520小玩意之Python词云:导出与女票的微信聊天记录并分析
用python看看自己和女票都聊了些什么事
最终效果图:

一、导出微信聊天文件
写2种导出聊天记录的方法:一种是Mac版微信,另一种是iOS版微信。
1.导出Mac版微信聊天记录
Mac版微信在本地存放了聊天记录的数据库,数据库使用的是开源的 sqlcipher加密了里面的数据。在终端输入下面命令,可以查看这些数据库的路径。
ls -alh ~/Library/Containers/com.tencent.xinWeChat/Data/Library/Application\ Support/com.tencent.xinWeChat/*/*/Message/*.db
利用lldb可以解密这些数据库方法如下:
-
打开微信
-
命令行运行
lldb -p $(pgrep WeChat) -
在 lldb 中输入
br set -n sqlite3_key, 回车 -
还是在 lldb 中,输入 c, 回车
-
扫码登录微信
-
这时候回到 lldb 界面, 输入
memory read --size 1 --format x --count 32 $rsi, 回车 -
应该会输出类似于如下的数据
0x6000009736e0: 0x05 0x41 0x59 0x3d 0xc6 0xe5 0x47 0x73 0x6000009736e8: 0x84 0x1e 0xb3 0xa9 0xd9 0x29 0x77 0x31 0x6000009736f0: 0x58 0xc0 0x1a 0x6c 0x66 0xaf 0x43 0x4c 0x6000009736f8: 0xac 0x1f 0x6f 0x03 0x9b 0x7e 0xc1 0xfa -
把数据从左到右,从上到下,把形如 0xab 0xcd 的数据拼起来,然后去掉所有的 "0x"和空格、换行, 得到 64 个字符的字符串,例如
0541593dc6e54773841eb3a9d929773158c01a6c66af434cac1f6f039b7ec1fa,这就是 微信数据库的 key. -
然后, 可以下载个 https://sqlitebrowser.org ,用来浏览之前提到的*.db 文件(每个 db 都使用的相同的 key ),注意:打开数据库的时候选择(raw key), 然后输入 0x,再输入刚才那 64 个字符
-
打开后如下:
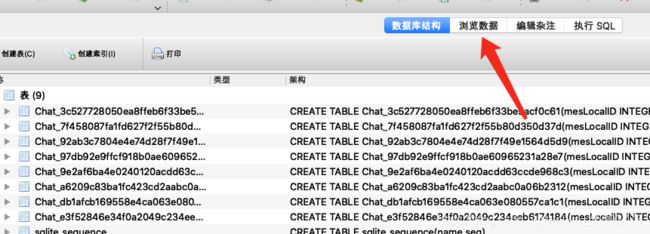
-
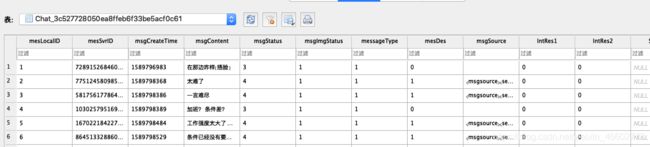
然后找到与女票的那个表单,导出聊天内容为csv文件
2.导出iOS手机微信聊天记录
手机上数据库是加密的,但是手机备份出来的却是明文的数据,所以我们直接用最简单的,从备份拿数据,我这里用爱思助手搞了。
- 打开爱思助手然后点击 工具箱->备份/恢复数据->选择全备份,然后等几分钟备份完成,打开全备份文件管理。
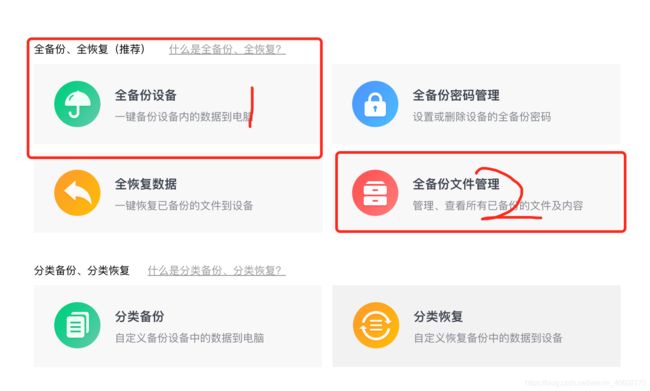
- 点击立即查看

