编程之美之扩展问题
参考链接:
http://blog.csdn.net/wuyuegb2312/article/details/9896831
http://www.cnblogs.com/wuyuegb2312/p/3185083.html
http://www.cppblog.com/flyinghearts/archive/2010/09/01/125550.html
1.1 让CPU占用率曲线听你指挥
参考:
http://blog.csdn.net/wesweeky/article/details/6402564
http://www.cnblogs.com/chenyuming507950417/archive/2012/09/14/2685097.html
1.2 中国象棋将帅问题
解法二用进制的方法好理解一些,但以下参考中有人用多重循环转换的方式解释也可以理解
参考:
http://book.douban.com/annotation/13753057/
http://blog.csdn.net/kabini/article/details/2256421
http://blog.csdn.net/silenceburn/article/details/6133222
1.3 一摞烙饼的排序
递归遍历+上界下界剪枝+状态记录
http://blog.csdn.net/zuiaituantuan/article/details/6056601
扩展问题:
1多了一个脑袋可以放饼,速度肯定会加快,基本思路是将饼堆分为两部分,第一部分中最大值小于第二部分(或第一部分最小值大于第二部分,或者这样说,第一部分是大小是123,第二部分是456,只是都乱序),然后两部分分别排序,最后再合并
参考:http://www.cnblogs.com/avenxia/archive/2012/09/13/2683094.html
2
A 先按照“烙饼排序实现”对烙饼进行大小排序
B 然后对有金黄色不朝上的烙饼做如下操作,以cakeArray[k]为例
翻转cakeArray[0:k],将cakeArray[k]翻到顶层,翻转cakeArray[k],然后将cakeArray[0:k]翻转,将cake[k]翻回原来位置
3概率是2/3
4可以猜测出将会优先把最上面的部分有序,逐渐到下面形成有序,具体的规则没有想到,代码仍然是遍历,只是将次数作界限改为翻转饼个数
仍然参考:http://www.cnblogs.com/avenxia/archive/2012/09/13/2683094.html
5最大下办15N/14,最小上界(5N+5)/3
第14个烙饼数P14=?
1.4 买书问题
参考:
http://blog.csdn.net/kabini/article/details/2296943 // 注意评论 第6楼举的例子
贪心算法与动态规划的理解
此问题贪心算法不适用(或者暂时未找到合适的贪心算法)
动态规划时间复杂度为O(Y1*Y2*Y3*Y4*Y5)// by zjerry 如何理解这个?
1.5 快速找出故障机器
利用O(1)空间解决唯一ID值不同的问题,需要用到异或的特性,连续异或可以理解为位的连续求异存同(其实是求奇弃偶),最终得到的值就是唯一ID值(没有相同的ID与他相同得到0)
两个不同值根据异或结果某一位上的1,将原ID集合分为两类,该位上有1和无1,再分别连续异或
另解法:构造方程,求一个值,利用原正常ID构造和,然后减去现有,剩下值即为所求;求两个值,可以构造x+y,x^2+y^2
扩展问题:
3个值或3个以上的情况下可以考虑构造方程,
也可以考虑用hashMap保存ID,然后过滤正常ID
扑克问题:用原和减去剩下的和
1.6 饮料供货
动态规划
贪心
参考:http://blog.csdn.net/lichaoyin/article/details/9983883
动态规划思路基本上是背包问题
贪心算法利用到了进制分解,将容量以二进制看待,设计数据结构:每一位后有一条最大值链表,算法:从低位到高位,该位需要容量填充时就从每一位后的有序链表中得到满意度最大的若干容量相加,计算之前先将上一个低位的最大值合并到新的链表中(有些类似哈夫曼树的构造过程?)
1.7 光影切割问题
解法一:分析出每增加一直线,如果增加m个交点,那么该直线被新增加的m个交战分成m+1段,每一段又会将原区域划成两块,于是新增加了m+1块
如果有n条直线,m个交点,那么区域数为n+m+1,求解过程是1+求和(m0+1)=1+n条直接的全部交点和+n=1+m+n // 因为每次增加m0+1,n个点求和
切割块数先将所有点的交点求出来,然后排序,锁定AB之间的点(二分查找),再利用1+n+m计算出块数
解法二:
区域内的交战数目等于一个边界上交点顺序相对另一个边界交点顺序的逆序总数,求逆序数利用分治法可以优化到O(n*logn)
// by zjerry 这个转换过程没完全理解,为什么逆序数会=交点数?
