and explicit target domain discriminator. For slight noisy signals, it is easy to cause domain shift problems in translated images and lead to low-quality reconstruction.
- Poor Generalization.
Image translation learns a domain mapping from one-to-one image, which hardly captures the generalized semantic and texture representations. This also exacerbates the instability of GAN.
(a) Input (b) CycleGAN (c) UNIT (d) Ours
Figure 1: The typical results for Gaussian Noise. Our method has better ability on noise removal and texture preservation than other domain-transfer methods.
本段提出本文核心解决的问题:传统非监督方法存在的问题。
基于域迁移的无监督学习方法由于在风格迁移、属性编辑和图像翻译等方面取得了巨大的进展 [9,18,20,21,40],如 CycleGAN [40]、UNIT [20] 和 DRIT [18] 等,受到了广泛的关注。虽然这些方法已经扩展到特定的恢复任务,但由于丢失了更细的细节或背景不一致,无法重构出高质量的图像,如图1所示。不同于基于DNNs的监督模型,它的目标是学习一个噪声和干净的图像之间的映射。直接应用现有的域转移方法不适用于广义图像逆问题,主要有以下原因
- 模糊的域边界
图像翻译的目的是从没有配对的、具有明确的域特征的数据中学习抽象的共享表达从,如马到斑马,白天到夜晚等。但是相反,不同的噪声水平和复杂的背景模糊了未配对输入之间的域边界。
- 表达能力弱
无监督域适应方法通过共享权重编码器和显式目标域识别器从未配对数据中提取高级表示。对于轻微的噪声信号,在翻译后的图像中容易产生域漂移问题,导致重构的质量较低。
- 泛化能力差
图像转换从一对一图像中学习域映射,很难捕捉到广义的语义和纹理表示,加剧了 GAN 的不稳定性。
[20] Unpaired image-to-image translation using cycleconsistent adversarial networks. In ICCV, 2017
[21] Unsupervised image-to-image translation networks. In NIPS, 2017
[18] Diverse image-to-image translation via disentangled representations. In ArXiv, 2018
In order to address these problems, inspired by image sparse representation [24] and domain adaption [7, 8], we attempt to learn invariant representation from unpaired samples via domain adaption and reconstruct clean images instead of relying on pure unsupervised domain transfer. Different from general image translation methods [18, 21, 40], our goal is to learn robust intermediate representation free of noise (referred to as Invariant Representation) and reconstruct clean observations. Specifically, to achieve this goal, we factorize content and noise representations for corrupted images via disentangled learning; then a representation discriminator is utilized to align features to the expected distribution of clean domain. In addition, the extra self-supervised modules, including background and semantic consistency constraints, are used to supervise representation learning from image domains further.
为了解决这些问题,受图像稀疏表示和域自适应的启发 [7,8],本文通过域自适应从未配对样本中学习不变量表示,并重建干净的图像,而不是单纯依赖于无监督的域转移。与一般的图像迁移方法 [18,21,40] 不同,本文的目标是学习无噪声的高鲁棒中间表示(称为不变量表示 Invariant Representation),并重建干净的复原图像。具体来说,通过分离学习 disentangled learning 对损坏图像的内容和噪声表示进行分解;然后利用表示鉴别器对特征进行匹配,使特征符合干净域的期望分布。此外,本文还提出了额外的自监督模块,包括背景和语义一致性约束,用于监督进一步从图像域学习表示。
[7] Unsupervised domain adaptation by backpropagation. ArXiv, 2014
[8] Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2015
In short, the main contributions of the paper could be summarized as follows:
1) Propose an unsupervised representation learning method for image restoration based on data-driven, which is easily expanded to other low-level vision tasks, such as super-resolution and deblurring.
2) Disentangle deep representation via dual domain constraints, i.e., feature and image domains. Extra self-supervised modules, including semantic meaning and background consistency modules, further improve the robustness of representations.
3) Build an unsupervised image restoration framework based on cross domain transfer with more effective training and faster convergence speed. To our knowledge, this is the first unsupervised representation learning approach that achieves competing results for processing synthetic and real noise removal with end-to-end training.
三个主要贡献:
1. 提出了非监督表示学习方法,用于图像去噪、超分辨和去模糊;
2. 通过对偶域约束解决 disentangle 深度表示法;提出了一种自监督模型(包括语义和背景一致性模型);
3. 建立了一种基于跨域转移的无监督图像恢复框架,训练效果更好,收敛速度更快
Related Work
In general, DNNs-based methods could realize superior results on synthetic noise removal via effective supervised training, but it is unsuitable for real-world applications.
