【论文阅读】Pix2Pix:Image-to-Image Translation with Conditional Adversarial Networks
Pix2Pix:Image-to-Image Translation with Conditional Adversarial Networks
- Related work
- 图像建模的结构化损失
- Conditional GANs
- 对抗框架
- CGAN
- GAN
- CGAN
- 损失函数
- 网络结构
- 生成器网络结构
- 判别器网络结构
- 实验结果
- 总结
- 代码实现
- 论文地址
- 数据集下载地址

图像到图像翻译(image-to-image translation)是GAN很重要的一个应用方向,什么叫图像到图像翻译呢?其实就是基于一张输入图像得到想要的输出图像的过程,可以看做是图像和图像之间的一种映射(mapping),我们常见的图像修复、超分辨率其实都是图像到图像翻译的例子。这篇论文列举了一些图像到图像翻译的例子如图Figure1所示,包括从标签到图像的生成、图像边缘到图像的生成等过程。
图像处理的很多问题都是将一张输入的图片转变为一张对应的输出图片,比如灰度图、梯度图、彩色图之间的转换等。通常每一种问题都使用特定的算法(如:使用CNN来解决图像转换问题时,要根据每个问题设定一个特定的loss function 来让CNN去优化,而一般的方法都是训练CNN去缩小输入跟输出的欧氏距离,但这样通常会得到比较模糊的输出)。这些方法的本质其实都是从像素到像素的映射。于是论文在GAN的基础上提出一个通用的方法:pix2pix 来解决这一类问题。通过pix2pix来完成成对的图像转换(Labels to Street Scene, Aerial to Map,Day to Night等),可以得到比较清晰的结果。
pix2pix基于GAN实现图像翻译,更准确地讲是基于cGAN(conditional GAN,也叫条件GAN),因为cGAN可以通过添加条件信息来指导图像生成,因此在图像翻译中就可以将输入图像作为条件,学习从输入图像到输出图像之间的映射,从而得到指定的输出图像。而其他基于GAN来做图像翻译的,因为GAN算法的生成器是基于一个随机噪声生成图像,难以控制输出,因此基本上都是通过其他约束条件来指导图像生成,而不是利用cGAN,这是pix2pix和其他基于GAN做图像翻译的差异。
Related work
图像建模的结构化损失
图像到图像的转换问题通常被表示为按像素分类或回归。从每个输出像素在条件上被认为独立于给定输入图像的所有其他像素来看,这些公式将输出空间视为“非结构化”。相反,有条件的GAN学习到了结构性损失。
Conditional GANs
本文的方法在生成器和判别器的几种结构选择上也不同于先前的工作。与过去的工作不同,对于生成器,本文使用基于“ U-Net”的体系结构,对于判别器,我们使用卷积的“ PatchGAN”分类器,该分类器仅在图像补丁范围内惩罚结构。本文还研究了不同大小的patch size的影响。
对抗框架
Pix2Pix是基于GAN框架,那么首先先定义输入输出。普通的GAN接收的G部分的输入是随机向量,输出是图像;D部分接收的输入是图像(生成的或是真实的),输出是对或者错。这样G和D联手就能输出真实的图像。
对于图像翻译任务来说,pix2pix对传统的GAN做了个小改动,它不再输入随机噪声,而是输入用户给的图片。它的G输入显然应该是一张图 x x x,输出当然也是一张图 y y y。但是D的输入却应该发生一些变化,因为除了要生成真实图像之外,还要保证生成的图像和输入图像是匹配的。于是D的输入就做了一些变动,如下图所示:
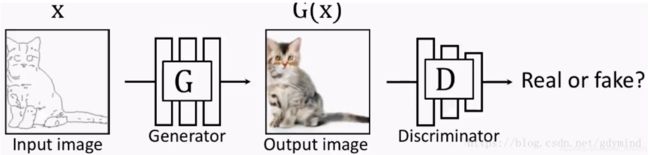