1.8 小飞的电梯调试算法
如何从O(N^2)优化到O(N)的关键是找到遍历过程相邻之间的增减关系
扩展问题
1仍然用书中的解法二,O(N)时间内解决,
2// by zjerry 还要再想想
1.9 高效率地安排见面会
http://blog.csdn.net/chdhust/article/details/8333567
http://www.cppblog.com/flyinghearts/archive/2010/08/15/123536.html
原问题是NP的经典问题 地图着色
扩展问题:
1.基于时间轴的活动地点选择问题,由于可以向一维时间轴投影,所以可以使用贪心算法
书中O(N^2)解法没仔细理解(应该是类似着色判断是否合理的算法),
主要理解第二个解法:直接计算某区间最大重叠次数,如果利用计数排序+一次MAX值扫描,可以优化到O(N) // by zjerry
2.问题的前提还是在优化总的时间基础上,因此只能原问题的基础上扩张结构以实现集中
我的想法是,同学对见面会的兴趣度可以理解为图中的边的权重,让每个都集中也就是总体集中
顶点着色数量设计好后,顶点起始时间排序,起始时间相同则按照上一顶点与欲选择顶点的兴趣度排序,最后得到结果
1.10 双线程高效下载
// by zjerry 信号量,互斥锁
1.11 NIM(1)一排石头的游戏
注明A先取,B后取
扩展
1.N=3K+1(K=0,1,2,……)时先取者A输,其余情况N=3K,N=3K+2时先取者A赢
http://blog.csdn.net/dreamvyps/article/details/22264903
http://hi.baidu.com/hehehehello/item/4115b9151a2f29fd756a8487
2.N%(K+1)=0时,玩家B有必胜策略,N%(K+1)!=0时,玩家A有必胜策略。
当d=0时,无论A取多少个石头,B取相应的石头,使得A和B一起取(K+1)个石头,这样最后取到石头的肯定是玩家B。
1.12 NIM(2)"拈"游戏分析
注明A先分配,B先取,A后取
http://www.cnblogs.com/yintingru/archive/2012/08/27/2658483.html
取石头的过程与上一次他人取的数目始终保持一个"安全的状态",即可以确保完胜,这里安全的状态是XOR为0
扩展问题
1如果取光者输,当N=2,B先取,A必输,N>2,A必胜,只要确保堆数为奇,个数也为奇即可,N为奇数,则分配(1,1,1,...),N为偶数,则分配(N/2,N/2)
2若是先取光者胜,则A保持安全状态为每次取走和为K+1(与1.11扩展问题类似),且每堆的个数为>=2(关键是取到只剩下K+1,K+2...K+K-1堆时的抉择问题上)
// by zjerry 未仔细认证,先到这里
1.13 NIM(3)两堆石头的游戏
注意A先取, B后取,AB可以两堆中各拿相等数量的石头或从一堆中取走任意
http://www.cnblogs.com/flyinghearts/archive/2011/03/22/1991972.html
扩展
1.A先取始终构造不安全局面给B,即可确保必胜(前提是初始状态为安全)
2.NIM(4)
http://blog.sina.com.cn/s/blog_7689f89d01017u6y.html
http://episte.math.ntu.edu.tw/articles/mm/mm_03_2_02/index.html // by zjerry 台大数学系网站,希望两岸统一,网站可以持久访问
1.14 连连看游戏设计
扩展问题:
1.维护任意两个格子的最短路径的优点是,每次刷新最短路径数据后都能迅速判断,但刷新数据的过程会比较麻烦,因为连连看消去后牵扯的格子并不能立即确定出来,很大可能要维护刷新所有格子,则N*O(N)复杂度,效率不一定高,
游戏中是否用点击触发的范围修改还是全局维护数据修改,这类问题类似于动态查找树如红黑树,二叉堆,能否在O(logn)可接受的时间范围内解决问题
2.每执行完一步下棋操作后,用某种数据结构保存当前棋局,如压缩矩阵,邻接矩阵,位图等
1.15 构造数独
http://blog.csdn.net/kabini/article/details/2598524
扩展问题:
如何表示桌面程序中的窗口/按钮/控件?// by zjerry 我一般想到的是制定合理的坐标系,如右x下y外z,然后每个窗口的属性有左上角坐标xy,长length,宽width,z轴z-order,能否点击clickable,性质(window,button,widget,etc)
1.16 24点游戏
http://blog.csdn.net/jcwkyl/article/details/3931586
http://blog.csdn.net/linyunzju/article/details/7680913
http://www.cppblog.com/flyinghearts/archive/2010/08/01/121907.html
http://www.cppblog.com/flyinghearts/archive/2010/08/15/123531.html
解法一:穷举递归 优化:剪枝,加法和乘法满足交换律,swap使A>B或A 解法二:集合的分治求解 优化:最后一次两个子集合并直接计算判断是否24点,不用再进行集合合并后再判断;依照解法一,每次取两个数计算然后合并集合(按书中每次按1,n-1来分解集合,分解集合的过程太多) 1.17 俄罗斯方块游戏 扩展问题 1.需要DFS记录移动路径 2.OFFSETY增加2格,则OFFSETX的判断范围减少3 3.俄罗斯广场是消除类游戏,优先考虑消除(使游戏更轻松),如添加子弹方块,添加爆炸方块,添加消除方块;再考虑增长(使游戏更困难),如添加变形方块,添加移动加速,添加下落后的方块会自动向上增长,且带小洞,自动左右循环,初始带有小洞的层次, 非游戏功能上的扩展可以有:积分社交排行功能,二人PK,在线PK,且PK带有战斗模式,A方消除造成B方增长 扫雷游戏是判断类游戏,优先考虑降低难度,如增加提示,减少雷数,再考虑增加难度,如可改变格子数目,可调整雷数,时间缩短,雷有轻重缓急的等级, 非游戏功能上的扩展积分社交排行,二人PK,互相设置对方的雷区等 1.18 挖雷游戏 参考: http://blog.csdn.net/wuyuegb2312/article/details/9302915 问题1 需要先解决问题2 问题2 1.根据已有数字将确定有雷和无雷的地区标记出来,然后将确定有雷的8邻区计数-1,清除该块,将确定无雷的8邻区计数+1,清除该块,依次解决出已点出区域的邻区 2.步骤1解决后,可确定雷数已知,然后利用已知区域相交的结合点来划分子雷区,再根据古典概率计算子雷区的每个点的概率 参考4.11 扫雷游戏的概率 2.1求二进制中1的个数 解法: 6.二分法,或三个一组的位操作方法 SSE4.2:POPCNT指令算法 HAKMEM算法 或写成 扩展 问题一是问32位整型如何处理,用HAKMEM算法,建表,或相与的方法都合适。 只要先算出A和B的异或结果,然后求这个值中1的个数就行了。 2.2不要被阶乘吓倒 1.求N!末尾有多少个0 相关题目: 给定整数,判断是否是2的方幂 即n>0&&(n&(n-1)==0) // 该数二进制表示法只有一个1 2.3寻找发帖水王 寻找可重复数据中出现次数超过一半的项 扩展问题 问题一 1当前位=0,则当前位上出现1的数目=高位*R 2当前位=1,则数目=高位*R+(低位数字+1) 3当前位>1,则数目=(高位+1)*R 扩展 参考:(// by zj 暂时未思考这问题) 给定二进制数N,写下从1开始到N的所有二进制数,数一下其中出现的所有“1”的个数: 2.5 寻找最大的K个数 利用简单排序算法:冒泡排序,选择排序,O(N*K) 利用快速排序的递归方法,判断每次快排后的K左右两边数组大小 寻找最大的K个=寻找第K大,进而可以根据数的本质大小顺序进行二分查找(整数的话可以从二进制角度理解) 扩展问题 1感觉上述方法都行 2个人觉得可以用小根堆来先求出m个最大的,然后从中输出k到m个 3网上答案:可以采用小顶堆来实现,使用映射二分堆,可以使更新的操作达到O(logn)。// HASH,红黑树之类的 // 需要将全部网页数据加入到堆中 4网上答案:答:正如提示中所说,可以让每台机器返回最相关的K'个文档,然后利用归并 5网上答案:答:肯定是有帮助的。 qi最相关的K个文档可能就是qj的最相关的K个文档,可以先假 2.6 精确表达浮点数 分情况讨论,推导通用公式 2.7 最大公约数 辗转相除法 2.8 找符合条件的整数 参考: http://blog.csdn.net/jcwKyl/article/details/3859155 扩展问题一 题目:任意给定一个正整数N,求一个最小的正整数M(M>1),使得N*M的十进制表示形式里只含有1和0. 