一、Flink中的window
1,window简述
window 是一种切割无限数据为有限块进行处理的手段。Window 是无限数据流处理的核心,Window 将一个无限的 stream 拆分成有限大小的”buckets”桶,我们可以在这些桶上做计算操作。
2,window类型
window可分为CountWindow和TimeWindow两类:CountWindow:按照指定的数据条数生成一个 Window,与时间无关;TimeWindow:按照时间生成 Window。
a)滚动窗口
将数据依据固定的窗口长度对数据进行切片。特点:时间对齐,窗口长度固定,没有重叠。
适用场景:适合做 BI 统计等(做每个时间段的聚合计算)。
b)滑动窗口
滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成。特点:时间对齐,窗口长度固定,可以有重叠。
适用场景:对最近一个时间段内的统计(求某接口最近 5min 的失败率来决定是否要报警)。
c)会话窗口
由一系列事件组合一个指定时间长度的 timeout 间隙组成,类似于 web 应用的session,也就是一段时间没有接收到新数据就会生成新的窗口。特点:时间无对齐。
session 窗口分配器通过 session 活动来对元素进行分组,session 窗口跟滚动窗口和滑动窗口相比,不会有重叠和固定的开始时间和结束时间的情况,相反,当它在一个固定的时间周期内不再收到元素,即非活动间隔产生,那个这个窗口就会关闭。一个 session 窗口通过一个 session 间隔来配置,这个 session 间隔定义了非活跃周期的长度,当这个非活跃周期产生,那么当前的 session 将关闭并且后续的元素将被分配到新的 session 窗口中去。
3,window API
a)timeWindow
TimeWindow 是将指定时间范围内的所有数据组成一个 window,一次对一个 window 里面的所有数据进行计算。
①滚动窗口
Flink 默认的时间窗口根据 Processing Time 进行窗口的划分,将 Flink 获取到的数据根据进入 Flink 的时间划分到不同的窗口中。
val result:DataStream[Item] = mapDStream.keyBy(0) //默认的时间窗口根据 Processing Time .timeWindow(Time.seconds(5)) .min(2) //获取processing time滚动5s内的最小值
val input: DataStream[T] = ... / / 滚动事件时间窗口( tumbling event-time windows ) input .keyBy() .window(TumblingEventTimeWindows.of(Time.seconds(5))) . ( ) // 滚动处理时间窗口(tumbling processing-time windows) input .keyBy( ) .window(TumblingProcessingTimeWindows.of(Time.seconds(5))) . ( ) // 每日偏移8小时的滚动事件时间窗口(daily tumbling event-time windows offset by -8 hours. ) input .keyBy( ) .window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8))) . ( )
②滑动窗口
滑动窗口和滚动窗口的函数名是完全一致的,只是在传参数时需要传入两个参数,一个是 window_size,一个是 sliding_size。
val result:DataStream[Item] = mapDStream.keyBy(0) //默认的时间窗口根据 Processing Time .timeWindow(Time.seconds(15),Time.seconds(5)) .min(2) //根据processing time 每5s统计一次15s内的最小值
val input: DataStream[T] = ... // 滑动事件时间窗口 (sliding event-time windows) input .keyBy() .window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5))) . ( ) // 滑动处理时间窗口 (sliding processing-time windows) input .keyBy( ) .window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))) . ( ) // 偏移8小时的滑动处理时间窗口(sliding processing-time windows offset by -8 hours) input .keyBy( ) .window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8))) . ( )
③会话窗口
因为session看窗口没有一个固定的开始和结束,他们的评估与滑动窗口和滚动窗口不同。在内部,session操作为每一个到达的元素创建一个新的窗口,并合并间隔时间小于指定非活动间隔的窗口。为了进行合并,session窗口的操作需要指定一个合并触发器(Trigger)和一个合并窗口函数(Window Function),如:ReduceFunction或者WindowFunction(FoldFunction不能合并)。