训练大致过程如上图所示。图片 x x x作为此CGAN的条件,需要输入到G和D中。G的输入是 x , z {x,z} x,z(其中, x x x是需要转换的图片, z z z是随机噪声),输出是生成的图片 G ( x , z ) G(x,z) G(x,z)。D则需要分辨出 x , G ( x , z ) {x,G(x,z)} x,G(x,z)和 x , y {x,y} x,y。
首先输入图像用y表示,输入图像的边缘图像用x表示,pix2pix在训练时需要成对的图像(x和y)。x作为生成器G的输入(随机噪声z在图中并未画出,去掉z不会对生成效果有太大影响,但假如将x和z合并在一起作为G的输入,可以得到更多样的输出)得到生成图像G(x),然后将G(x)和x基于通道维度合并在一起,最后作为判别器D的输入得到预测概率值,该预测概率值表示输入是否是一对真实图像,概率值越接近1表示判别器D越肯定输入是一对真实图像。另外真实图像y和x也基于通道维度合并在一起,作为判别器D的输入得到概率预测值。因此判别器D的训练目标就是在输入不是一对真实图像(x和G(x))时输出小的概率值(比如最小是0),在输入是一对真实图像(x和y)时输出大的概率值(比如最大是1)。生成器G的训练目标就是使得生成的G(x)和x作为判别器D的输入时,判别器D输出的概率值尽可能大,这样就相当于成功欺骗了判别器D。
CGAN
GAN
模型G和D同时训练:固定判别模型D,调整 G 的参数使得 l o g ( 1 − D ( G ( z ) ) log(1−D(G(z)) log(1−D(G(z))的期望最小化;固定生成模型G,调整D的参数使得 l o g D ( X ) + l o g ( 1 − D ( G ( z ) ) ) logD(X)+log(1−D(G(z))) logD(X)+log(1−D(G(z)))的期望最大化:

CGAN
条件生成式对抗网络(CGAN)是对原始GAN的一个扩展,生成器和判别器都增加额外信息 y为条件, y 可以使任意信息,例如类别信息,或者其他模态的数据。通过将额外信息 y 输送给判别模型和生成模型,作为输入层的一部分,从而实现条件GAN。在生成模型中,先验输入噪声 p(z) 和条件信息 y 联合组成了联合隐层表征。
![]()
损失函数
对抗损失:

为了测试条件判别器的重要性,本文还比较了一个无条件的变体,其中判别器的输入不包括 x x x:

L1损失:
对于图像翻译任务而言,G的输入和输出之间其实共享了很多信息,比如图像上色任务,输入和输出之间就共享了边信息。因而为了保证输入图像和输出图像之间的相似度。将GAN的目标函数和传统的loss结合,可以带来更好的效果。所以论文增加了一个L1 loss交给生成器G去最小化:

总的损失函数:

文中对于不同的loss的效果做了一个对比,可以看到L1 + cGAN的效果相对于只用L1或者cGAN都是比较好的:
网络结构
生成器网络结构

图像到图像转换问题的定义特征是它们将高分辨率输入网格映射到高分辨率输出网格。另外,虽然输入和输出的表面外观不同,但是两者都是相同基础结构的绘制。因此,输入中的结构与输出中的结构大致对齐。 本文围绕这些考虑因素设计生成器体系结构。
对于该领域中的问题的许多先前解决方案已经使用了编码器-解码器网络。 在这样的网络中,输入将通过一系列下采样层,直到bottleneck为止,然后再通过一系列上采样层进行还原。这样的网络要求所有信息流都经过包括瓶颈在内的所有层。 对于许多图像翻译问题,在输入和输出之间共享大量低级信息,因此希望将这些信息直接穿梭在网络上。例如,在图像着色的情况下,输入和输出共享突出边缘的位置。
本文按照“ U-Net”的一般形状添加跳跃连接。具体来说,我们在第i层和第n-i层之间添加跳过连接,其中n是总层数。每个跳过连接仅将第i层的所有通道与第n-i层的所有通道连接在一起。

