【Python爬虫】爬取大众点评团购详情及团购评论
1 项目简介
从大众点评网收集北京市所有美发、健身类目的团购详情以及团购评论,保存为本地txt文件。
技术:Requests+BeautifulSoup
以美发为例:http://t.dianping.com/list/beijing?q=美发
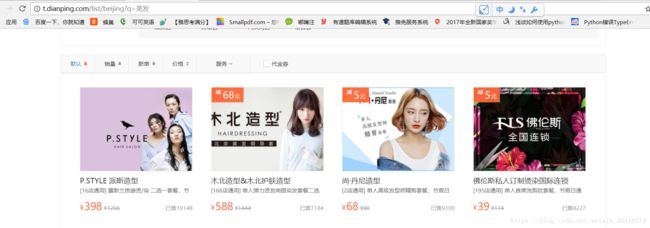
爬取内容包括:
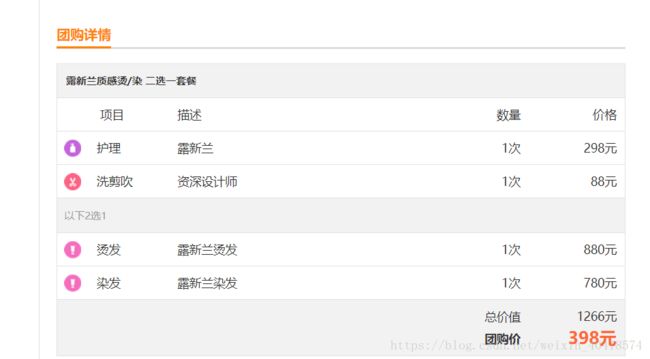
【团购详情】团购名称、原价(最高价)、团购价、销量,团购里包含的各个项目的名称、单价。
【团购评论】包括评论用户名称、评论星级、评论时间、评论内容。

2 程序结构
- 从大众点评团购页面获取所有“美发”、“健身”团购项目id的列表;
- 根据团购项目列表逐个获取每个项目的团购详情、团购评论;
- 存储数据到本地文件。
3 爬取前准备工作(以美发为例)
爬取前需要提前查看所要爬取信息的位置—是静态存储在html页面还是通过JavaScript动态生成?
查看方法
在想要爬取页面右键点击“查看网页源代码”,在源代码如果能搜索到即为静态存储在html页面,否则为通过JavaScript动态生成。
经过检查,团购项目id、团购详情静态存储在html中,团购评价为JavaScript动态生成。
3.1 获取团购项目id列表、团购详情
获取所有团购项目id列表:http://t.dianping.com/list/beijing?q=美发
获取id为“6009460”团购详情:http://t.dianping.com/deal/6009460
3.2 获取团购评价
由于团购评价信息由js动态生成,不存在源代码中,需要动态加载页面。
解决方案
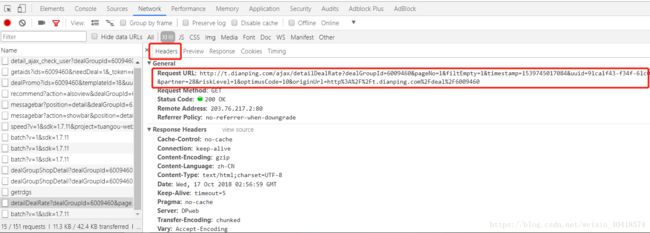
- 在团购评价所在页面点击F12,依次点击Network和XHR打开如下界面;
- 向下滑动页面,直至页面全部加载出评论信息;
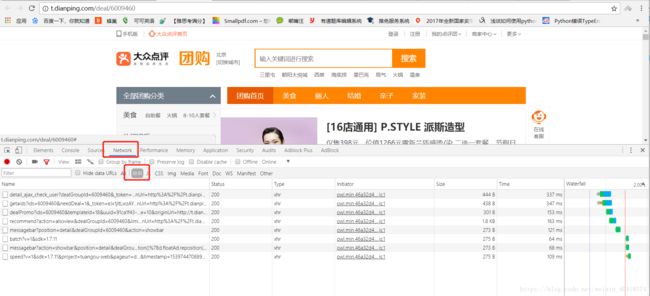
- 找到下图中框选的“detailDealRate?..”点击打开;
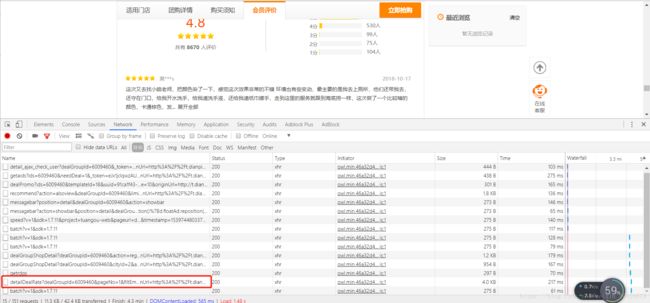
- 在Response中即可看到团购评价的源代码;

- 点击Headers获取评论信息的URL
3.3 实现爬取过程中的自动翻页
【团购项目列表页面】
第一页URL:http://t.dianping.com/list/beijing?q=美发
第二页URL:http://t.dianping.com/list/beijing?q=美发&pageIndex=1
第三页URL:http://t.dianping.com/list/beijing?q=美发&pageIndex=2
尝试将第一页URL改成:http://t.dianping.com/list/beijing?q=美发&pageIndex=0 与原来打开页面一样
【团购评价页面】
第一页URL:http://t.dianping.com/ajax/detailDealRate?dealGroupId=6009460&pageNo=1
第二页URL:http://t.dianping.com/ajax/detailDealRate?dealGroupId=6009460&pageNo=2
找到规律了吧,翻页时只需修改url中页码即可,不同页面规律不同。
3.4 应对反爬技术
现在大部分网站都对爬虫进行了限制,服务器允许人类访问,不允许“机器”访问,所以模仿人类的访问行为就可以解决这一问题。
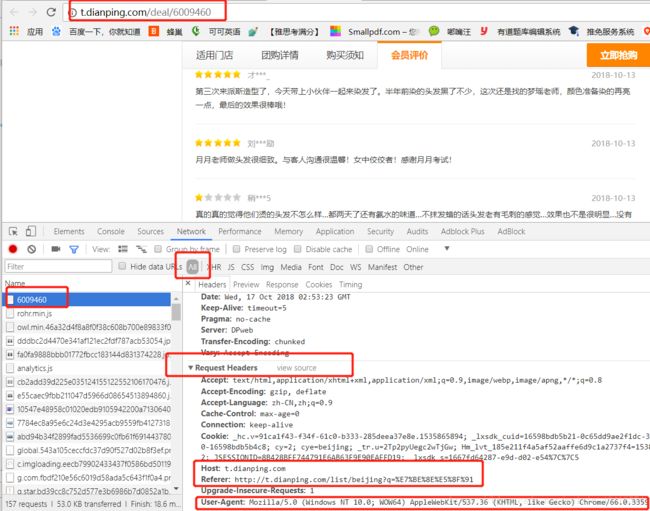
解决方法:加一个请求头完全模拟浏览器的请求,请求头获取见下图:
4 编写代码