val input: DataStream[T] = ... // 事件时间会话窗口(event-time session windows with static gap) input .keyBy() .window(EventTimeSessionWindows.withGap(Time.minutes(10))) . ( ) // 具有动态间隙的事件时间会话窗口 (event-time session windows with dynamic gap) input .keyBy( ) .window(EventTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] { override def extract(element: String): Long = { // determine and return session gap } })) . ( ) // 具有静态间隙的处理时间会话窗口(processing-time session windows with static gap) input .keyBy( ) .window(ProcessingTimeSessionWindows.withGap(Time.minutes(10))) . ( ) // 具有动态间隙的处理时间会话窗口(processing-time session windows with dynamic gap) input .keyBy( ) .window(DynamicProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] { override def extract(element: String): Long = { // determine and return session gap } })) . ( )
b)countWindow
CountWindow 根据窗口中相同 key 元素的数量来触发执行,执行时只计算元素数量达到窗口大小的 key 对应的结果。注意:CountWindow 的 window_size 指的是相同 Key 的元素的个数,不是输入的所有元素的总数。
①滚动窗口
默认的 CountWindow 是一个滚动窗口,只需要指定窗口大小即可,当元素数量达到窗口大小时,就会触发窗口的执行。
val result:DataStream[Item] = mapDStream.keyBy(0) .countWindow(5) .min(2) //统计5个元素中的item的第三个值最小的元素
②滑动窗口
滑动窗口和滚动窗口的函数名是完全一致的,只是在传参数时需要传入两个参数,一个是 window_size,一个是 sliding_size。
val result:DataStream[Item] = mapDStream.keyBy(0) .countWindow(5,2) .min(2) //每2个元素统计一次 每次统计5个元素中的item的第三个值最小的元素
c)window Function
window function 定义了要对窗口中收集的数据做的计算操作,主要可以分为两类:
增量聚合函数(incremental aggregation functions )每条数据到来就进行计算,保持一个简单的状态。典型的增量聚合函数有 ReduceFunction, AggregateFunction。
全窗口函数(full window functions)先把窗口所有数据收集起来,等到计算的时候会遍历所有数据。ProcessWindowFunction 就是一个全窗口函数。
d)其他API
trigger() — — 触发器,定义window什么时候关闭,触发计算并输出
evitor() — — 移除器,定义移出某些数据的逻辑
allowedLateness() — — 允许处理迟到的数据
sideOutputLateData() — — 将迟到的数据放入侧输出
getSideOutput() — — 获取侧输出流
二、时间语义
1,时间语义
在flink的流式处理中,会涉及到时间的不同概念:
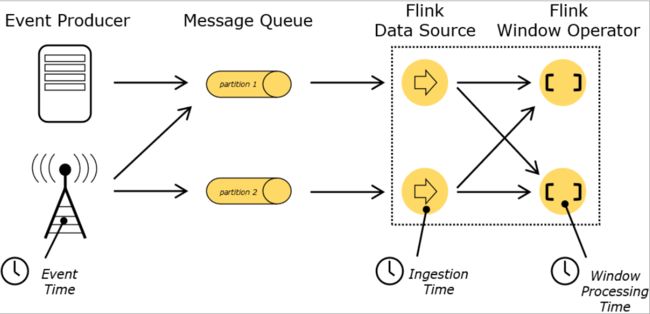
Event Time:是事件创建的时间。 它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink 通过时间戳分配器访问事件时间戳。
Ingestion Time:是数据进入 Flink 的时间。
Processing Time:是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是 Processing Time。
2,EventTime的引入
在 Flink 的流式处理中,绝大部分的业务都会使用 eventTime,一般只在eventTime 无法使用时,才会被迫使用 ProcessingTime 或者 IngestionTime。
val env = StreamExecutionEnvironment.getExecutionEnvironment //从调用时刻开始给 env 创建的每一个 stream 追加时间特征 env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
三、Watermark
一旦出现乱序,如果只根据 eventTime 决定 window 的运行,我们不能明确数据是否全部到位,但又不能无限期的等下去,此时必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了,这个特别的机制,就是Watermark。
Watermark 是一种衡量 Event Time 进展的机制。
Watermark 是用于处理乱序事件的 ,而正确的处理乱序事件,通常用 Watermark 机制结合 window 来实现。
数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据,都已经到达了,因此,window 的执行也是由 Watermark 触发的。
Watermark可以理解成一个延迟触发机制,我们可以设置 Watermark的延时时长t,每次系统会校验已经到达的数据中最大的 maxEventTime,然后认定 eventTime小于 maxEventTime - t 的所有数据都已经到达,如果有窗口的停止时间等于 maxEventTime – t,那么这个窗口被触发执行。
乱序流的 Watermarker 如下图所示:(Watermark 设置为 2)

