RoBERTa、ERNIE2、BERT-wwm-ext和SpanBERT

对于NLP来说,上个月(7月)是一个摩肩接踵的时刻,几大预训练模型轮番PK,群雄逐鹿中原。从7月26号的RoBERTa到7月29号的ERNIE2,再到7月30号的BERT-wwm-ext,再到7月31号的SpanBERT,其中RoBERTa引起大家的热论。
先上一张有意思的图:(来至知乎作者Andy Yang)

RoBERTa
从模型上来说,RoBERTa基本没有什么太大创新,主要是在BERT基础上做了几点调整:
1)动态Masking,相比于静态,动态Masking是每次输入到序列的Masking都不一样;
2)移除next predict loss,相比于BERT,采用了连续的full-sentences和doc-sentences作为输入(长度最多为512);
3)更大batch size,batch size更大,training step减少,实验效果相当或者更好些;
4)text encoding,基于bytes的编码可以有效防止unknown问题。另外,预训练数据集从16G增加到了160G,训练轮数比BERT有所增加。
更多介绍见:RoBERTa:高级丹药炼制记录(开头非常精彩的一段炼丹玄学值得品味)
ERNIE2
ERNIE2是百度在ERNIE1基础上的一个升级版,不过这次升级幅度比较大,提出了一个持续学习的机制(continual learning)。这个机制比较有意思,有点模仿人学习的形式。我们人是在不断学习,并且是多种任务不停交叉学习。有人觉得工作后就不用学习了,但其实工作才是真正学习的开始。上学期间你可能只是单纯地学习,但在工作中需要快速边做边学(learning by doing,不知道这种机制能否引入到AI中),这时候更能体现一个人的快速学习能力。稍微扯远了,回归下正题。持续学习包括持续构建预训练任务和增量多任务学习两个部分,具体下图:
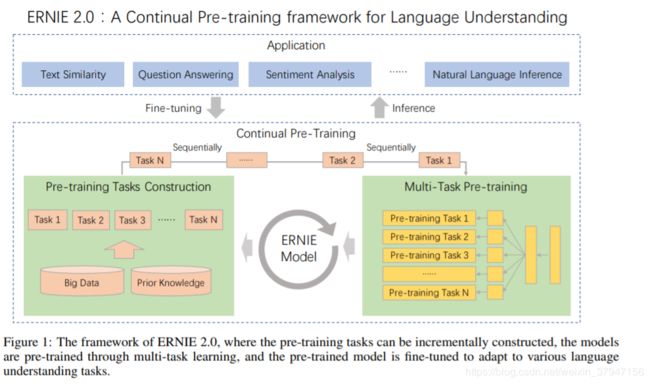
连续预训练的架构如下图,它包含一系列共享的文本编码层来编码上下文信息,这些文本编码层可以通过循环神经网络或 Transformer 构建,且编码器的参数能通过所有预训练任务更新。
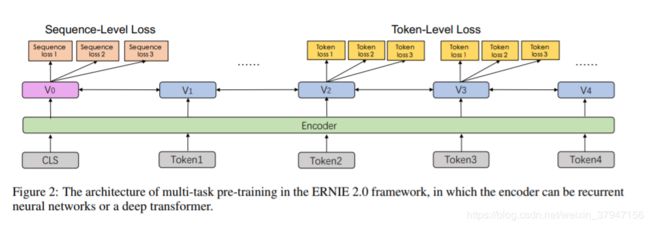
不同于ERNIE1仅有词级别的Pretraining Task,ERNIE2考虑了词级别、结构级别和语义级别3类Pretraining Task,词级别包括Knowledge Masking(短语Masking)、Capitalization Prediction(大写预测)和Token-Document Relation Prediction(词是否会出现在文档其他地方)三个任务,结构级别包括Sentence Reordering(句子排序分类)和Sentence Distance(句子距离分类)两个任务,语义级别包括Discourse Relation(句子语义关系)和IR Relevance(句子检索相关性)两个任务。三者关系如图:
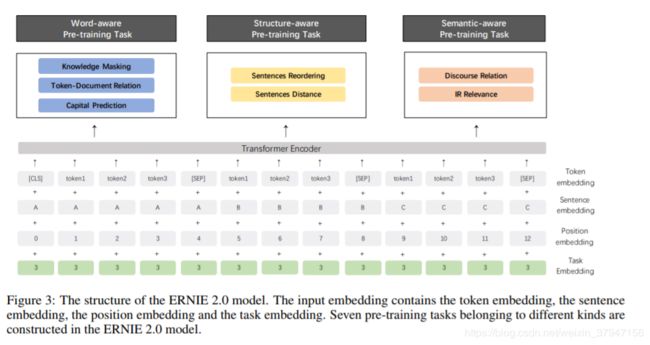
就pre-train的多任务loss而言,个人觉得已经考虑很全了,并且个人之前也比较看好pre-train multi-task学习方向。BERT某种程度上也是一个multi-task学习,包含两个loss。虽然RoBERTa和其他一些文章说next prediction loss已是非必须,但multi-task始终是一个可以前进的方向,尤其是在数据和模型结构不变的情况下,使用multi-task理论上会有些提升。当然multi-task的不足在于如何有效训练多任务,ERNIE2采用了持续学习的机制,多个任务轮番学习,这有点类似于我们人上学,这节课学语文,下节课学数学,再下节课学英语。预训练数据相比BERT来说有所增加,英文约增加了2倍,中文约增加了1倍多。
ERNIE2要优于BERT和XLNet。但也有两点疑惑:
- 作者为什么不再探索下多任务带来的效果到底有多少,可以在定量分析下。要不然现在的结果到底多少是数据带来的,多少是多任务带来的,其实并不清楚,multi-task这条路到底能走多远没有给出答案;
- RoBERTa与ERNIE2相比,RoBERTa英文数据增加了10倍,ERNIE2数据应该是增加两倍,但做了很多模型loss上的增加,从GLUE效果上看,显然RoBERTa要比ERNIE2好一些,这是不是反映模型改进提升有限,当前还是多增加预训练数据效果来得更快些。
BERT-wwm-ext
BERT-wwm-ext是由哈工大讯飞联合实验室发布的中文预训练语言模型,是BERT-wwm的一个升级版。
BERT-wwm-ext主要是有两点改进:
- 预训练数据集做了增加,次数达到5.4B;