4.1 引入所需要的库
import requests
import re
import os
import traceback
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
from urllib.parse import quote
4.2 获取单页面内容
def getHtmlText(url,refer):
#模拟浏览器头部信息应对反爬
headers = {
"User-Agent": UserAgent(verify_ssl=False).random,
"Host":"t.dianping.com",
"Referer":refer
}
try:
r=requests.get(url,headers=headers)
r.raise_for_status()
if (r.encoding != "UTF-8"):
r.encoding = r.apparent_encoding
return r.text
except:
return ""
4.3 获取所有团购项目列表
def getDealList(list,url,refer):
html=getHtmlText(url,refer)
soup=BeautifulSoup(html,"html.parser")
for item in soup.find_all("li",attrs={"class":"tg-floor-item"}):
try:
deal_id=item.attrs["data-eval-config"]
list.append(re.findall(r'\d+',deal_id)[0])
except:
continue
4.4 获取团购详情
def getDealInfo(list,url,refer):
path="D://deal_info.txt"
headers=["团购id","团购名称","原价","团购价","销量","单项名称","单项数量","单项单价"]
for id in list[:3]: #数据太多,这里选前三条做demo
try:
info=[]
deal_url=url+id
html=getHtmlText(deal_url,refer)
soup=BeautifulSoup(html,"html.parser")
#爬取团购名称,原价,团购价,销量等信息
main_info=soup.find("div",attrs={"class":"setmeal-box J_setmeal-box"})
name=main_info.find("li")
data=eval(name.attrs["data-eval-config"])#将字符串转换成字典格式
info.append(id)#团购id
info.append(data["title"])#团购名称
info.append(data["marketPrice"])#原价
info.append(data["price"])#团购价
info.append(data["sold"])#销量
#爬取团购里包含的各个项目的名称、单价等信息
detail_info=soup.find("table",attrs={"class":"detail-table"})
head=detail_info.find("thead")
head_list=head.find_all("th")
value=detail_info.find("tbody")
value_list=value.find_all("td")
item_num = int(len(value_list) / 3 - 1) # 三个为一组减去最后一组价格组 num表示团购项目中单项的数量
for i in range(item_num):