上图中,我们设置的允许最大延迟到达时间为 2s,所以时间戳为 7s 的事件对应的 Watermark 是 5s,时间戳为 12s 的事件的 Watermark 是 10s,如果我们的窗口 1是 1s~5s,窗口 2 是 6s~10s,那么时间戳为 7s 的事件到达时的 Watermarker 恰好触发窗口 1,时间戳为 12s 的事件到达时的 Watermark 恰好触发窗口 2。
当 Flink 接收到数据时,会按照一定的规则去生成 Watermark,这条 Watermark就等于当前所有到达数据中的 maxEventTime - 延迟时长,也就是说,Watermark 是由数据携带的,一旦数据携带的 Watermark 比当前未触发的窗口的停止时间要晚,那么就会触发相应窗口的执行。由于 Watermark 是由数据携带的,因此,如果运行过程中无法获取新的数据,那么没有被触发的窗口将永远都不被触发。
1,watermark的引入
BoundedOutOfOrdernessTimestampExtractor的使用
val env = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1) env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //设置时间为事件时间,默认采用process //采用socketTextStream输入 val socketDStream = env.socketTextStream("localhost",8888) val mapDStream = socketDStream.map { item => val arr = item.split(",") Item(arr(0), arr(1).toLong, arr(2).toDouble) } val waterDStream = mapDStream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[Item](Time.seconds(1)) { //1s为结束延时时间 override def extractTimestamp(element: Item): Long = element.timestap * 1000L //抽取timestap作为时间标准 }) val resultDStream = waterDStream.keyBy(_.id) .timeWindow(Time.seconds(6), Time.seconds(3)) .min(2) //当currentEverntTime - 1s(late延时) > window_end_time触发 resultDStream.print("bound min") env.execute("executor")
此时输入:
item_1,1596419969,33.1 item_1,1596419970,32.1 item_1,1596419971,31.1 //触发上一个窗口的的window_end操作,1596419971-1 = 1596419970(window_end_time) [1596419964,1596419970) 此时输出的结果为33.1 item_1,1596419972,30.1 item_1,1596419973,31.1 item_1,1596419974,32.1 //触发上一个窗口的的window_end操作,1596419974-1 = 1596419973(window_end_time) [1596419967,1596419973) 此时输出的结果为30.1 item_1,1596419977,29.1 //触发上一个窗口的的window_end操作,1596419977-1 = 1596419976(window_end_time) [1596419970,1596419976) 此时输出的结果为30.1
源码解读:
@Override public CollectionassignWindows(Object element, long timestamp, WindowAssignerContext context) { timestamp = context.getCurrentProcessingTime(); List windows = new ArrayList<>((int) (size / slide)); long lastStart = TimeWindow.getWindowStartWithOffset(timestamp, offset, slide); //滑动步长为3s,当时间戳为1596419969时lastStart=1596419967 for (long start = lastStart; start > timestamp - size; start -= slide) { //此时可以得到窗口64~70,67~73 windows.add(new TimeWindow(start, start + size)); } return windows; } public static long getWindowStartWithOffset(long timestamp, long offset, long windowSize) { //时间戳 偏移量(时区)默认为0 滑动步长 return timestamp - (timestamp - offset + windowSize) % windowSize; }
2,AssignerWithPeriodicWatermarks