解决这个问题首先考虑对于任意的N,是否这样的M一定存在。可以证明,M是一定存在的,而且不唯一。 这是一个无穷数列,但是数列中的每一项取值范围都在[0, N-1]之间。所以这个无穷数列中间必定存在循环节。即假设有s,t均是正整数,且s 例如,取N=3,因为10的任何非负次方模3都为1,所以循环节周期为1.有: 给定N,求M的方法: 另编程之美思路与上面一致,都是同余剪枝,构造1,0的数遍历,将该数z分解为z=a+b,然后利用余数信息数组中a%N+b%N的值再%N,计算z%N的值; 思路用到的数学公式是 (a+b)%c=(a%c+b%c)%c 例如: 计算110时,100模N的值已经得到为1,110%N=(100%N(1)+10%N(1))%N=2 扩展问题二 找出满足题目要求的N和M,使得N*M<2^16,且N+M最大 如果N已知则求M,然后求MAX(N+M), 2^16=65536,只有5位 如果N未知,根据数学公式可以有N*M一定,N+M最小则,N==M,N+M最大一定是N很小或M很小的情况(具体推导过程不好编辑,先扔一边) 给定N=1,然后M=N*M,即为所求// by zj 看了下题目,N为正整数,M>1,求一个最小的正整数,这个题意真不好理解了.... 2.9斐波那契(Fibonacci)数列 思路 1递归,问题有很多重复 2带记录的向后计算 3特征方程求解,但会产生无理数问题 4矩阵计算,其中可以用到二分求幂法,时间复杂度进化为O(LOGN) 扩展问题 构造方幂型矩阵,当N很大时,可以计算出MOD的结果,每一次计算都求MOD 2.10 寻找数组中的最大值和最小值 从2N减少到1.5N,主要是两两为一单位进行MAX 和MIN的比较 扩展问题 求次大值 思路1是MAX SECOND, 如果X比MAX大,则SECOND=MAX,MAX=X; 如果X比MAX小,则X与SECOND比较再交换 比较次数在N到2N之间 思路2仿照求最大值最小值 MAX SECOND 每两个为一组,A[I]小于A[I+1] 如果MAX 如果MAX>A[I+1],则再比较A[I+1]与SECOND;// 注意这点 走到这里,下句要跳过,因为A[I+1]比A[I]大,SECOND不用再和A[I]比较 如果A[I]>SECOND,则再交换; // 例子如 5 10 8 9 11 15 比较次数为0.5N+0.5N+0.5N=1.5N 2.11寻找最近点对 分治思想的利用,O(N*LOGN) 扩展问题1 类似桶排序,关键是相邻两个数的意义 简单方法是排序,然后计算相邻数的差值,然后再求MAX,O(N*LOGN) 书中的方法是桶排序或者说是抽屉原理的使用,然后在两个桶间的最大值 与最小值得差求MAX,空间O(N)时间O(N) 扩展问题2 参考: http://blog.csdn.net/hackbuteer1/article/details/7484746 两个方法 1几何思想,求凸包直径O(N*LOGN) 2凸包边与其最远点距离的扫描O(N) 2.12 快速寻找满足条件的两个数 扩展问题// by zjerry 先放一放,找到解决3的方法就解决了1,2,关键理解NP,NPC问题 1 2 3 2.13 子数组的最大乘积 思路 不许用乘除法,计算N-1个乘积最大的一组 方法1 空间换时间,O(N),利用两个数组来进行"-1"的操作 方法2 判断N个数的乘积P的正负性,来推理出应该"-1"减去什么样的数,O(N) 2.14 求数组的子数组之和的最大值 这里的子数组指连续子数组 思路DP,方法O(N),判断当前值+之前的和,是否小于0,小于0,则将和归为0,重新开始寻找子数组的最大值 扩展1 分为两个子问题 扩展2 返回子数组位置,注意算法中何时更改了和值,则上一个数就为上一轮的END,当前数为新一轮的BEGIN;在最大值比较时,保存相应的BEGIN和END 2.15 子数组之和的最大值(二维) 扩展// by zjerry 基本思路就是向低维转化,有一点注意,游泳圈那种,如何进行上下,左右都像一维一样的分两种情况讨论(有可能最大值在上下左右交结的位置) 1 2 3 4 2.16 求数组中最长递增子序列 方法一:用一个数组保存到当前位时的最大子序列个数,DP思想求解,O(N^2) 方法二:用一个MAX数组保存长度为I的递增子序列最大元素的最小值,例如1 -1 2 -3 4 -5 6 -7 中长度为2的MAX[2]=2, 遍历这个MAX值来进行判断子序列个数是否要加1, 