基于 DNNs 的方法不能很好的对真实图像修复。
Unsupervised Learning for IR
- Image Domain Transfer.
Another direction solves image restoration by domain transfer, which aims to learn one2one mapping from one domain to another and output image to lie on the manifold of clean image. Previous works, e.g., CycleGAN [40], DualGAN [37] and BicycleGAN [41] have shown great capacity in image translation. Expanding works, containing CouplesGAN [22], UNIT [21] and DRIT [18] learn shared-latent representation for diverse image translation. Along this way, Yuan et al. [38] proposed a nested CycleGAN to solve the unsupervised image super-resolution. Expanding DRIT, Lu et al. [23] decoupled image content domain and blur domain to solve image deblurring, referred to as DRNet. However, these methods aim to learn stronger domain generators, they require obvious domain boundary and complicated network structure.
通过域转换来实现图像的恢复,其目的是学习一个域到另一个域的 one2one 映射,将图像输出到干净图像的流形上。
然而,这些方法的目的是学习更强的域生成器,它们要求明显的域边界和复杂的网络结构。
The Proposed Method
Our goal is to learn abstract intermediate representations from noise inputs and reconstruct clear observations. In a certain way, unsupervised IR could be viewed as a specific domain transfer problem, i.e., from noise domain to clean domain. Therefore, the method is injected into the general domain transfer architecture, as shown in Fig. 2.
Figure 2: Method Overview. (a) The latent space assumption. Proposed method aims to learn invariant representations from inputs and align them via adversarial domain adaption.

本文提出的方法,根本的目的是 从噪声输入(和干净图像)中抽象中间表示(图 2 中的 ![]() ),然后利用这个表示重构干净图像。
),然后利用这个表示重构干净图像。
提前解释一下,这个 ![]() 包含三个内容:干净图像的图像中间表示
包含三个内容:干净图像的图像中间表示 ![]() ;噪声图像中的图像中间表示
;噪声图像中的图像中间表示 ![]() 和 噪声中间表示
和 噪声中间表示 ![]() 。
。
In supervised domain transfer, we are given samples
drawn from a joint distribution
, where
and
are two image domains. For unsupervised domain translation, samples
and
. In order to infer the joint distribution from the marginal samples, a shared-latent space assumption is proposed that there exists a shared latent code
in a shared-latent space
, so that we can recover both images from this code. Given samples
(1)
(2)
A key step is how to implement this shared-latent space assumption.
To do so, an effective strategy is sharing high-level representation by shared-weight encoder, which samples the features from the unified distribution. However, it is unsuitable for IR that latent representation only contains semantic meanings, which leads to domain shift in recovered images, e.g., blurred details and inconsistent backgrounds.
Therefore, we attempt to learn more generalized representations containing richer texture and semantic features from inputs, i.e., invariant representations. To achieve it, adversarial domain adaption based discrete representation learning and self-supervised constraint modules are introduced into our method.
在无监督方法中,样本  (本文表示有噪声样本)和
(本文表示有噪声样本)和  (无噪声样本,与 unpair)来自于边缘分布
(无噪声样本,与 unpair)来自于边缘分布 ![]() 和
和 ![]() 。
。
为了从边缘样本中推断出联合分布,提出了共享隐含(shared-latent)空间假设,即在共享隐含空间 ![]() 中存在一个共享隐含编码(shared latent code) 。关键的一步是如何实现共享潜在空间的假设。
中存在一个共享隐含编码(shared latent code) 。关键的一步是如何实现共享潜在空间的假设。
一种有效的策略是使用共享权重编码器共享高层表示,从统一分布中抽取特征。但是,由于潜在表示只包含语义,导致恢复后的图像出现域偏移,如细节模糊、背景不一致等,不适用于IR。
因此,本文从输入中学习更一般化的表示(包含更丰富纹理和语义特征),即不变量表示(invariant representations)。为了实现该方法,引入了基于对抗域自适应的离散表示学习和自监督约束模块。
Discrete Representation Learning
Discrete representation aims to compute the latent code
and
separately. Given any unpaired samples
and
separately denote noise and clean sample from different domains, Eq. 1 is reformulated as
and
. Further, IR could be represented as
.
However, considering noise always adheres to high-frequency signals, directly reconstructing clean images is difficult due to varying noise levels and types, which requires powerful domain generator and discriminator. Therefore, we introduce the disentangling representation into our architecture.