U-Net是德国Freiburg大学模式识别和图像处理组提出的一种全卷积结构。和常见的先降采样到低维度,再升采样到原始分辨率的编解码(Encoder-Decoder)结构的网络相比,U-Net的区别是加入skip-connection,对应的feature maps和decode之后的同样大小的feature maps按通道拼(concatenate)一起,用来保留不同分辨率下像素级的细节信息。U-Net对提升细节的效果非常明显,下面是文中给出的一个效果对比,可以看到不同尺度的信息都得到了很好的保留:

判别器网络结构
众所周知,L2损失和L1损失在图像生成问题上产生模糊的结果。尽管这些损失不能捕获高频特征,但在许多情况下,它们仍然可以准确地捕获低频特征。对于这种情况下的问题,我们不需要全新的框架即可在低频下增强正确性。 L1已经可以了。
利用马尔科夫性的判别器(PatchGAN)
pix2pix采用的一个想法是,用重建来解决低频成分,用GAN来解决高频成分。一方面,使用传统的L1 loss来让生成的图片跟训练的图片尽量相似,用GAN来构建高频部分的细节。
另一方面,使用PatchGAN来判别是否是生成的图片。PatchGAN的思想是,既然GAN只用于构建高频信息,那么就不需要将整张图片输入到判别器中,让判别器对图像的每个大小为N x N的patch做真假判别就可以了。因为不同的patch之间可以认为是相互独立的。pix2pix对一张图片切割成不同的N x N大小的patch,判别器对每一个patch做真假判别,将一张图片所有patch的结果取平均作为最终的判别器输出。
具体实现,作者使用的是一个NxN输入的全卷积小网络,最后一层每个像素过sigmoid输出为真的概率,然后用BCEloss计算得到最终loss。这样做的好处是因为输入的维度大大降低,所以参数量少,运算速度也比直接输入一整张图快,并且可以计算任意大小的图。论文对比了不同大小patch的结果,对于256x256的输入,patch大小在70x70的时候,从视觉上看结果就和直接把整张图片作为判别器输入没有多大区别了: 
实验结果
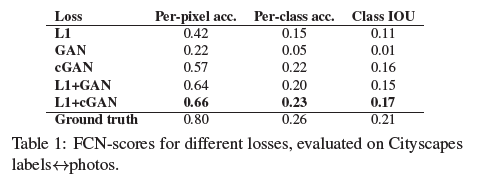
Table1是关于不同损失函数的组成效果对比, 这里采用的是基于分割标签得到图像的任务。评价时候采用语义分割算法FCN对生成器得到的合成图像做语义分割得到分割图,假如合成图像足够真实,那么分割结果也会更接近真实图像的分割结果,分割结果的评价主要采用语义分割中常用的基于像素点的准确率和IOU等。

Table2是关于不同生成器的效果,主要是encoder-decoder和U-Net的对比。

Table3是关于判别器PatchGAN采用不同大小N的实验结果,其中1∗1111∗1表示以像素点为单位判断真假,显然这样的判断缺少足够的信息,因此效果不好;286∗286286286286∗286表示常规的以图像为单位判断真假,这是比较常规的做法,从实验来看效果也一般。中间2行是介于前两者之间的PatchGAN的效果,可以看到基于区域来判断真假效果较好。
总结
cGAN:输入为图像而不是随机向量
U-Net:使用skip-connection来共享更多的信息
Pair:输入到D来保证映射
Patch-D:来降低计算量提升效果
L1损失函数:保证输入和输出之间的一致性。
优点:pix2pix巧妙的利用了GAN的框架来为“Image-to-Image translation”的一类问题提供了通用框架。利用U-Net提升细节,并且利用PatchGAN来处理图像的高频部分。
缺点:训练需要大量的成对图片,比如白天转黑夜,则需要大量的同一个地方的白天和黑夜的照片。
代码实现
Tensorflow代码实现
Tensorflow代码实现(轻量级)
Pytorch代码实现
论文地址
Image-to-Image Translation with Conditional Adversarial Networks
数据集下载地址
数据集