利用贪心思想,每遍历的一个数如果大于则追加,同时更新这个新子序列的MAX值, 复杂度仍为O(N^2) 方法三:将遍历MAX数组改进为二分查找,从而使内层循环变为LOGN,总的复杂度降为O(N*LOGN) 2.17 数组循环移位 三次REVERSE 时间复杂度O(N) 2.18 数组分割 // by zjerry 没完全理解,要结合DP,背包等内容看 扩展问题 针对负数,可以先将所有数+最小负数的绝对值,使所有数变为正数,然后再解(因为分割只是为了分成差值小的两组数) 2.19 区间重合判断 解法一是将所给的区间向源区间上投影,标记未被覆盖的区间,时间复杂度是O(N^2)(外层循环是N个所给区间O(N),内层循环是每次更新未被覆盖的区间数组O(N)) 解法二是容易想到的办法, 先按区间左边值排序O(NLOGN) 合并区间O(N) 二分查找源区间在合并后的范围O(LOGN) 单次查找就是第三部O(LOGN) 扩展问题 参考:http://blog.csdn.net/linyunzju/article/details/7737060 // by zjerry 2.20 程序理解和时间分析 问题 理解这个程序就是从输出的地方往前追溯就可以。这个程序输出的条件是hit==2&&(hit1+1==hit2),再往前追溯看hit,hit1,hit2三个变量分别代表什么,hit表示满足i%r[j]!=0的条件的次数,hit==2表示这个条件只能被满足两次,也就是说对于一个i,在rg数组的30个数中,这个i能被其它28个数整除,而不能被其中两个数整除。而hit1表示第一个不能整除i的数的下标,hit2表示第二个不能整除i的下标,这两个下标被要求相差只有1。于是,程序所要寻找的是这样的数:这个数i不能被2-31这30个数中的两个相邻的数整除,但能被其它28个数整除。所以,这个i肯定是其它28个数的最小公倍数的整数倍。然而i不能被两个相邻的数整除,所以必然是分解质因子后要么i的质因子中不包括这两个数的质因子,要么是i的质因子的次数小于这两个数中相同质因子的次数。 那么,只需要给2-31这30个数分解质因数,找一下是否有这样的相邻的两个数,要么它们的质因子中有其它数没有的质因子,要么对于相同的一个质因子,这两个数包含这个质因子的次数高于其它所有次数。 16、17、19、23、25、27、29、31这几个数包含次数最高的质因子。而相邻的则只有16,17。所以,这段程序所要求的数i就是,它不能被16、17整除,但能被30个数中的其它28个数整除,最小的i就是其它28个数的最小公倍数,从上表中知道,这个最小的i是:23*33*52*7*11*13*19*23*29*31,用计算器计算出这个数是:2123581660200。可以把上述程序中的for循环中的i初始化成这个数来检验。 2.21 只考加法的面试题 参考:http://blog.csdn.net/yutianzuijin/article/details/10300067// by zjerry 这篇稍好理解 http://www.cnblogs.com/peteryj/archive/2009/07/08/1944889.html http://blog.csdn.net/lyso1/article/details/5399146 http://www.cnblogs.com/flyinghearts/archive/2011/03/27/1997285.html 3.1 字符串移位包含的问题 方法1是将源串进行循环移位,然后按题目直接意思去判断是否包含,循环移位需要O(N*N),匹配至少要O(M+N) 方法2是发现循环移位的终态可以用两个源串的拼接来作新的比较串,转化为字符串模式匹配,但是增加了空间复杂度 扩展: 不需要申请额外空间:可以改进模式匹配的长度为2*length(s1),而步进的规律也改为(i+1)%length(s1),最终用KMP等算法改进为O(M+N) 3.2 电话号码对应英语单词 直接看问题1和2,发现,都是要先做映射然后,匹配字母组合是否是真的单词, 结果看了书中解法发现,书中写解法的人似乎没读懂题目,或者没读完全 问题1我认为简单描述成:根据一个号码,如果尽可能快地从其字母组合中找出有意义的单词 问题2我认为可以描述成:问题1是否有答案....(实在看不出还能怎么断句了....) 