- 训练步数增大,训练第一阶段1M步,训练第二阶段400K步。
Whole Word Masking (wwm),暂翻译为全词Mask或整词Mask,是谷歌在2019年5月31日发布的一项BERT的升级版本,主要更改了原预训练阶段的训练样本生成策略。 简单来说,原有基于WordPiece的分词方式会把一个完整的词切分成若干个子词,在生成训练样本时,这些被分开的子词会随机被mask。 在全词Mask中,如果一个完整的词的部分WordPiece子词被mask,则同属该词的其他部分也会被mask,即全词Mask。
需要注意的是,这里的mask指的是广义的mask(替换成[MASK];保持原词汇;随机替换成另外一个词),并非只局限于单词替换成[MASK]标签的情况。 更详细的说明及样例请参考:#4
同理,由于谷歌官方发布的BERT-base, Chinese中,中文是以字为粒度进行切分,没有考虑到传统NLP中的中文分词(CWS)。 我们将全词Mask的方法应用在了中文中,使用了中文维基百科(包括简体和繁体)进行训练,并且使用了哈工大LTP作为分词工具,即对组成同一个词的汉字全部进行Mask。
下述文本展示了全词Mask的生成样例。 注意:为了方便理解,下述例子中只考虑替换成[MASK]标签的情况。
| 说明 | 样例 |
|---|---|
| 原始文本 | 使用语言模型来预测下一个词的probability。 |
| 分词文本 | 使用 语言 模型 来 预测 下 一个 词 的 probability 。 |
| 原始Mask输入 | 使 用 语 言 [MASK] 型 来 [MASK] 测 下 一 个 词 的 pro [MASK] ##lity 。 |
| 全词Mask输入 | 使 用 语 言 [MASK] [MASK] 来 [MASK] [MASK] 下 一 个 词 的 [MASK] [MASK] [MASK] 。 |
中文模型下载
由于目前只包含base模型,故我们不在模型简称中标注base字样。
BERT-base模型:12-layer, 768-hidden, 12-heads, 110M parameters
| 模型简称 | 语料 | Google下载 | 讯飞云下载 |
|---|---|---|---|
BERT-wwm-ext, Chinese |
中文维基+ 通用数据[1] |
TensorFlow PyTorch |
TensorFlow(密码thGd) PyTorch(密码bJns) |
BERT-wwm, Chinese |
中文维基 | TensorFlow PyTorch |
TensorFlow(密码mva8) PyTorch(密码8fX5) |
BERT-base, ChineseGoogle |
中文维基 | Google Cloud | - |
BERT-base, Multilingual CasedGoogle |
多语种维基 | Google Cloud | - |
BERT-base, Multilingual UncasedGoogle |
多语种维基 | Google Cloud | - |
[1] 通用数据包括:百科、新闻、问答等数据,总词数达5.4B
以上预训练模型以TensorFlow版本的权重为准。 对于PyTorch版本,我们使用的是由Huggingface出品的PyTorch-Transformers 1.0提供的转换脚本。 如果使用的是其他版本,请自行进行权重转换。
中国大陆境内建议使用讯飞云下载点,境外用户建议使用谷歌下载点,base模型文件大小约400M。 以TensorFlow版BERT-wwm, Chinese为例,下载完毕后对zip文件进行解压得到:
chinese_wwm_L-12_H-768_A-12.zip
|- bert_model.ckpt # 模型权重
|- bert_model.meta # 模型meta信息
|- bert_model.index # 模型index信息
|- bert_config.json # 模型参数
|- vocab.txt # 词表
其中bert_config.json和vocab.txt与谷歌原版BERT-base, Chinese完全一致。 PyTorch版本则包含pytorch_model.bin, bert_config.json, vocab.txt文件。
SpanBERT
详细介绍见:解读SpanBERT:《Improving Pre-training by Representing and Predicting Spans》
参考文献:
- RoBERTa
- ERNIE2
- BERT-wwm-ext
- XLNet团队:只要公平对比,BERT毫无还手之力
- XLNet中文预训练和阅读理解应用
- 哈工大讯飞联合实验室
-
RoBERTa、ERNIE2和BERT-wwm-ext