object PeriodicInsertWatermarks { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) env.setParallelism(1) val stream = env .socketTextStream("hadoop102", 7777) .map { item => val arr: Array[String] = item.split(",") Item(arr(0).trim, arr(1).trim.toLong, arr(2).trim.toDouble) }.assignTimestampsAndWatermarks(new MyAssigner) .keyBy(_.id) .timeWindow(Time.seconds(5)) //滚动窗口 .min(2) stream.print() env.execute() } // `BoundedOutOfOrdernessTimestampExtractor`的底层实现 class MyAssigner extends AssignerWithPeriodicWatermarks[Item] { val bound = 1000L // 最大延迟时间 var maxTs = Long.MinValue + bound // 观察到的最大时间戳 // 每来一条元素就要调用一次 override def extractTimestamp(t: Item, l: Long): Long = { maxTs = maxTs.max(t.timestamp * 1000) t.timestamp * 1000 } // 产生水位线的函数,默认200ms调用一次 override def getCurrentWatermark: Watermark = { val water: Long = maxTs - bound println("当前水位值为:\t" + water) // 水位线 = 观察到的最大时间戳 - 最大延迟时间 new Watermark(water) } } } case class Item(id:String,timestamp: Long,rate:Double)
3,AssignerWithPunctuatedWatermarks
间断式地生成watermark。和周期性生成的方式不同,这种方式不是固定时间的,而是可以根据需要对每条数据进行筛选和处理。
class PunctuatedAssigner extends AssignerWithPunctuatedWatermarks[Item] { val bound: Long = 1 * 1000 override def checkAndGetNextWatermark(r: Item, extractedTS: Long): Watermark = { //触发watermark的条件为id if (r.id == "item_1") { new Watermark(extractedTS - bound) } else { null } } override def extractTimestamp(r: Item, previousTS: Long): Long = { r.timestamp * 1000 } }
四、ProcessFunction(底层API)
我们之前了解到的转换算子是无法访问事件的时间戳信息和水位线信息的。而这在一些应用场景下,极为重要。 例如 MapFunction 这样的 map 转换算子就无法访问时间戳或者当前事件的事件时间。
Process Function 用来构建事件驱动的应用以及实现自定义的业务逻辑 (使用之前的 window 函数和转换算子无法实现)。 例如,Flink SQL 就是使用 Process Function 实现的。
ProcessFunction
KeyedProcessFunction
CoProcessFunction
ProcessJoinFunction
BroadcastProcessFunction
KeyedBroadcastProcessFunction
ProcessWindowFunction
ProcessAllWindowFunction
1,KeyedProcessFunction
KeyedProcessFunction用来操作KeyedStream。KeyedProcessFunction 会处理流的每一个元素,输出为0个、1个或者多个元素。所有的Process Function都继承自RichFunction接口,所以都有open()、close()和getRuntimeContext()等方法。而KeyedProcessFunction[KEY, IN, OUT]还额外提供了两个方法 :
- processElement(v: IN, ctx: Context, out: Collector[OUT]), 流中的每一个元素都会调用这个方法,调用结果将会放在Collector数据类型中输出。Context可以访问元素的时间戳,元素的key,以及TimerService时间服务。Context还可以将结果输出到别的流(side outputs)。
- onTimer(timestamp: Long, ctx: OnTimerContext, out: Collector[OUT]) 是一个回调函数。当之前注册的定时器触发时调用。参数timestamp为定时器所设定的触发的时间戳。Collector 为输出结果的集合。OnTimerContext 和 processElement 的 Context 参数一样,提供了上下文的一些信息,例如定时器触发的时间信息(事件时间或者处理时间)。
2,TimerService和定时器(Timers)
Context 和 OnTimerContext 所持有的 TimerService 对象拥有以下方法:
currentProcessingTime(): Long 返回当前处理时间 currentWatermark(): Long 返回当前 watermark 的时间戳 registerProcessingTimeTimer(timestamp: Long): Unit 会注册当前 key 的 processing time 的定时器。 当 processing time 到达定时时间时,触发 timer。 registerEventTimeTimer(timestamp: Long): Unit 会注册当前 key 的 event time定时器。当水位线大于等于定时器注册的时间时,触发定时器执行回调函数。 deleteProcessingTimeTimer(timestamp: Long): Unit 删除之前注册处理时间定时器。如果没有这个时间戳的定时器,则不执行。 deleteEventTimeTimer(timestamp: Long): Unit 删除之前注册的事件时间定时器,如果没有此时间戳的定时器,则不执行。 当定时器 timer 触发时,会执行回调函数 onTimer()。注意定时器 timer 只能在 keyed streams 上面使用。