在书中解法的基础上(遍历或递归得到电话中数字按下后字母的所有组合),在每个字母组合上都查一遍单词字典表,输出有意义的单词,这当然不是尽可能快的方法了,查询一个数字对应的组合有O(3^N)(// 除了7,9对应是4位),查询字典有O(LOGMAX),最终是每次查询O(3^N*LOGMAX) 解决方法是: 将单词字典表每个单词都先转化为数字映射O(N)//N是单词字母数量,每次查询O(LOGMAX) 3.3 计算字符串的相似度 递归求相似度,递归中会有重复计算,需要保存记录 参考:http://www.cnblogs.com/yujunyong/articles/2004724.html 动态规划自底向上,或者备忘录自顶向下 3.4 从无头单链表中删除节点 节点删除需要知道前驱,想在O(1) 的情况下删除就只能删除当前节点的数据,而实际上删除下一结点的空间,删除前把下一节点的数据复制过来 扩展问题 一次遍历,逆置单链表 数组中逆置的原理是将数据不断交换过来(因为在序存储空间分配后是固定的) 链表中逆置则可以不交换数据,只修改链接的结构来实现物理上的逆置,具体实现需要借助三个指针,不停将P2指向P1 3.5 最短摘要的生成 我的理解就是滑动窗口,逐渐缩小每个摘要段落区间,从而求得最短摘要,时间复杂度可以优化到O(M*LOGN*N)// by zjerry 应该还能继续优化,我想的太简单了? 扩展问题: LCS相似检测 3.6 编程判断两个链表是否相交 判断最后一个节点是否相同 扩展问题 1,如果链表有环,两种情况,交点在环上,交点在尾巴上,两种情况的判断方法都是: 先利用快慢法找到一个链表的碰撞点,在环内,然后遍历另外一个链表,遍历过程中判断是否与碰撞点相同 2.求出交点: 无环链表利用求两链表长度差,然后先后走 有环链表1交点在环上,各自求出环的入口,2交点在尾巴上,与无环链表一样求链表长度差 3.7 队列中取最大值操作问题 问题基于:栈中取最值问题 3.8 求二叉树中节点的最大距离 max(maxleft,maxright,height_left+heigth_right);//左孩子的最大距离,右孩子的最大距离,左子树的高度+右子树的高度 3.9 重建二叉树 3.10 分层遍历二叉树 BFS利用队列遍历 扩展问题 1.BFS遍历(先访问右孩子)数据入栈,一层完结时作层标记入栈,全部完成再出栈 2.BFS遍历(先访问左孩子)数据入栈,一层完结时作层标记入栈,全部完成再出栈 3.11 程序改错 二分查找 4.1金刚坐飞机问题 问题2的解法未完全理解和掌握 扩展1 每个乘客包括金刚都是随机选位置,所以答案依然是1/N 扩展2 分情况讨论 i不可能是1,因为金刚先入座 i=2时, 只要金刚不选中第i个人的座位,假设是x,所以概率是 n-1/n i=3时,金刚选中第2人座位,第2人不选x;另外一种情形是金刚未选第2人未选x,第2人选自己的,然后加法原理 i=4时,类似上述 4.2瓷砖覆盖地板 扩展1 斐波那切数列 推广1 DP问题暂时没彻底弄明白 推广2 1.11 NIM(1)一排石头的游戏 注明A先取,B后取 扩展 1.N=3K+1(K=0,1,2,……)时先取者A输,其余情况N=3K,N=3K+2时先取者A赢 http://blog.csdn.net/dreamvyps/article/details/22264903 http://hi.baidu.com/hehehehello/item/4115b9151a2f29fd756a8487 2.N%(K+1)=0时,玩家B有必胜策略,N%(K+1)!=0时,玩家A有必胜策略。 当d=0时,无论A取多少个石头,B取相应的石头,使得A和B一起取(K+1)个石头,这样最后取到石头的肯定是玩家B。 1.12 NIM(2)"拈"游戏分析 注明A先分配,B先取,A后取 http://www.cnblogs.com/yintingru/archive/2012/08/27/2658483.html 取石头的过程与上一次他人取的数目始终保持一个"安全的状态",即可以确保完胜,这里安全的状态是XOR为0 扩展问题 1如果取光者输,当N=2,B先取,A必输,N>2,A必胜,只要确保堆数为奇,个数也为奇即可,N为奇数,则分配(1,1,1,...),N为偶数,则分配(N/2,N/2) 2若是先取光者胜,则A保持安全状态为每次取走和为K+1(与1.11扩展问题类似),且每堆的个数为>=2(关键是取到只剩下K+1,K+2...K+K-1堆时的抉择问题上) // by zjerry 未仔细认证,先到这里 1.13 NIM(3)两堆石头的游戏 