离散表示的目的是从输入中计算隐含代码 ,其中 包含尽可能多的纹理和语义信息。
为了实现离散表示,采用了两个自编码器组合的模型 ![]() 和
和 ![]() 。其中,
。其中,![]() 用来提取输入 (噪声图像)的隐含编码,即
用来提取输入 (噪声图像)的隐含编码,即 ![]() (同理
(同理 ![]() 是输入干净图像 的隐含编码);
是输入干净图像 的隐含编码); ![]() 表示将隐含编码生成噪声图像 的模型 (同理,
表示将隐含编码生成噪声图像 的模型 (同理,![]() 是生成干净图像 的模型)。将噪声图像重构为干净图像的过程就是
是生成干净图像 的模型)。将噪声图像重构为干净图像的过程就是 ![]() 。
。
但是,虑到噪声总是依附于高频信号,如果直接按照上述过程恢复干净图像是很难获得理想结果的,因为噪声的形式是多样的,采用 GAN 方法训练时,对生成器和判别器的要求很高。因此,将分离表示引入到本文的架构中。
Figure 2: Method Overview. (b) Our method is injected into general domain-transfer framework. Extra self-supervised modules are introduced to learn more robust representations.

- Disentangling Representation.
For noise sample
is used to model varying noisy levels and types. The self-reconstruction is formulated by
, where
. Assuming the latent codes
and
obey same distribution in shared-space that
, similar to image translation, unsupervised image restoration could be divided into two stages: forward translation and back reconstruction.
对于给定输入噪声图像 ,可以用噪声编码器 ![]() 对各种不同形式和程度的噪声进行建模。自重构通过
对各种不同形式和程度的噪声进行建模。自重构通过 ![]() 形式实现。其中,
形式实现。其中, ![]() ,
,![]() 。
。
假设 ![]() and
and ![]() 服从相同分布,并分享相同域
服从相同分布,并分享相同域 ![]() 。类似于图像翻译,无监督图像恢复可分为前向转换和后向重建两个阶段。
。类似于图像翻译,无监督图像恢复可分为前向转换和后向重建两个阶段。
- Forward Cross Translation.
We first extract the representations
from
. Restoration and degradation could be represented by
where
represents the recovered clean sample,
denotes the degraded noise sample. ⊕ represents channelwise concatenation operation.
and
are viewed as specific domain generators.

前向交叉转换(Forward Cross Translation):
首先,提取各种中间表示,干净图像的图像中间表示 ![]() ;噪声图像中的图像中间表示
;噪声图像中的图像中间表示 ![]() 和 噪声中间表示
和 噪声中间表示 ![]() 。
。
修复和降质的过程就是公式(3)和(4)表示。
其中,![]() 表示修复图像,
表示修复图像,![]() 表示降质图像。⊕ 表示通道级联。
表示降质图像。⊕ 表示通道级联。
- Backward Cross Reconstruction.
After performing the first translation, reconstruction could be achieved by swapping the inputs
where
and
denote reconstructed inputs. To enforce this constraint, we add the cross-cycle consistency loss
for
(7)
(8)

向后交叉重建(Backward Cross Reconstruction):
在执行第一次转换后,可以通过交换输入来实现重构。 和 表示重构输入。为了加强这一约束,添加了 和 ![]() 的 cross-cycle 一致性损失,就是将重构的噪声图像 和原始噪声图像 做 L1 损失;将重构的干净图像 与原始图像 做 L1 损失。
的 cross-cycle 一致性损失,就是将重构的噪声图像 和原始噪声图像 做 L1 损失;将重构的干净图像 与原始图像 做 L1 损失。
- Adversarial Domain Adaption.
Another factor is how to embed latent representations
is utilized in our architecture. We express this feature adversarial loss
as

另一个因素是如何嵌入表征 ![]() 和
和 ![]() 到共享空间。受无监督域自适应的启发,用对抗式学习代替共享权重编码器来实现。
到共享空间。受无监督域自适应的启发,用对抗式学习代替共享权重编码器来实现。
本文的目标是促进遵从相似分布的输入的表示,同时保留输入的更丰富的纹理和语义信息。
因此,采用了表示判别器 ![]() ,并引入特征对抗的损失(9)。
,并引入特征对抗的损失(9)。
Self-Supervised Constraint
Due to lack of effective supervised signals for translated images, only relying on feature domain discriminant constraints would lead to domain shift problems inevitably in generated images. To speed convergence while learning more robust representations, self-supervised modules including Background Consistency Module (BCM) and Semantic Consistency Module (SCM) are introduced to provide more reasonable and reliable supervision.