- 列表有一个
AppDomain-com.tencent.xin的文件夹 ,进入之后爱思能直接查看微信聊天记录

4.选择聊天记录导出就可以了。
二、Python + jieba + wordcloud
聊天记录有了,就可以分词生成词云了,直接上代码
import csv, jieba, re
from itertools import islice
import pandas as pd
import imageio
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator, wordcloud
# 从导出的csv格式聊天记录中提取中文存入txt文件中
def csv_to_txt():
chat_csv = open("wechatliaotian.csv","r",encoding="utf-8") #chatlog.csv 改成自己的聊天记录文件名
my_chat = csv.reader(chat_csv)
fp = open("newChat.txt", "w+", encoding="utf-8")
for line in islice(my_chat, 1, None):
if re.search("[\u4e00-\u9fa5]", line[0]) and len(line[0]) < 50:
fp.write(line[0])
fp.write("\n")
fp.close()
# 处理txt文件
def txt_to_format():
fp = open("chat.txt", "r", encoding="utf-8")
newFp = open("newChat.txt", "w", encoding="utf-8")
for line in fp.readlines():
curLine=line.strip().split(" ")
if(len(curLine) == 4):
newFp.write(curLine[3] + "\n")
fp.close()
newFp.close()
# 对聊天记录文件进行分词
def cut_words():
# 把聊天内容读取给content
fp = open("newChat.txt", "r", encoding="utf-8")
content = fp.read()
fp.close()
jieba.load_userdict("dict.txt") # 载入自定义词典(格式:一个词占一行;每行分为:词语、词频(可省略)、词性(可省略),用空格隔开)
words = jieba.cut(content, cut_all=True) # 进行分词,模式:精确模式
word_L = [] # 把分词结果存入word_L中
# 加载停用词
with open("stopwords.txt", 'r', encoding="utf-8") as ss:
stopwords = ss.read()
# 把符合的词语存入word_L中
for word in words:
if word not in stopwords and word != '\n' and len(word) > 1:
word_L.append(word)
return word_L
# 生成词云
def word_cloud(words):
# 对分词结果进行频率统计再转换成字典
count_word_df = pd.DataFrame({"word":words}).groupby(["word"]).size()
count_word_dt = count_word_df.to_dict()
mk = imageio.imread('my_pic.jpg') # 设置词云形状
mk_color = ImageColorGenerator(mk) # 设置词云颜色
# 配置词云参数
wx_wc = WordCloud(
background_color="white", # 如果是透明背景,设置background_color=None
mode="RGB", # 如果是透明背景,设置mode="RGBA"
mask=mk, # 词云形状
font_path="/System/Library/Fonts/Songti.ttc", # 字体可以更改为自己喜欢的字体
# scale=3, # 如果输出图片大小不满意,则修改此值
)
wx_wc = wx_wc.generate_from_frequencies(count_word_dt) # 把带频率的分词结果导入词云
wx_wc.to_file("wordcloud.png") # 输出词云图片,未设置颜色
# plt输出图片
plt.axis("off") # 关闭坐标轴
plt.imshow(wx_wc.recolor(color_func=mk_color)) # 设置颜色
plt.savefig('pltwordcloud.png', dpi=400) # 输出词云图片,以原图片为背景色
def run():
# csv_to_txt()
txt_to_format()
words = cut_words()
word_cloud(words)
#
if __name__ == "__main__":
# txt_to_format()
run()
如果是导出的csv文件就执行csv_to_txt()方法。是爱思助手导出的txt文件就调用txt_to_format()方法。
三、demo地址
demo地址:
bd云盘:https://pan.baidu.com/s/1Wp7bxyxjOyITa38coX9TYw
密码:9bwv
如有帮助,关注,点赞,收藏来一套,有问题可留言解决。
@end