注意A先取, B后取,AB可以两堆中各拿相等数量的石头或从一堆中取走任意 http://www.cnblogs.com/flyinghearts/archive/2011/03/22/1991972.html 扩展 1.A先取始终构造不安全局面给B,即可确保必胜(前提是初始状态为安全) 2.NIM(4) http://blog.sina.com.cn/s/blog_7689f89d01017u6y.html http://episte.math.ntu.edu.tw/articles/mm/mm_03_2_02/index.html // by zjerry 台大数学系网站,希望两岸统一,网站可以持久访问
1,v模2的值是1则++;
2,v右移(相当于除2),然后与0x1与运算(与上一解法思路一致);
3,v与v-1进行与运算,将消去最右边的1,循环进行下去,时间复杂度只有O(n) n=1的个数;
4,查表的复杂度为O(1),不过要考虑建表的时间
针对该问题,有规律进行快速建表:
5,根据奇偶性来分析,对于任意一个正整数n
1.如果它是偶数,那么n的二进制中1的个数与n/2中1的个数是相同的,比如4和2的二进制中都有一个1,6和3的二进制中都有两个1。为啥?因为n是由n/2左移一位而来,而移位并不会增加1的个数。
2.如果n是奇数,那么n的二进制中1的个数是n/2中1的个数+1,比如7的二进制中有三个1,7/2 = 3的二进制中有两个1。为啥?因为当n是奇数时,n相当于n/2左移一位再加1。
http://blog.csdn.net/justpub/article/details/2292823
http://www.cnblogs.com/graphics/archive/2010/06/21/1752421.html
http://en.wikipedia.org/wiki/Hamming_weight
1: int Count(unsigned x) {
2: unsigned n;
3:
4: n = (x >> 1) & 033333333333;
5: x = x - n;
6: n = (n >> 1) & 033333333333;
7: x = x - n;
8: x = (x + (x >> 3)) & 030707070707;
9: x = modu(x, 63);
10: return x;
11: } int BitCount5(unsigned int n)
{
unsigned int tmp = n - ((n >>1) &033333333333) - ((n >>2) &011111111111);
return ((tmp + (tmp >>3)) &030707070707) %63;
}
问题二是给定两个整数A和B,问A和B有多少位是不同的。
这个问题其实就是数1问题多了一个步骤,只要先算出A和B的异或结果,然后求这个值中1的个数就行了。
解法:
求质因数5的个数
其中有公式N!阶乘中含有K的质因数个数 Z=[N/K]+[N/K^2]+[N/K^3]+...
2.求N!二进制最低位1的位置
解法:同上
求质因数2的个数+1(末尾有多少个0再+1位就是最低位1的位置)
同样使用公式Z
解法2:公式Z转化二进制后可以换算=N减去N的二进制中1的个数
http://www.cnblogs.com/sooner/archive/2013/04/02/2996589.html
解法一:先排序,然后N/2的项即为所求
解法二:每次去除两个不同ID项,最后得到的即为所求,O(N)
缺点是无法同时得到该项次数
int find(int ID[], int n)
{
int nTimes = 0, i, candidate;
for(i = 0; i < n;i++)
{
if(nTimes == 0)
{
candidate = ID[i];
nTimes = 1;
}
else
{
if(candidate == ID[i])
{
nTimes++;
}
else
{
nTimes--;
}
}
}
return candidate;
}
解法三:HASH统计,空间复杂度O(N),解法二是O(1)
已知有M个发帖量在1/(M+1)个以上的ID
例子:
扩展题,题目如下:
随着Tango的发展,管理员发现,“超级水王”没有了。统计结果表明,有3个发帖很多的ID,他们的发帖数目都超过了帖子总数目N的1/4。你能从发帖ID列表中快速找出他们的ID吗?