for j in range(len(head_list)):
info.append(re.sub(r'[\r\n" "]', "", value_list[3 * i + j].text)) # 用正则表达式去除多余的\r\n和空格
saveInfo(info,path,headers)
except:
# 显示错误信息
traceback.print_exc()
continue
4.5 获取团购评论
def getComInfo(list,url,refer):
com_path="D://com_info.txt"
headers=["团购id", "用户名称", "评论星级", "评论时间", "评论内容"]
page=2 #爬取评论的页面数
#对每一个团购项目的评论
for id in list[:3]: #数据太多,这里选前三条做demo
#对每一页评论
for i in range(page):
com_url=url+id+"&pageNo="+str(i+1)
com_html = getHtmlText(com_url,refer+id)
com_soup = BeautifulSoup(com_html, "html.parser")
com_tag = com_soup.find_all("li", attrs={"class": "Fix"})
# 对每一条评论
for tag in com_tag:
try:
#存储每一条评论信息
com_info = []
star = tag.find("span", attrs={"class": "star-rating"})
com_info.append(id)#团购名称
com_info.append(tag.find("span", attrs={"class": "name"}).text)#用户名称
com_info.append(re.search(r'\d',str(star)).group(0))#评论星级
com_info.append(tag.find("span", attrs={"class": "date"}).text)#评论时间
cont=tag.find("div", attrs={"class": "J_brief_cont_full Hide"})
#如果评论有隐藏信息
if(cont):
com_info.append(re.sub(r'[\r\n]',"",cont.text))#评论内容
#无隐藏
else:
com_info.append(re.sub(r'[\r\n]',"",tag.find("div", attrs={"class": "J_brief_cont_full"}).text))#评论内容
saveInfo(com_info,com_path,headers)
except:
#显示错误信息
traceback.print_exc()
continue
4.5 保存信息到本地txt
def saveInfo(info, path,headers):
with open(path, "a", encoding="utf-8") as f:
#获取文件大小
file_size = os.path.getsize(path)
if file_size == 0:
# 表头
f.write(re.sub(r'[\[\]\']', "",str(headers))+ "\n")
f.write(re.sub(r'[\[\]\']', "",str(info)) + "\n")
5 运行结果
5.1 团购评论

5.2 团购详情(美发、健身各选择前三条做demo)

写在最后
本人刚学习爬虫不久,第一个自己写的项目做个总结~
如有不尽完善之处,还请各位大佬指出,一起交流,一起进步~~
转载记得标明出处哦~