需求:监控item的评分,如果评分值在3s之内(processing time)连续上升,则报喜。
object KeyProcessFunctionDemo01 { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1) val stream = env .socketTextStream("localhost", 7777) .map { item => val arr: Array[String] = item.split(",") Item(arr(0).trim, arr(1).trim.toLong, arr(2).trim.toDouble) } .keyBy(_.id) .process(new MyKeyedProcess) stream.print() env.execute() } } //需求:监控item的評分,如果评分值在3s之内(processing time)连续上升,则报喜。 class MyKeyedProcess extends KeyedProcessFunction[String,Item,String]{ //保存定时器的时间戳 lazy val lastTime = getRuntimeContext.getState(new ValueStateDescriptor[Long]("time",Types.of[Long])) //保存上次的评分 lazy val lastRate = getRuntimeContext.getState(new ValueStateDescriptor[Double]("rate",Types.of[Double])) override def processElement(i: Item, context: KeyedProcessFunction[String, Item, String]#Context, collector: Collector[String]): Unit = { val time: Long = lastTime.value() val rate: Double = lastRate.value() val currentRate: Double = i.rate val currentTime: Long = context.timerService().currentProcessingTime() //当前时间 val nextTimer: Long = currentTime+3000 // println("定时器时间为:\t"+time) println("当前时间为:\t\t"+currentTime) if (rate != 0.0 && rate < currentRate && currentTime<time ) { //如果上一次评分不为0(不是第一次进入) 并且 本次评分大于上次评分 并且当前时间在定时器时间之内 context.timerService().registerProcessingTimeTimer(nextTimer) } lastTime.update(nextTimer) lastRate.update(currentRate) } //定时回调 override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[String, Item, String]#OnTimerContext, out: Collector[String]): Unit = { out.collect("当前key:\t"+ctx.getCurrentKey+"\t报喜") //输出报喜信息 } } case class Item(id:String, timestap:Long, rate:Double)
3,测输出流(SideOutput)
process function 的side outputs功能可以产生多条流,并且这些流的数据类型可以不一样。一个side output 可以定义为OutputTag[X]对象,X 是输出流的数据类型。process function可以通过Context对象发射一个事件到一个或者多个side outputs。
val outPutDStream:DataStream[Item] = sourceDStream.process(new MySideOutputProcess) val lowDStream:DataStream[Item] = outPutDStream.getSideOutput(new OutputTag[Item]("low")) val highDStream:DataStream[Item] = outPutDStream.getSideOutput(new OutputTag[Item]("high")) lowDStream.print("low") highDStream.print("high")
//按照item的评分30为分界线,大于30输出high的item,小于0输出low的item class MySideOutputProcess extends ProcessFunction[Item,Item]{ //为数据打标 lazy val lowOutput = new OutputTag[Item]("low") lazy val highOutput = new OutputTag[Item]("high") //处理每条输入数据 override def processElement(value: Item, ctx: ProcessFunction[Item, Item]#Context, out: Collector[Item]): Unit = { if (value.rate < 30.0) { ctx.output(lowOutput,value) }else{ ctx.output(highOutput,value) } } }