同时删除4个不同的ID后,剩余数据中3个多数id仍然是多数ID。
上题只需要一个结果,而现在需要3个结果,上题用到的nTimes,也应改为3个计数器。现在我们需要3个变量来记录当前遍历过的3个不同的ID,而nTimes的3个元素分别对应当前遍历过的3个ID出现的个数。如果遍历中有某个ID不同于这3个当前ID,我们就判断当前3个ID是否有某个的nTimes为0,如果有,那这个新遍历的ID就取而代之,并赋1为它的遍历数(即nTimes减1),如果当前3个ID的nTimes皆不为0,则3个ID的nTimes皆减去1。#include
2.4 1的数目
问题二
unsigned long Sumls(unsigned long n)
{
unsigned long iCount=0;
unsigned long iFactor=1;
unsigned long iLowerNum=0;
unsigned long iCurrNum=0;
unsigned long iHigherNum=0;
while(n/iFactor!=0)
{
iLowerNum=n-(n/iFactor)*iFactor;
iCurrNum=(n/iFactor)%10;
iHigherNum=n/(iFactor*10);
switch(iCurrNum)
{
case 0:
iCount+=iHigherNum*iFactor;
break;
case 1:
iCount+=iHigherNum*iFactor+iLowerNum+1;
break;
default:
iCount+=(iHigherNum+1)*iFactor;
break;
}
iFactor*=10;
}
return iCount;
}
总结规律,然后估算出上界N=10^11,再从上界开始调用上述算法,求得答案
部分载入的算法可以考虑每次将最大的K个数维持一个小根堆 O(N*logK)
数的范围已知的情况下可以考虑计数排序,桶排序
排序的思想,得到所有文档中最相关的K个。 最好的情况是这K个文档在所有机器中平均
分布,这时每台机器只要K' = K / n (n为所有机器总数);最坏情况,所有最相关的K
个文档只出现在其中的某一台机器上,这时K'需近似等于K了。我觉得比较好的做法可以
在每台机器上维护一个堆,然后对堆顶元素实行归并排序。
设这K个就是,然后根据问题四的解法获得K',分别和这K个比较,可以用堆进行比较,从
而获得qj最相关的K个文档。由于最开始的K个文档极有可能是最终的K个文档,所以K'和K
比较的次数可能并不多。
辗转相减法
奇偶判断的辗转相减法
简单证明:因为
 ,所以
,所以

方法一:给定N,令M从2开始,枚举M的值直到遇到一个M使得N*M的十进制表示中只有1和0.
方法二:求出10的次方序列模N的余数序列并找出循环节。然后搜索这个余数序列,搜索的目的就是要在这个余数序列中找到一些数出来让它们的和是N的倍数。例如N=13,这个序列就是1,10,9,12,3,4然后不断循环。很明显有1+12=13,而1是10的0次方,12是10的3次方,所以这个数就是1000+1=1001,M就是1001/13=77。
方法三:因为N*M的取值就是1,10,11,100,101,110,111,......所以直接在这个空间搜索,这是对方法一的改进。搜索这个序列直到找到一个能被N整除的数,它就是N*M,然后可计算出M。例如N=3时,搜索树如下:
上图中括号内表示模3的余数。括号外表示被搜索的数。左子树表示0,右子树表示1.上图中搜索到第二层(根是第0层)时遇到111,它模3余数为0.所以N*M=111, M=111/3=37。
方法四:对方法三的改进。将方法三的搜索空间按模N余数分类,使得搜索时间和空间都由原来的指数级降到了O(N)。改进的原理:假设当前正在搜索由0,1组成的K位十进制数,这样的K位十进制数共有2^k个。假设其中有两个数X、Y,它们模N同余,那么在搜索由0、1组成的K+1位十进制数时,X和Y会被扩展出四个数:10X, 10X+1, 10Y, 10Y+1。因为X和Y同余(同余完全可以看作相等),所以10X与10Y同余,10X+1与10Y+1同余。也就是说由Y扩展出来的子树和由X扩展产生出来的子树产生完全相同的余数,如果X比Y小,那么Y肯定不是满足要求的最小的数,所以Y这棵子树可以被剪掉。这样,2^K个数按照模N余数分类,每类中只保留最小的那个数以供扩展。原来在这一层需要搜索2^K个数,现在只需要搜索O(N)个数。例如,当N=9时,第0层是1(1),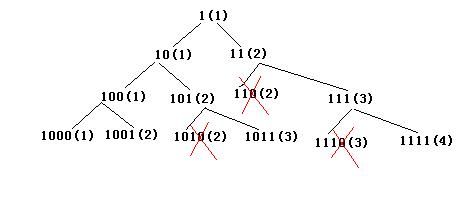
如上图所示,第2层的110,第三层的1010、1110都因为同一层有和它同余且更小的数而被剪掉。如果按照方法三搜索,第三层本来应该有8个结点,但现在只有4个结点。
4.3买票找零
http://wenku.baidu.com/link?url=HbLXTFZks-5BM6oA8GOcFWLRAcPSWtUC55OgF35-XRJfVNNCYpYFucTULwGG1OyHZgWCIdBbOdiowdeOSDYQ-2rtQCRWtH-Ts8yPjwRytZW
http://wenku.baidu.com/link?url=2xnIFfvaVYedENAqdWn-BhaqNwkoZJhZczE-15IdXG5YGL-3BFGrj-JZQLy8Tv2F_PZhBVt440r--2hSDEJa8SqS2bgLiV6yfHxWHApa9Ba