C#、Java实现按字节截取字符串,字符串中包含中文汉字和英文字符数字标点符号等。
在实际项目应用过程中,尤其是在web开发时可能遇到的比较多,就以我的(JiYF笨小孩管理系统)为例,再发布文章时候,文章摘要如果用户没有填写,默认截取文章前面255个字节,这个时候里面难免包含中文汉字,英文字母,标点符号等等有可能就会遇到截取出半个汉字的情况。
以Unicode 16(UCS2)编码为例,每一个字符占用俩个字节
假如字符串s:
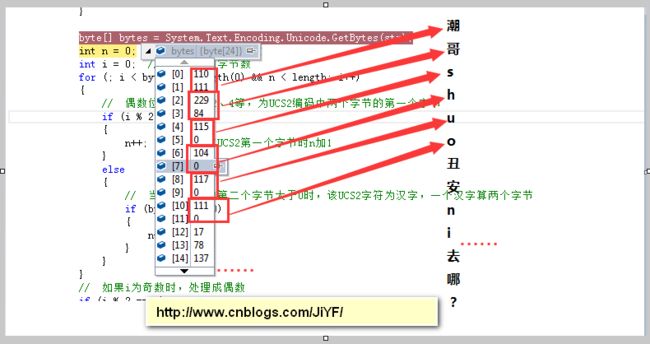
String s = "潮哥shuo丑安ni去哪?";
上面的s字符串既有汉字,又有英文字符和数字
举例:
如果要截取前6个字节的字符,应该是”潮哥sh",但如果用substring方法截取前6个字符就成了"潮哥shuo"。
如果截取9个字节,应该是“潮哥shuo” 丑的半个汉字就去掉了,但如果用substring方法截取前9个字符就成了"潮哥shuo丑安n"。
产生这个问题的原因是将substring方法将双字节的汉字当成一个字节的字符(UCS2字符)处理了。 要解决这个问题的方法是首先得到该字符串的UCS2编码的字节数组,如下面的代码如下:
C#代码示例:
1 private static string cutSubstring(string str, int length) 2 { 3 if (str == null || str.Length == 0 || length < 0) 4 { 5 return ""; 6 } 7 8 byte[] bytes = System.Text.Encoding.Unicode.GetBytes(str); 9 int n = 0; // 表示当前的字节数 10 int i = 0; // 要截取的字节数 11 for (; i < bytes.GetLength(0) && n < length; i++) 12 { 13 // 偶数位置,如0、2、4等,为UCS2编码中两个字节的第一个字节 14 if (i % 2 == 0) 15 { 16 n++; // 在UCS2第一个字节时n加1 17 } 18 else 19 { 20 // 当UCS2编码的第二个字节大于0时,该UCS2字符为汉字,一个汉字算两个字节 21 if (bytes[i] > 0) 22 { 23 n++; 24 } 25 } 26 } 27 // 如果i为奇数时,处理成偶数 28 if (i % 2 == 1) 29 { 30 // 该UCS2字符是汉字时,去掉这个截一半的汉字 31 if (bytes[i] > 0) 32 i = i - 1; 33 // 该UCS2字符是字母或数字,则保留该字符 34 else 35 i = i + 1; 36 } 37 return System.Text.Encoding.Unicode.GetString(bytes, 0, i); 38 }
分析:
测试结果:
调用
cutSubstring("潮哥shuo丑安ni去哪?",6);------>运行结果:“潮哥sh”
cutSubstring("潮哥shuo丑安ni去哪?",9);------>运行结果:“潮哥shuo”
Java代码示例:
(细心的童鞋会发现i值不同,java是从2开始C#从0开始,这里注意,java转换为字节数组,前俩个字节是标志位,所以第0位和第1位是标志位,从2开始)
1 public static String bSubstring(String s, int length) throws Exception 2 { 3 4 byte[] bytes = s.getBytes("Unicode"); 5 int n = 0; // 表示当前的字节数 6 int i = 2; // 要截取的字节数,从第3个字节开始 7 for (; i < bytes.length && n < length; i++) 8 { 9 // 奇数位置,如3、5、7等,为UCS2编码中两个字节的第二个字节 10 if (i % 2 == 1) 11 { 12 n++; // 在UCS2第二个字节时n加1 13 } 14 else 15 { 16 // 当UCS2编码的第一个字节不等于0时,该UCS2字符为汉字,一个汉字算两个字节 17 if (bytes[i] != 0) 18 { 19 n++; 20 } 21 } 22 } 23 // 如果i为奇数时,处理成偶数 24 if (i % 2 == 1) 25 26 { 27 // 该UCS2字符是汉字时,去掉这个截一半的汉字 28 if (bytes[i - 1] != 0) 29 i = i - 1; 30 // 该UCS2字符是字母或数字,则保留该字符 31 else 32 i = i + 1; 33 } 34 35 return new String(bytes, 0, i, "Unicode"); 36 }
测试结果:
调用
cutSubstring("潮哥shuo丑安ni去哪?",6);------>运行结果:“潮哥sh”
cutSubstring("潮哥shuo丑安ni去哪?",9);------>运行结果:“潮哥shuo”