由于转换后的图像缺乏有效的监督信号,仅依靠特征域判别约束,不可避免地会导致生成的图像出现域偏移问题。为了在学习鲁棒表示的同时加快收敛速度,引入了自监督模块,包括背景一致性模块 (BCM) 和语义一致性模块 (SCM),以提供更加合理和可靠的监督。
BCM aims to preserve the background consistency between the translated images and inputs. Similar strategies have been applied for self-supervised image reconstruction tasks [14, 28]. These methods use the gradient error to constrain reconstructed images by smoothing the input and output images with blur operators, e.g., Gaussian blur kernel and guided filtering [13]. Different from them, a L1 loss is directly used for the recovered images instead of gradient error loss in our module, as shown in Fig. 3, which is simple but effective to retain background consistency while recovering finer texture in our experiments. Specifically, a multiscale Gaussian-Blur operator is used to obtain multi-scale features respectively. Therefore, a background consistency loss
could be formulated as:
where
denotes the Gaussian-Blur operator with blur kernel
,
is the hyper-parameter to balance the errors at different Gaussian-Blur levels.
denote original input and the translated output. Based on experimental attempts at image denoising, we set
respectively.
BCM 的目的是保持转换图像和输入图像之间的背景一致性。类似的策略也被应用于自监督图像重建任务 [14,28]。这些方法利用梯度误差来约束重构图像,通过使用模糊算子 (如高斯模糊核和引导滤波[13]) 来平滑输入和输出图像。不同的是,本文对恢复的图像直接使用了 L1 损失,而不是梯度误差损失,如图 3 所示。本文利用多尺度高斯模糊算子分别获取多尺度特征。
In addition, inspired by perception loss [15], the feature from the deeper layers of the pre-trained model contain semantic meanings only, which are noiseless or with little noise. Therefore, different from the general feature loss, which aims to recover finer image texture details via similarities among shallow features, we only extract deeper features as semantic representations from the corrupted and recovered images to keep consistency, referred to as semantic consistency loss
. It could be formulated as
where φ(·) denotes the features from lth layer of the pretrained model. In our experiments, we use the conv5-1 layer of VGG-19 [31] pre-trained network on ImageNet.
预训练模型的更深层次特征只包含语义意义,无噪声或噪声很小。
一般的 VGG losss 采用浅层特征间的相似性来恢复较细图像纹理细节的特征丢失。
而本文选择较深的特征作为语义表征,用来保持损坏和恢复的图像在语义上的一致性。
Jointly Optimizing
除了所提出的 cross-cycle 一致性损失、表示对抗损失和自监督损失外,我们还在联合优化中使用了其他损失函数。
- Target Domain Adversarial Loss.
We impose domain adversarial loss
, where
and
attempt to discriminate the realness of generated images from each domain. For the noise domain, we define the adversarial loss
as
Similarly, we define adversarial loss for clean image domain as
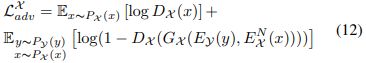
Domain Adversarial Loss 中的两个图是输入来自同一个 domain。判别器努力鉴别两张图不属于同一域(干净域或不干净域);生成器生成努力生成的图像属于相同域。增强了 ![]() ,
,![]() 的能力。
的能力。
- Self-Reconstruction Loss.
In addition to the cross-cycle reconstruction, we also apply a self-reconstruction loss
to facilitate the training. This process is represented as
and
.
看图 2,我们发现, ![]() 的输入来自
的输入来自 ![]() 域,
域,![]() 的输入来自 域。而 Self-Reconstruction 损失是指,当
的输入来自 域。而 Self-Reconstruction 损失是指,当 ![]() 的输入来自 域时,输出也应该是 域的,这样的
的输入来自 域时,输出也应该是 域的,这样的 ![]() 才是合理可信的。
才是合理可信的。![]() 同理。
同理。
- KL Loss.
In order to model the noise encoder branch, we add a KL divergence loss to regularize the distribution of the noise code
to be close to the normal distribution that
where DKL =
.
考虑到噪声的特点,生成的噪声中间表达 ![]() 的分布特征应该与 正态分布 近似,这个近似用 KL发散损失 来衡量。
的分布特征应该与 正态分布 近似,这个近似用 KL发散损失 来衡量。
总体的损失函数就是如下了
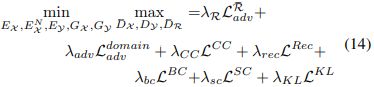
- Restoration:
After learning, we only retain the cross encoder-generator network
最后,用于测试的网络参数只有生成器 ![]() ;前者用于生成域不变表示
;前者用于生成域不变表示 ![]() ;后者用于生成最终的修复图像
;后者用于生成最终的修复图像 ![]() 。
。